


Оффлайн
- Регистрация
- 21.07.20
- Сообщения
- 40.408
- Реакции
- 1
- Репутация
- 0
Исторически, модель работы сервера PostgreSQL выглядит как множество независимых процессов с частично разделяемой памятью. Каждый из них обслуживает только одно клиентское подключение и один запрос в любой момент времени — и никакой многопоточности.
Поэтому внутри каждого отдельного процесса нет никаких традиционных «странных» проблем с параллельным выполнением кода, блокировками,
Но эта же простота накладывает существенное ограничение. Раз внутри процесса всего один рабочий поток, то и использовать он может не более одного ядра CPU для выполнения запроса — а, значит, скорость работы сервера впрямую зависит от частоты и архитектуры отдельного ядра.
В наш век закончившейся «гонки мегагерцев» и победивших многоядерных и многопроцессорных систем такое поведение является непозволительной роскошью и расточительностью. Поэтому, начиная с версии PostgreSQL 9.6, при отработке запроса часть операций может выполняться несколькими процессами одновременно.
Вкратце хронология внедрения параллельного исполнения операций плана выглядит так:
Поэтому, если вы пользуетесь одной из последних версий PostgreSQL, шансы увидеть в плане Parallel ... весьма велики. А с ним приходят и…
Странности со временем
Возьмем план из PostgreSQL 9.6:
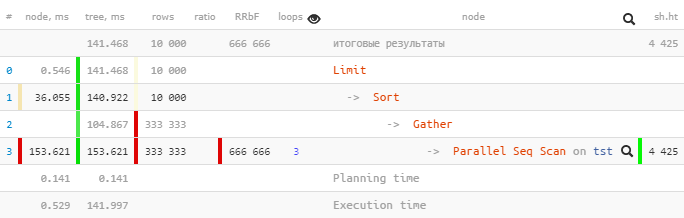
Только один Parallel Seq Scan выполнялся 153.621ms внутри поддерева, а Gather вместе со всеми подузлами — всего 104.867ms.
Как так? Суммарно времени «наверху» стало — меньше?..
Взглянем чуть подробнее на Gather-узел:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425
Workers Launched: 2 говорит нам о том, что дополнительно к основному процессу ниже по дереву были задействованы еще 2 дополнительных — итого 3. Поэтому все, что происходило внутри Gather-поддерева является суммарным творчеством всех 3 процессов сразу.
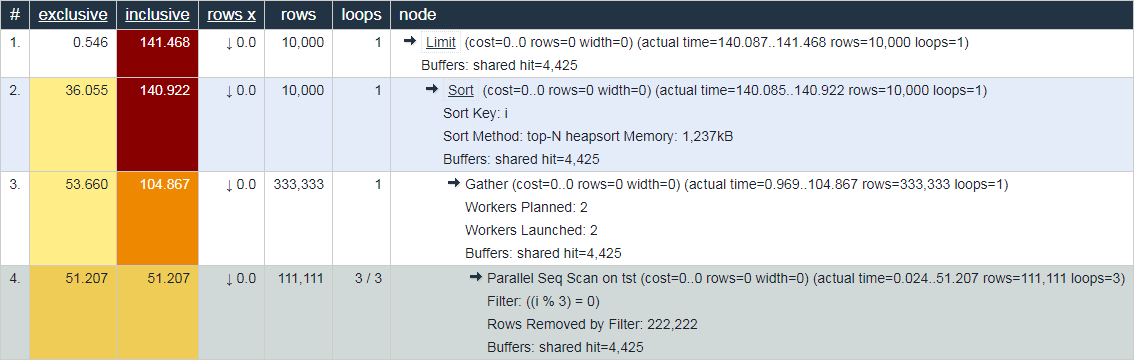
Теперь посмотрим, что там в Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Ага! loops=3 — это сводная информация по всем 3 процессам. И, в среднем, каждый такой цикл занял по 51.207ms. То есть суммарно для отработки этого узла серверу понадобилось 51.207 x 3 = 153.621 миллисекунды процессорного времени. То есть если мы хотим понять «чем был занят сервер» — именно это число и поможет нам понять.
В нашем примере каждый worker выполнил лишь один цикл по узлу, поэтому 153.621 / 3 = 51.207. И да, теперь уже нет ничего странного, что единственный Gather в головном процессе выполнился за «как бы меньшее время».
Итого: смотрите на
В этом смысле поведение того же
Не согласны? Добро пожаловать в комментарии!
Gather Merge теряет все
Теперь выполним тот же запрос на версии PostgreSQL 10:
Обратим внимание, что в плане у нас вместо узла Gather теперь оказался Gather Merge, а последовательное чтение таблицы превратилось в упорядоченное, по индексу, хоть и параллельное. Вот что говорит по этому поводу
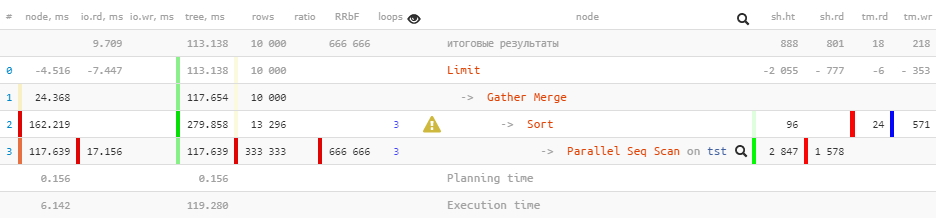
Но не все ладно в датском королевстве:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156
При передаче атрибутов Buffers и I/O Timings вверх по дереву часть данных была безвременно утрачена. Мы можем оценить размер этой потери как раз примерно в 2/3, которые формируются вспомогательными процессами.
Увы, в самом плане эту информацию взять неоткуда — отсюда и «минусы» на вышележащем узле. И если посмотреть дальнейшую эволюцию этого плана в PostgreSQL 12, то он принципиально не меняется, разве что добавляется немного статистики по каждому worker на Sort-узле:
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 ms
Итого: не доверяйте данным узла над Gather Merge.
Поэтому внутри каждого отдельного процесса нет никаких традиционных «странных» проблем с параллельным выполнением кода, блокировками,
You must be registered for see links
,… А разработка самой СУБД приятна и проста.Но эта же простота накладывает существенное ограничение. Раз внутри процесса всего один рабочий поток, то и использовать он может не более одного ядра CPU для выполнения запроса — а, значит, скорость работы сервера впрямую зависит от частоты и архитектуры отдельного ядра.
В наш век закончившейся «гонки мегагерцев» и победивших многоядерных и многопроцессорных систем такое поведение является непозволительной роскошью и расточительностью. Поэтому, начиная с версии PostgreSQL 9.6, при отработке запроса часть операций может выполняться несколькими процессами одновременно.
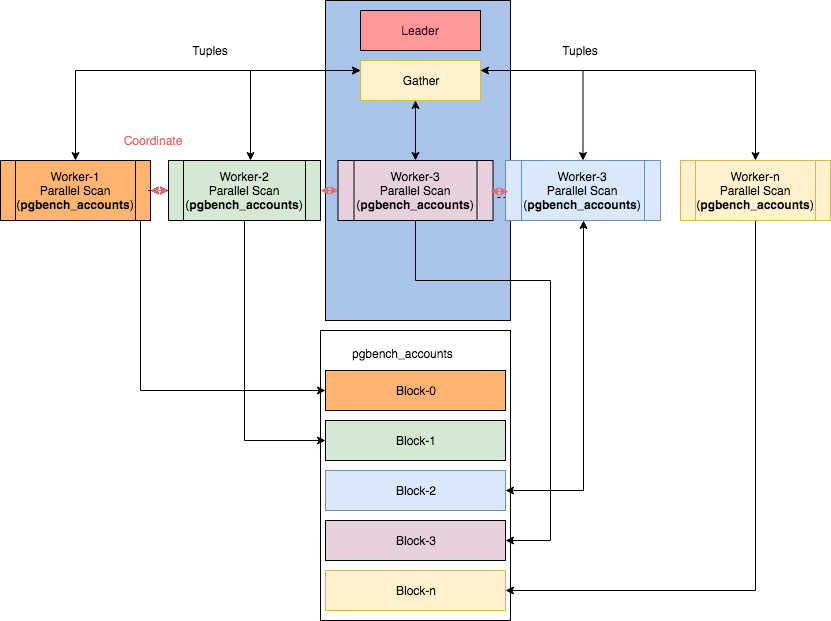
Со схемами работы некоторых параллельных узлов можно ознакомиться в статье
Правда, читать планы в этом случае становится… нетривиально.
You must be registered for see links
by Ibrar Ahmed, откуда взято и это изображение.Вкратце хронология внедрения параллельного исполнения операций плана выглядит так:
- 9.6 — базовый функционал:
You must be registered for see links,You must be registered for see links
- 10 — Index Scan (для btree), Bitmap Heap Scan, Hash Join, Merge Join, Subquery Scan
- 11 —
You must be registered for see links: Hash Join с общей хэш-таблицей, Append (UNION)
- 12 — базовая per-worker статистика на узлах плана
- 13 — детальная
You must be registered for see links
Поэтому, если вы пользуетесь одной из последних версий PostgreSQL, шансы увидеть в плане Parallel ... весьма велики. А с ним приходят и…
Странности со временем
Возьмем план из PostgreSQL 9.6:
You must be registered for see links
Только один Parallel Seq Scan выполнялся 153.621ms внутри поддерева, а Gather вместе со всеми подузлами — всего 104.867ms.
Как так? Суммарно времени «наверху» стало — меньше?..
Взглянем чуть подробнее на Gather-узел:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425
Workers Launched: 2 говорит нам о том, что дополнительно к основному процессу ниже по дереву были задействованы еще 2 дополнительных — итого 3. Поэтому все, что происходило внутри Gather-поддерева является суммарным творчеством всех 3 процессов сразу.
Теперь посмотрим, что там в Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Ага! loops=3 — это сводная информация по всем 3 процессам. И, в среднем, каждый такой цикл занял по 51.207ms. То есть суммарно для отработки этого узла серверу понадобилось 51.207 x 3 = 153.621 миллисекунды процессорного времени. То есть если мы хотим понять «чем был занят сервер» — именно это число и поможет нам понять.
Замечу, что для понимания «реального» времени выполнения надо суммарное время разделить на количество worker'ов — то есть [actual time] x [loops] / [Workers Launched].
В нашем примере каждый worker выполнил лишь один цикл по узлу, поэтому 153.621 / 3 = 51.207. И да, теперь уже нет ничего странного, что единственный Gather в головном процессе выполнился за «как бы меньшее время».
Итого: смотрите на
You must be registered for see links
суммарное (по всем процессам) время узла, чтобы понять, какой именно нагрузкой был занят ваш сервер, и оптимизации какой части запроса стоит уделять время.В этом смысле поведение того же
You must be registered for see links
, показывающего сразу «усредненное реальное» время, выглядит менее полезным для целей отладки:
Не согласны? Добро пожаловать в комментарии!
Gather Merge теряет все
Теперь выполним тот же запрос на версии PostgreSQL 10:
You must be registered for see links
Обратим внимание, что в плане у нас вместо узла Gather теперь оказался Gather Merge, а последовательное чтение таблицы превратилось в упорядоченное, по индексу, хоть и параллельное. Вот что говорит по этому поводу
You must be registered for see links
:Когда над параллельной частью плана оказывается узел Gather Merge, а не Gather, это означает, что все процессы, выполняющие части параллельного плана, выдают кортежи в отсортированном порядке, и что ведущий процесс выполняет слияние с сохранением порядка. Узел же Gather, напротив, получает кортежи от подчинённых процессов в произвольном удобном ему порядке, нарушая порядок сортировки, который мог существовать.
Но не все ладно в датском королевстве:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156
При передаче атрибутов Buffers и I/O Timings вверх по дереву часть данных была безвременно утрачена. Мы можем оценить размер этой потери как раз примерно в 2/3, которые формируются вспомогательными процессами.
Увы, в самом плане эту информацию взять неоткуда — отсюда и «минусы» на вышележащем узле. И если посмотреть дальнейшую эволюцию этого плана в PostgreSQL 12, то он принципиально не меняется, разве что добавляется немного статистики по каждому worker на Sort-узле:
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 ms
Итого: не доверяйте данным узла над Gather Merge.