


Оффлайн
- Регистрация
- 12.04.17
- Сообщения
- 19.095
- Реакции
- 107
- Репутация
- 0
Источник:
You must be registered for see links
Задача распознавания текста не теряет своей актуальности на протяжении последних десятилетий. А сейчас, в период повсеместного введения дистанционного оформления документов, не обойтись без процедуры идентификации личности.
Классическая процедура распознавания текста включает в себя его локализацию, сегментацию и непосредственно распознавание. Методы, использующие сегментацию текста на символы, довольно популярны и хорошо изучены. Однако существуют такие виды текста, где сегментация на символы становится настоящим испытанием. Например, арабская и индийская письменности. Кроме того, различные повреждения изображений текста также затрудняют его сегментацию. Очевидным решением при ограниченном множестве слов является распознавание их целиком, без разбора на символы. При условии наличия полного словаря с этой задачей отлично справляются обычные классифицирующие нейронные сети. Но что же делать в случае, если словарь достаточно большой или вовсе не известен на этапе обучения?
Для решения этой задачи мы предлагаем использовать метрические нейронные сети, они же энкодеры, они же кодировщики. В отличие от классифицирующих нейронных сетей, метрические в качестве ответа возвращают не набор оценок каждого элемента заранее заданного алфавита, а вектор-дескриптор. Иными словами, мы получаем координаты входного объекта в выходном пространстве.
Чтобы по ответу метрической сети определить, к какому из известных классов относится входной объект, его описание сравнивается с описаниями “эталонных” представителей классов, которые формируются после обучения. Тогда самый близкий по некоторой метрике (отсюда и пошло название) эталон и определит класс входного объекта.
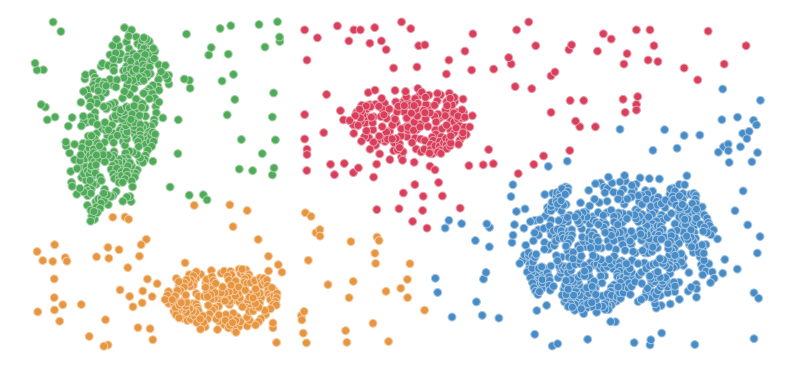
Большим преимуществом такого вида сетей, безусловно, является то, что пространство, которое мы получаем на выходе, дает большой простор для анализа. По расположению объектов можно судить о схожести классов между собой. Кроме этого, в отличие от обычных классифицирующих сетей, процедура добавления новых классов в словарь метрической сети не требует запуска обучения “с нуля”. Достаточно сформировать описания новых классов по нескольким их представителям с помощью обученной ранее сети.
В данной статье мы продемонстрируем применимость метрических сетей для задачи распознавания слов, а также приведем сравнение характеристик их работы с характеристиками работы классифицирующих ИНС.
Для обучения метрических сетей используется сиамская архитектура: пара ветвей с идентичными слоями и весами[1]. На последнем слое в такой архитектуре происходит сравнение векторов признаков, полученных от обеих ветвей. Как правило, на вход такой сети подается пара объектов, а также метка, которая обозначает принадлежность объектов к одному или к разным классам. Таким образом, после обучения точки выходного пространства, соответствующие объектам из одного класса, будут находиться ближе, чем точки, соответствующие объектам из разных классов.

Важно отметить, что такая архитектура используется лишь для обучения, непосредственно для распознавания применяется только одна ветвь: на вход приходит объект, а на выходе получается соответствующая ему точка в выходном пространстве.
Данные
Для того, чтобы определить, подходит ли метрическая сеть для распознавания целых слов, мы провели несколько экспериментов, сравнив характеристики работы метрической и классифицирующей сетей на примере распознавания поля “пол” в паспорте гражданина РФ. Здесь всего два класса: “М” и “Ж”, однако вариантов заполнения поля оказалось чуть больше — по 6 на каждый класс. В результате получился такой словарь:
МУЖ | МУЖ. | муж | муж. | Муж. | МУЖСКОЙ |
ЖЕН | ЖЕН. | жен | жен. | Жен. | ЖЕНСКИЙ |
Для наших экспериментов в качестве обучающих мы взяли данные, сгенерированные искусственно [2] по этому словарю. Каждое изображение содержало одно из слов и сопровождалось меткой номера варианта. Чтобы максимально приблизить данные к натуральным, полученным в неконтролируемых условиях съемки, мы применили к ним ряд искажений: смаз, гауссово размытие, проективные искажения. Всего получилось 285421 изображения, из них 142515 для женского пола и 142906 для мужского. На рисунке ниже можно увидеть примеры

Для обучения классифицирующей сети нам потребовалось сгруппировать обучающие данные по двум классам в соответствии с полом который они обозначают: по 6 вариантов на каждый. Метрическая же сеть должна уметь различать входные изображения, относящиеся к разным классам. Поэтому для ее обучения мы сформировали 1500024 пар изображений и пометили их в соответствии с тем, отражают ли они один и тот же вариант написания (“0”, если один вариант, “1” — разные).
В качестве тестовой выборки ввиду отсутствия в общем доступе изображений настоящих паспортов мы использовали сгенерированные синтетические данные, но с использованием дополнительных фонов, которые имитировали наличие подчеркиваний и статических текстов, характерных для настоящих изображений. Всего мы сгенерировали 10000 изображений, поровну каждого класса. Кроме этого, к этим изображениям были применены дополнительные раздутия, имитирующие искажения, возможные в случае получения изображения с малоразмерных цифровых камер и со сканеров.
Используемые модели обучения
Классифицирующая сеть
В качестве классифицирующей мы взяли глубокую сверточную сеть. На выходе у такой сети двухэлементный вектор с оценками вероятностей принадлежности входного объекта к итоговым классам. Функция ошибки классифицирующей сети рассчитывалась по формуле:

где M — размер алфавита сети, p[SUB]i[/SUB] — идеальная оценка i-ого класса, а e[SUB]i[/SUB] — оценка i-ого класса сетью.
Метрическая сеть
Исследуемая метрическая сеть переводит входные объекты в десятимерное пространство. Размерность выходного пространства была выбрана эмпирически.
Функция ошибки метрической сети:

где p-значение, указывающие на принадлежность входок одному и тому же классу, e — вектор разности выходных векторов ветвей, α — порог, начиная с которого увеличение расстояния между разными классами не уменьшает итоговую ошибку. Параметр α вводится для того, чтобы кластеры выходного пространства не оказались равноудаленными друг от друга, потому что в данной задаче этого не нужно, и более того, не обязательно возможно.
Эксперименты
В ходе первого этапа эксперимента было обучено две сети (метрическая и классифицирующая), решающих задачу распознавания поля “пол” на изображениях паспорта гражданина РФ. Архитектура классифицирующей сети представлена в таблице
| № слоя | Тип | Описание |
|---|---|---|
1 | Свёрточный | 4 фильтра 3х3, без отступов, шаг фильтра 1х1 |
2 | Свёрточный | 8 фильтров 5х5, отступ 2х2, шаг фильтра 2х2 |
3 | Свёрточный | 8 фильтров 3х3, отступ 1х1, шаг фильтра 1х1 |
4 | Свёрточный | 12 фильтров 5х5, отступ 2х2, шаг фильтра 2х2 |
5 | Свёрточный | 12 фильтров 3х3, отступ 1х1, шаг фильтра 1х1 |
6 | Свёрточный | 12 фильтров 3х3, отступ 1х1, шаг фильтра 1х1 |
7 | Полносвязный | � |
Такой же архитектурой обладала и каждая из ветвей сиамской сети. Видно, что при фиксированном размере алфавита, основным отличием сетей является лишь метод обучения, а вместе с ним — свойства ответа. По выходу классифицирующей сети нельзя сказать, как сильно отличаются классы исходного алфавита, в то время как это хорошо видно по кластерам выходного пространства метрической сети.
Вторым этапом мы решили облегчить архитектуры, сократив количество сверточных слоев и удвоив шаги фильтров на последнем слое (см. таблицу ниже).
| № слоя | Тип | Описание |
|---|---|---|
1 | Свёрточный | 4 фильтра 3х3, без отступов, шаг фильтра 1х1 |
2 | Свёрточный | 8 фильтров 5х5, отступ 2х2, шаг фильтра 2х2 |
3 | Свёрточный | 8 фильтров 3х3, отступ 1х1, шаг фильтра 2х2 |
4 | Полносвязный | � |
Так нам удалось с незначительными потерями в качестве уменьшить размер классифицирующей сети практически в 3 раза. Данные сети предполагается использовать в том числе и в мобильных приложениях, а это тот случай, когда размер имеет значение.
На основании тестовой выборки мы провели замеры качества распознавания обоих типов сетей с тяжелыми и легкими архитектурами. Под качеством подразумевается точность распознавания, т.е. отношение числа верно классифицированных объектов к объему тестовой выборки. Результаты замеров представлены в таблице
Тяжёлая архитектура | Лёгкая архитектура | |
Классифицирующая | 98.36% | 98.23% |
Метрическая | 98.05% | 97.86% |
Видно, что метрические сети показывают практически такое же качество распознавания, как и классифицирующие. При этом первые обладают рядом дополнительных свойств, которые позволяют применять их для более широкого класса задач, в частности, задач распознавания по неполному словарю.
Заключение
Сегодня нами было рассмотрено два вида сетей — обычные классифицирующие и метрические. Качество классификации у них практически одинаковое, но благодаря свойствам ответа метрические сети имеют много других преимуществ. Такие сети пригодны для распознавания слов даже в том случае, когда не весь словарь был представлен в обучающей выборке. В то время как классифицирующую сеть придется обучить заново для добавления новых классов, метрической достаточно показать несколько изображений новых элементов словаря, чтоб построить их описания. Кроме того, ответ метрической сети позволяет судить о сходстве различных классов исходя из позиций векторов-описаний объектов в результирующем пространстве.
Литература
- Koch G., Zemel R., Salakhutdinov R. Siamese Neural Networks for One-shot Image Recognition. Proceedings of the 32 International Conference on Machine Learning. 2015. V. 2. 8 p.
- Chernyshova Y., Gayer A., Sheshkus A. Generation method of synthetic training data for mobile OCR system. Proc. SPIE 10696, Tenth International Conference on Machine Vision (ICMV 2017). 2018. P. 1-7. DOI: 10.1117/12.2310119.