


Оффлайн
- Регистрация
- 21.07.20
- Сообщения
- 40.408
- Реакции
- 1
- Репутация
- 0
У многих хоть раз возникала необходимость быстро нарисовать карту города или страны, нанеся на нее свои данные (точки, маршруты, тепловые карты и т.д.).
Как быстро решить такую задачу, откуда взять карту города или страны для отрисовки — в подробной инструкции под катом.
Введение
Недавно в работе возникла необходимость в отрисовке карты России на различных уровнях детальности (субъекты, города, городские районы) и подтягивании к ней ряда данных.
Грубо говоря, нужно было подготовить тепловую карту наподобие такой:
Плотность населения Москвы по районам

You must be registered for see links
Задача осложнялась тем фактом, что у нас не было подходящего файла с картой для визуализации, а данные, которые мы планировали отобразить, хранятся в привязке к почтовому коду (то есть, у нас нет привязки к субъекту федерации / городу / району).
В этой статье я поделюсь своим опытом касательно поиска подходящего источника данных, использования формата .shp и библиотеки geopandas.
Формирование подхода
Формально, решение задачи сводится к трем шагам:
- Поиск данных — карты России на разных уровнях детализации
- Мэтчинг данных с картой из шага "1"
- Проверка результатов, празднование
Ниже я опишу процесс выполнения каждого из этих шагов, поделюсь релевантным кодом, а также приведу ссылки на полезные ресурсы, которые встретились на моем пути.
Поиск
Формат файлов
Оптимальным для нашей задачи оказался формат Shapefile.
Не вдаваясь в подробности, Shapefile — это векторный формат, с помощью которого можно отобразить геометрические фигуры (например, районы города), а также привязать к ним ряд параметров для отображения (например, население в каждом районе).
Основные релевантные термины, которыми мы будем оперировать:
- Точка — Сочетание широты и долготы
- Линия — Последовательность из нескольких точек, соединенных между собой в фиксированном порядке
- Полигон — Замкнутая линия, у которой совпадают первая и последняя точка\
Подробнее про различные элементы можно почитать в замечательной
You must be registered for see links
.Источник данных
Источником данных был выбран OpenStreetMap (он же OSM). Это картографический сервис, наполняемый по принципу Википедии — желающие могут редактировать данные, добавлять недостающую информацию и так далее.
Быстрая проверка качества карт показала вполне адекватное отображение как крупных городов, так и мелких деревень и сел. Подробнее про качество данных и способы их наполнения можно почитать на
You must be registered for see links
.Чтобы выгрузить данные с OSM, мы воспользовались помощью специализированного агентства (как делать выгрузки самостоятельно, можно почитать
You must be registered for see links
).Мы выбрали
You must be registered for see links
, однако есть и
You must be registered for see links
агентства, чьей помощью можно воспользоваться для выгрузки и обработки данных.На NextGis можно за символическую плату подготовить
You must be registered for see links
(заняла ~30 минут) и за чуть менее символическую —
You must be registered for see links
(заняла ~4 дня). Также можно подготовить выгрузку по
You must be registered for see links
.Мэтчинг
Карта есть — теперь нужно понять, как выстроить связь между почтовыми кодами (к которым привязаны наши данные) и нужными нам уровнями детализации (город / район и тд).
Исходно была надежда на
You must be registered for see links
, однако оказалось, что наполнение его далеко от идеала (например, для почтового кода может быть указано, в каком городе он находится, но не в каком районе). К тому же в России, в отличие, например, от США, здания с одним и тем же почтовым кодом могут находиться в разных районах города, или даже в разных городах.В результате было решено опереться на все тот же OpenStreetMap. На одном из слоев карты представлены отдельные здания, у части из которых заполнено поле с почтовым кодом.
Если найти все дома с определенным почтовым кодом, а потом определить, в каком районе города находится большинство из них, можно определить, какой район является для данного индекса "основным".
Понятно, что такой подход имеет ряд ограничений. Например, могут найтись районы, в которых нет ни одного здания с заполненным индексом, могут быть ошибки при его написании и многие другие потенциальные косяки.
В то же время, в итоге выполнения этого упражнения мы увидели вполне удовлетворительные результаты (подробнее о них будет написано в разделе "Проверка").
В общем, проще показать, чем объяснить, так что переходим к делу!
Установка и импорт библиотек
Для всей нашей работы понадобится библиотека Geopandas, а также всем известные Pandas, Matplotlib и Numpy.
При установке Geopandas через pip на Windows выскакивает ошибка, так что рекомендую воспользоваться conda install geopandas .
import pandas as pd
import numpy as np
import geopandas as gpd
from matplotlib import pyplot as plt
Открываем Shapefile
Карты наши поставляются в виде zip архива.
При его открытии в папке data можно найти множество файлов с разными расширениями. Это различные слои, для каждого из которых есть основной файл (расширение .shp) и вспомогательные (расширения .cpg, .dbf, .prj, .shx).
Несколько моментов, на которые следует обратить внимание при начале работы с geopandas:
- Архив крайне эффективно ужимает карту. Например, архив с картой всей России весит 1.2GB, а при распаковке он занимает уже 22.8GB. Таким образом, не стоит распаковывать архив — лучше выгрузить из него нужные нам слои (благо geopandas позволяет это делать без использования дополнительных библиотек)
- Разные поля могут быть в разных кодировках. Например, в нашем примере административные границы были в кодировке 'cp1251', а остальные поля — в 'utf-8'
- При работе с несколькими слоями, взятыми из разных источников, могут возникнуть проблемы с их отображением из-за разных проекций карт. Подробнее об этой проблеме и способах ее решения можно почитать
You must be registered for see links.
# Путь к папке data в нашем архиве
# Обратите внимание на формат обращения к zip-архиву и к папке в нем
ZIP_PATH = 'zip://C:/Users/.../Moscow.zip!data/'
# Названия для переменных слоев и названия соответствующих shp Файлов
LAYERS_DICT = {
'boundary_L2': 'boundary-polygon-lvl2.shp', # Административные границы различных уровней
'boundary_L4': 'boundary-polygon-lvl4.shp',
'boundary_L5': 'boundary-polygon-lvl5.shp',
'boundary_L8': 'boundary-polygon-lvl8.shp',
'building_point': 'building-point.shp', # Здания, отмеченные в виде полигонов
'building_poly': 'building-polygon.shp' # Здания, отмеченные в виде точек
}
# Подгружаем слои в соответствующие переменные в рамках цикла
i = 0
for layer in LAYERS_DICT.keys():
path_to_layer = ZIP_PATH + LAYERS_DICT[layer]
if path_to_layer=='areas':
encoding = 'cp1251'
else:
encoding = 'utf-8'
globals()[layer] = gpd.read_file(path_to_layer, encoding=encoding)
i+=1
print(f'[{i}/{len(LAYERS_DICT)}] LOADED {layer} WITH ENCODING {encoding}')
Результат:
[1/6] LOADED boundary_L2 WITH ENCODING utf-8
[2/6] LOADED boundary_L4 WITH ENCODING utf-8
[3/6] LOADED boundary_L5 WITH ENCODING utf-8
[4/6] LOADED boundary_L8 WITH ENCODING utf-8
[5/6] LOADED building_point WITH ENCODING utf-8
[6/6] LOADED building_poly WITH ENCODING utf-8
В результате мы имеем шесть переменных GeoDataFrame, в каждой из которых находятся разные варианты отображения карты Москвы. Отрисовать их можно очень просто:
Рисуем административные границы разных уровней
Результат:
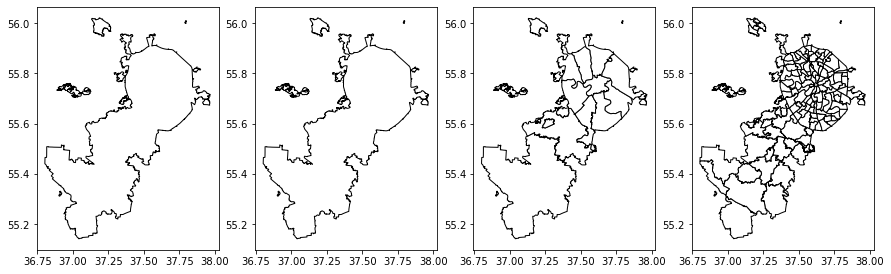
Чтобы разобраться, что именно мы видим на каждом уровне отрисовки, советую взглянуть на
You must be registered for see links
на сайте OSM. Это будет особенно важно при отрисовке карты всей России — слои в Москве и Питере могут хранить отличные от остальной России уровни детализации.Аналогичным образом можем отрисовать слой со зданиями. Из-за большого количества объектов отрисовка займет чуть больше времени, зато и картинка получится красивая.
Рисуем здания Москвы
building_poly.plot(figsize=(10,10))

Также можно наложить несколько слоев карты один на другой:
Отображаем одновременно два слоя административных границ Москвы
base = boundary_L2.plot(color='white', alpha=.8, edgecolor='black', figsize=(50,50))
boundary_L8.plot(ax=base, color='white', edgecolor='red', zorder=-1)
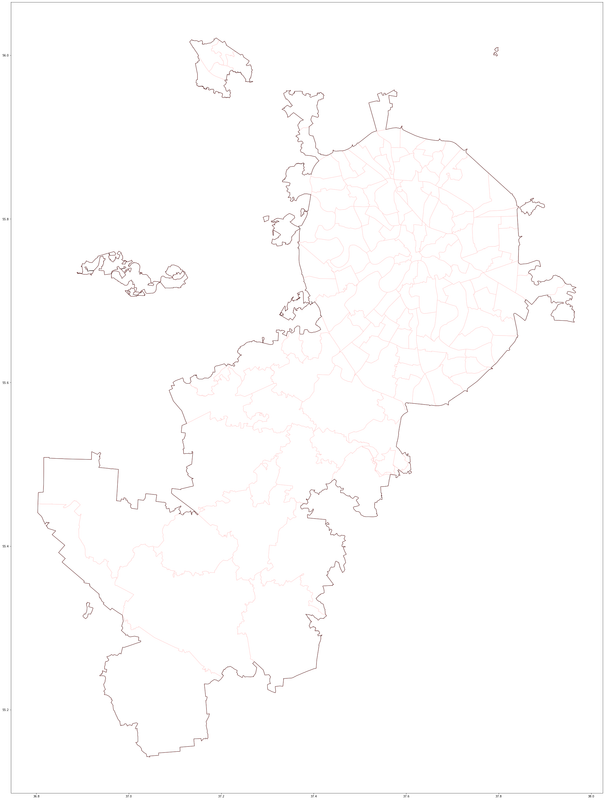
You must be registered for see links
можно почитать про разные варианты отрисовки слоев в gpd.Приятно удивило, что в Geopandas работают привычные команды из Pandas. Можно посмотреть все атрибуты слоя в виде таблицы, где каждая строка будет описывать отдельный объект (точку, линию или полигон), изменение и создание атрибутов также можно выполнять, как при работе с обычным Датафреймом.
Пример
boundary_L8.head()

Среди всех атрибутов нам наиболее важны 2:
- OSM_ID — уникальный идентификатор объекта OpenStreetMap
- geometry — координаты для отрисовки полигона или точки
Обработка данных
Для нашей задачи нам необходимо соотнести между собой почтовые индексы зданий и районы города.
Чтобы не обрабатывать лишних зданий, оставим только те из них, у которых заполнено поле с индексом:
print('POLYGONS')
print('# buildings total', building_poly.shape[0])
building_poly = building_poly.loc[building_poly['A_PSTCD'].notna()]
print('# buildings with postcodes', building_poly.shape[0])
print('\nPOINTS')
print('# buildings total', building_point.shape[0])
building_point = building_point.loc[building_point['A_PSTCD'].notna()]
print('# buildings with postcodes', building_point.shape[0])
Результат:
POLYGONS
# buildings total 241511
# buildings with postcodes 13198
POINTS
# buildings total 1253
# buildings with postcodes 4
Как видим, на слое с точками почти не осталось зданий, поэтому дальше будем использовать только слой с полигонами зданий (несмотря на то, что в нем это поле оказалось заполнено только у 5%, 13 тысяч нам должно хватить).
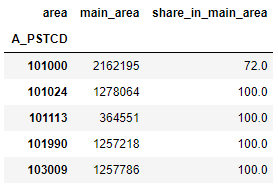
В целевой таблице мы хотим увидеть следующие колонки:
- Почтовый индекс
- OSM-ID района города, в котором чаще всего встречаются здания с этим индексом
- Доля зданий с этим индексом, которые находятся в его "основном" районе. Эта метрика нужна, чтобы проверить, не слишком ли разбросаны по городу здания с этим почтовым кодом.
Код для создания такой таблицы
%%time
building_areas = gpd.GeoDataFrame(building_poly[['A_PSTCD', 'geometry']])
building_areas['area'] = 'NF'
# Создаем цикл из районов города, для каждого из которых определяем находящиеся в нем здания
# Для проверки нахождения здания в районе, мы будем преобразовывать полигон здания в точку с помощью .centroid.
# Это позволит избежать сложностей со зданиями, которые находятся на границе двух районов
for area in boundary_L8['OSM_ID']:
area_geo = boundary_L8.loc[boundary_L8['OSM_ID']==area, 'geometry'].iloc[0]
nf_buildings = building_areas['area']=='NF' # В каждом цикле проверяем только те здания, для которых еще не нашли района
building_areas.loc[nf_buildings, 'area'] = np.where(building_areas.loc[nf_buildings, 'geometry'].centroid.within(area_geo), area, 'NF')
# Создаем таблицу, где по строкам находятся индексы, а по колонкам - районы города.
# Число на пересечении строки и колонки показывает, сколько нашлось зданий с таким индесом.
codes_pivot = pd.pivot_table(building_areas,
index='A_PSTCD',
columns='area',
values='geometry',
aggfunc=np.count_nonzero)
# Добавляем колонку, в которой будет указан наиболее часто встречающийся район с нужным индексом
codes_pivot['main_area'] = codes_pivot.idxmax(axis=1)
# Добавляем колонку с долей зданий в "основном" для индекса районе
for pst_code in codes_pivot.index:
main_area = codes_pivot.loc[codes_pivot.index==pst_code, 'main_area']
share = codes_pivot.loc[codes_pivot.index==pst_code, main_area].iloc[0,0] / codes_pivot.loc[codes_pivot.index==pst_code].sum(axis=1)*100
codes_pivot.loc[codes_pivot.index==pst_code, 'share_in_main_area'] = int(share)
# Оставляем только нужные нам колонки
codes_pivot = codes_pivot.loc[:, ['main_area', 'share_in_main_area']].fillna(0)
Итоговая таблица выглядит следующим образом:
Рисуем тепловую карту
Поделиться данными, которые мне необходимо отобразить, я, к сожалению, не могу (не могу даже рассказать, что это за данные).
Чтобы все же нарисовать красивую тепловую карту я вместо этого постараюсь ответить на необычайно важный вопрос: в индексах каких районов можно встретить больше цифр "1".
# Создаем колонку с нашей супер-важной метрикой
codes_pivot['count_1'] = codes_pivot.index.str.count('1')
# Считаем средние значения для районов города
areas_pivot = pd.pivot_table(codes_pivot, index='main_area', values='count_1', aggfunc=np.mean)
areas_pivot.index = areas_pivot.index.astype('int64')
# Подтягиваем наши значения к слою с районами города
boundary_L8_w_count = boundary_L8.merge(areas_pivot, how='left', left_on='OSM_ID', right_index=True)
# Рисуем тепловую карту
boundary_L8_w_count.plot(column='count_1', legend=True, figsize=(10,10))
Результат:
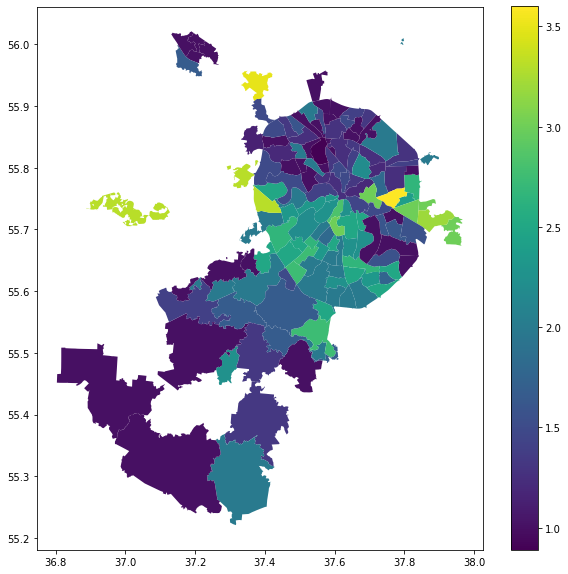
Видно, что часть районов не отобразилась — к сожалению, в них не было ни одного здания с заполненным почтовым индексом
Проверка
С точки зрения проверки качество результатов, основной риск заключался в том, что будет много почтовых индексов, разбросанных по разным районам города.
Ниже — распределение метрики share_in_main_area
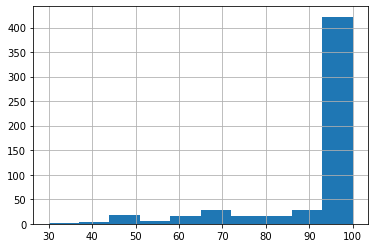
Считаем долю индексов, у которых меньше половины зданий находятся в "основном" для них районе:
codes_pivot[codes_pivot['share_in_main_area']>50].shape[0]/codes_pivot.shape[0]
Результат:
0.9568345323741008
Такие результаты нас вполне устраивают.
Заключение
Geopandas — крайне удобный инструмент. При наличие даже небольшого опыта работа с Matplotlib и Pandas разобраться в нем не составит труда.
OSM — кладезь информации для визуализации различных геоданных, которые можно использовать без необходимости серьезных преобразований.
Ну а я с вами прощаюсь и надеюсь, что статья оказалась полезной!
Если возникнут вопросы или конструктивная критика — буду ждать вас в комментариях.