


Оффлайн
- Регистрация
- 21.07.20
- Сообщения
- 40.408
- Реакции
- 1
- Репутация
- 0
С тех пор, как первая модель завершения кода
Исследовательский путь
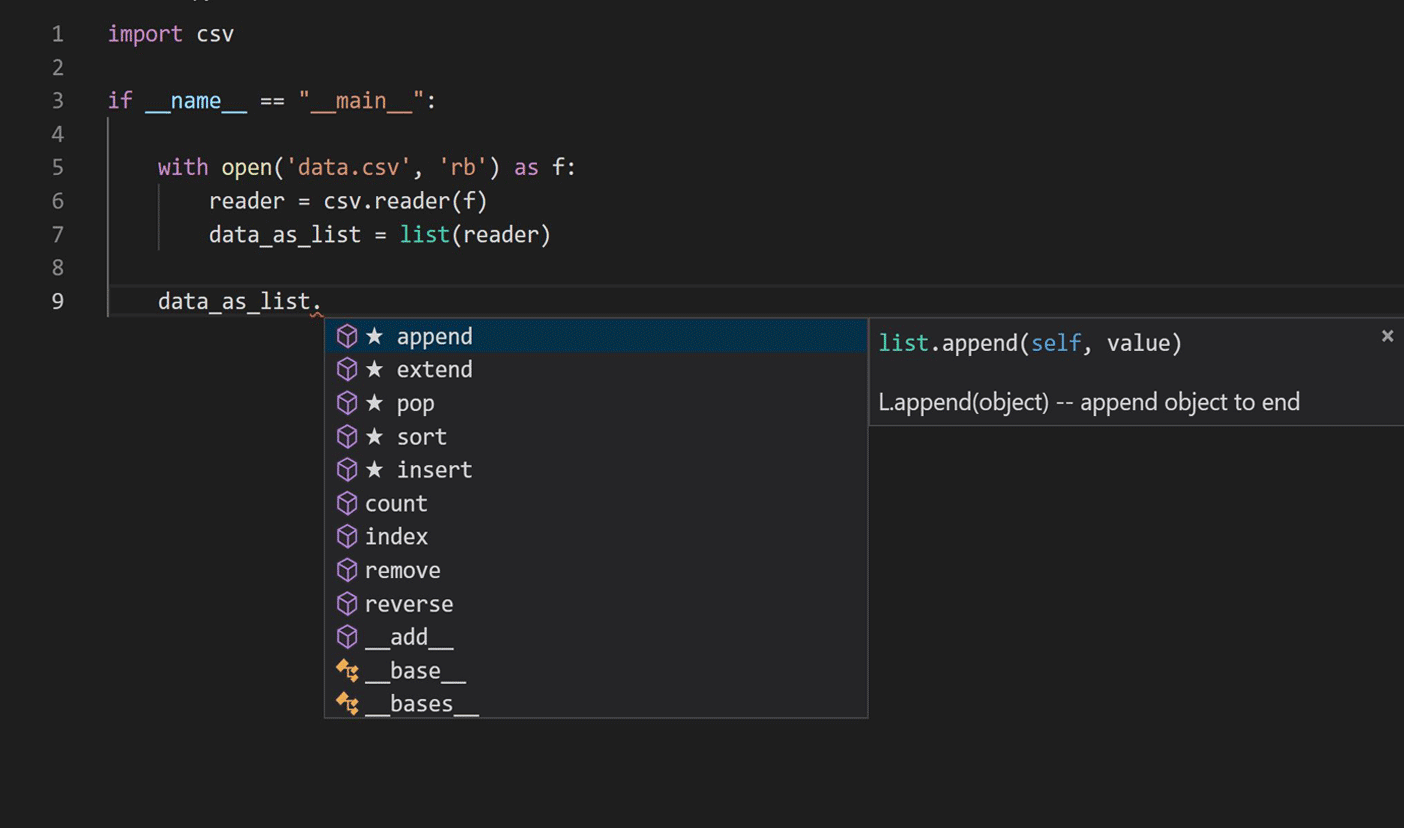
Путешествие началось с исследования в области применения методов языкового моделирования в обработке естественного языка для изучения кода Python. Мы сосредоточились на текущем сценарии завершения IntelliCode, как показано на рисунке ниже.

Основная задача — найти наиболее вероятный фрагмент (member) типа с учетом фрагмента кода, предшествующего вызову фрагмента (member-а). Другими словами, учитывая исходный фрагмент кода C, словарь V и набор всех возможных методов M ⊂ V, мы хотели бы определить:
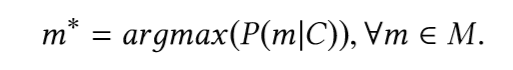
Чтобы найти этот фрагмент, нам нужно построить модель, способную предсказывать вероятность доступных фрагментов.
Предыдущие современные подходы на основе рекуррентных нейронных сетей (
Обучение глубоких нейронных сетей — это ресурсоемкая задача, требующая высокопроизводительных вычислительных кластеров. Мы использовали распределенную структуру обучения с параллельными данными

Мы выбрали производство с прогнозируемым внедрением из-за меньшего размера модели и повышения точности модели на 20% по сравнению с предыдущей производственной моделью во время автономной оценки модели; размер модели имеет решающее значение для развертывания в продакшене.
Архитектура модели показана на рисунке ниже:

Чтобы развернуть модель LSTM в проде, нам пришлось улучшить скорость вывода модели и объем памяти, чтобы удовлетворить требованиям завершения кода во время редактирования. Наш бюджет памяти составлял около 50 МБ, и нам нужно было поддерживать среднюю скорость вывода менее 50 миллисекунд. Модель IntelliCode LSTM была обучена с помощью TensorFlow, и мы выбрали ONNX Runtime для вывода, чтобы получить максимальную производительность. ONNX Runtime работает с популярными платформами глубокого обучения и упрощает интеграцию в различные обслуживающие среды, предоставляя API-интерфейсы, охватывающие множество языков, включая Python, C, C++, C#, Java и JavaScript — мы использовали API-интерфейсы C#, совместимые с .NET Core, чтобы интегрировать в
Квантование — это эффективный подход для уменьшения размера модели и повышения производительности, если допустимо падение точности, вызванное приближением чисел с малой разрядностью. С квантованием INT8 после обучения, обеспечиваемым ONNX Runtime, результирующее улучшение было значительным: объем памяти и время вывода были сокращены примерно до четверти предварительно квантованных значений по сравнению с исходной моделью с приемлемым сокращением на 3% точность модели. Вы можете найти подробную информацию о дизайне архитектуры модели, настройке гиперпараметров, точности и производительности в
Последним этапом выпуска в продакшн было проведение онлайн-экспериментов A/B, сравнивающих новую модель LSTM и предыдущую рабочую модель. Результаты онлайн-экспериментов A/B в таблице ниже показали примерно 25% улучшение точности рекомендаций первого уровня (точность первого рекомендованного элемента завершения в списке завершения) и 17% улучшение среднего обратного ранга (MRR), что убедило нас, что новая модель LSTM значительно лучше предыдущей модели.

Разработчики Python: попробуйте дополнения IntelliCode и отправьте нам свой отзыв!
Благодаря большим усилиям команды мы завершили поэтапное развертывание первой модели глубокого обучения для всех пользователей
You must be registered for see links
была представлена в Visual Studio и Visual Studio Code в 2018 году, она стала важным помощником по кодингу для миллионов разработчиков по всему миру. В последние два года мы постоянно работали над тем, чтобы адаптировать IntelliCode для большего количества языков программирования, а в то же время изучали способы повышения точности и покрытия модели, чтобы обеспечить еще большее удовлетворение пользователей. Одним из наших основных исследовательских усилий было привнести последние достижения в области глубокого обучения для моделирования естественного языка в моделирование языков программирования. После использования таких технологий, как
You must be registered for see links
и среда выполнения
You must be registered for see links
, мы успешно реализовали первую модель глубокого обучения для всех пользователей IntelliCode Python в Visual Studio Code.
Исследовательский путь
Путешествие началось с исследования в области применения методов языкового моделирования в обработке естественного языка для изучения кода Python. Мы сосредоточились на текущем сценарии завершения IntelliCode, как показано на рисунке ниже.
Основная задача — найти наиболее вероятный фрагмент (member) типа с учетом фрагмента кода, предшествующего вызову фрагмента (member-а). Другими словами, учитывая исходный фрагмент кода C, словарь V и набор всех возможных методов M ⊂ V, мы хотели бы определить:
Чтобы найти этот фрагмент, нам нужно построить модель, способную предсказывать вероятность доступных фрагментов.
Предыдущие современные подходы на основе рекуррентных нейронных сетей (
You must be registered for see links
) использовали только последовательную природу исходного кода, пытаясь передать методы естественного языка без использования уникальных характеристик синтаксиса языка программирования и семантики кода. Природа проблемы завершения кода сделала многообещающим кандидатом на использование сети с долговременной краткосрочной памятью (
You must be registered for see links
). Во время подготовки данных для обучения модели мы использовали частичное абстрактное синтаксическое дерево (AST), соответствующее фрагментам кода, содержащим выражения доступа к фрагментам (member) и вызовы функций модуля, с целью захвата семантики, переносимой удаленным кодом.Обучение глубоких нейронных сетей — это ресурсоемкая задача, требующая высокопроизводительных вычислительных кластеров. Мы использовали распределенную структуру обучения с параллельными данными
You must be registered for see links
с оптимизатором
You must be registered for see links
, сохраняя копию всей нейронной модели на каждом воркере, обрабатывая разные мини-пакеты обучающего набора данных параллельно. Мы использовали
You must be registered for see links
для обучения моделей и настройки гиперпараметров, поскольку его кластерная служба графического процессора по требованию упростила масштабирование нашего обучения по мере необходимости, а также помогла подготовить и управлять кластерами виртуальных машин, планировать задания, собирать результаты и обрабатывать неудачи. В таблице показаны модели архитектуры, которые мы опробовали, а также их соответствующая точность и размер модели.
Мы выбрали производство с прогнозируемым внедрением из-за меньшего размера модели и повышения точности модели на 20% по сравнению с предыдущей производственной моделью во время автономной оценки модели; размер модели имеет решающее значение для развертывания в продакшене.
Архитектура модели показана на рисунке ниже:
Чтобы развернуть модель LSTM в проде, нам пришлось улучшить скорость вывода модели и объем памяти, чтобы удовлетворить требованиям завершения кода во время редактирования. Наш бюджет памяти составлял около 50 МБ, и нам нужно было поддерживать среднюю скорость вывода менее 50 миллисекунд. Модель IntelliCode LSTM была обучена с помощью TensorFlow, и мы выбрали ONNX Runtime для вывода, чтобы получить максимальную производительность. ONNX Runtime работает с популярными платформами глубокого обучения и упрощает интеграцию в различные обслуживающие среды, предоставляя API-интерфейсы, охватывающие множество языков, включая Python, C, C++, C#, Java и JavaScript — мы использовали API-интерфейсы C#, совместимые с .NET Core, чтобы интегрировать в
You must be registered for see links
.Квантование — это эффективный подход для уменьшения размера модели и повышения производительности, если допустимо падение точности, вызванное приближением чисел с малой разрядностью. С квантованием INT8 после обучения, обеспечиваемым ONNX Runtime, результирующее улучшение было значительным: объем памяти и время вывода были сокращены примерно до четверти предварительно квантованных значений по сравнению с исходной моделью с приемлемым сокращением на 3% точность модели. Вы можете найти подробную информацию о дизайне архитектуры модели, настройке гиперпараметров, точности и производительности в
You must be registered for see links
, которую мы опубликовали на конференции KDD 2019.Последним этапом выпуска в продакшн было проведение онлайн-экспериментов A/B, сравнивающих новую модель LSTM и предыдущую рабочую модель. Результаты онлайн-экспериментов A/B в таблице ниже показали примерно 25% улучшение точности рекомендаций первого уровня (точность первого рекомендованного элемента завершения в списке завершения) и 17% улучшение среднего обратного ранга (MRR), что убедило нас, что новая модель LSTM значительно лучше предыдущей модели.
Разработчики Python: попробуйте дополнения IntelliCode и отправьте нам свой отзыв!
Благодаря большим усилиям команды мы завершили поэтапное развертывание первой модели глубокого обучения для всех пользователей
You must be registered for see links
. В последней версии расширения IntelliCode для Visual Studio Code мы также интегрировали среду выполнения ONNX и модель LSTM для работы с новым расширением
You must be registered for see links
, которое полностью написано на TypeScript. Если вы разработчик Python, установите расширение IntelliCode и поделитесь с нами своим мнением.