


Оффлайн
- Регистрация
- 12.04.17
- Сообщения
- 19.095
- Реакции
- 107
- Репутация
- 0

(изображение взято
You must be registered for see links
)Сегодня мы бы хотели вам рассказать о задаче пост-обработки результатов распознавания текстовых полей исходя из априорных знаний о поле. Ранее мы уже писали про
You must be registered for see links
, который позволяет исправлять некоторые ошибки распознавания слов, написанных на естественных языках. Однако значительную часть важных документов, в том числе документов, удостоверяющих личность, составляют поля другого характера – даты, номера, VIN-коды автомобилей, номера ИНН и СНИЛС,
You must be registered for see links
с их контрольными суммами и многое другое. Хотя их нельзя отнести к полям естественного языка, тем не менее у таких полей зачастую существует некоторая, иногда неявная, языковая модель, а значит, для них тоже можно применить некоторые алгоритмы коррекции. В этом посте речь пойдет об двух механизмах пост-обработки результатов распознавания, которые можно применять для большого количества документов и типов полей.Языковую модель поля можно условно подразделить на три составляющие:
- Синтаксис: правила, регулирующие структуру текстового представления поля. Пример: поле “дата окончания срока действия документа” в машинно-читаемой зоне представлятся в виде семи цифр “DDDDDDD”.
- Семантика поля: правила, основывающиеся на смысловой интерпретации поля или его составных частей. Пример: в поле “дата окончания срока действия документа” машинно-читаемой зоны первые две цифры – это последние две цифры года, 3-я и 4-я цифры – это месяц, 5-я и 6-я – это день, и 7-я цифра – контрольная сумма.
- Семантика связей: правила, основывающиеся на структурной и смысловой связи поля с другими полями документа. Пример: поле “дата окончания срока действия документа” не может кодировать дату, соответствующую более раннему моменту времени, чем поле “дата рождения”.
Располагая информацией о семантической и синтаксической структуре документа и распознаваемого поля, можно построить специализированный алгоритм пост-обработки результата распознавания. Однако, принимая во внимание необходимость поддержки и развития систем распознавания и сложность их разработки, интересно рассмотреть “универсальные” методы и инструменты, которые позволили бы с минимальными усилиями (со стороны разработчиков) построить достаточно хороший алгоритм пост-обработки, который бы работал с обширным классом документов и полей. Методика настройки и поддержки такого алгоритма была бы унифицирована, а изменяемым компонентом структуры алгоритма была бы только языковая модель.
Стоит отметить, что пост-процессинг результатов распознавания текстовых полей не всегда полезен, а иногда даже вреден: в случае, если у вас достаточно хороший модуль распознавания строки и вы работаете в критических системах с документами, удостоверяющими личность, то какой-либо пост-процессинг лучше минимизировать и выдавать результаты “так как есть”, либо четко контролировать любые изменения и сообщать о них клиенту. Однако во многих случаях, когда заведомо известно, что документ действительный, и что языковая модель поля надежна – использование алгоритмов пост-обработки позволяет значительно повысить итоговое качество распознавания.
Итак, в статье пойдет речь о двух методах пост-обработки, претендующих на универсальность. Первый основан на взвешенных конечных преобразователях, требует описания языковой модели в виде конечного автомата, не очень прост в использовании, но более универсален. Второй – более простой в использовании, более эффективен, требует всего лишь написания функции проверки валидности значения поля, но также обладает рядом недостатков.
Метод на основе взвешенных конечных преобразователей
Красивая и достаточно общая модель, позволяющая построить универсальный алгоритм пост-обработки результатов распознавания, описана
You must be registered for see links
. Модель опирается на структуру данных взвешенных конечных преобразователей (Weighted Finite-State Transducers, WFST).WFST представляют собой обобщение взвешенных конечных автоматов – если взвешенный конечный автомат кодирует некоторый взвешенный язык














Над WFST определяется операция композиции, на которую и опирается метод пост-обработки. Пусть заданы два преобразователя










Алгоритм пост-обработки результата распознавания на основе WFST опирается на три основных источника информации – модель гипотез



- Модель гипотез
представляет из себя взвешенный конечный автомат (частный случай WFST – каждая строка преобразуется сама в себя, вес преобразования совпадает с весом самой строки), принимающий гипотезы, видвинутые системой распознавания поля. К примеру, пусть результатом распознавания текстового поля является последовательность ячеек
, а каждая ячейка соответствует результату распознавания некоторого символа и представляет собой множество альтернатив и их оценок (весов):
 , где
, где –
– -й символ алфавита,
-й символ алфавита, – оценка (вес) этого символа. Тогда модель гипотез можно представить в виде конечного преобразователя с
– оценка (вес) этого символа. Тогда модель гипотез можно представить в виде конечного преобразователя с -м состоянием, уложенным в цепочку:
-м состоянием, уложенным в цепочку: -е состояние является начальным,
-е состояние является начальным, -е – терминальным, переходы осуществляются между
-е – терминальным, переходы осуществляются между -м и
-м и -м состояниями и соответствуют ячейке
-м состояниями и соответствуют ячейке . На
. На -м переходе входным и выходным символом является символ
, а вес перехода соответствует оценке данной альтернативы. Ниже на рисунке представлен пример модели гипотез, сооветствующей результату распознавания строки из трех символов.
-м переходе входным и выходным символом является символ
, а вес перехода соответствует оценке данной альтернативы. Ниже на рисунке представлен пример модели гипотез, сооветствующей результату распознавания строки из трех символов.
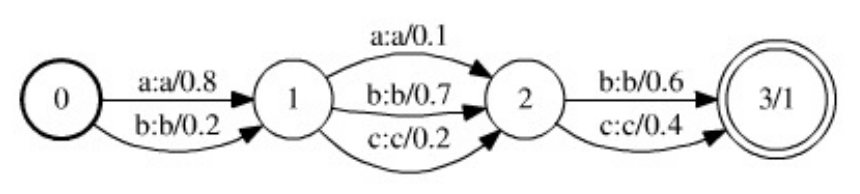
Рис. 1. Пример модели гипотез, представленной в виде WFST (рисунок изYou must be registered for see links). Переходы с нулевым весом опущены.
- Модель ошибок
является взвешенным конечным преобразователем, кодирующим всевозможные преобразования гипотез, которые можно производить для их приведения в соответствие языковой модели. В самом простом случае она может быть представлена в виде WFST с единственным состоянием (которое является и начальным и терминальным). Каждый переход кодирует некоторое изменение символа с соответствующим весом. К примеру, весом замены символа может являться оценка вероятности соответствующей ошибки алгоритма распознавания символа.
- Языковой моделью
является представление синтаксиса и семантики распознаваемого поля в виде взвешенного конечного автомата. Т.е. языковой моделью яляется автомат, принимающий все допустимые значения рассматриваемого поля (и выставляющий каждому допустимому значению некоторый вес).
После определения модели гипотез, ошибок и языковой модели задача пост-обработки результатов распознавания теперь может быть поставлена следующим образом: рассмотрим композицию всех трех моделей


Преимуществами данного подхода является его общность и гибкость. Модель ошибок, к примеру, может быть без труда расширена таким образом, чтобы учесть удаления и добавления символов (для этого всего лишь стоит добавить в модель ошибок переходы с пустым выходным или входным символом соответственно). Однако у такой модели есть и существенные недостатки. Во-первых, языковая модель здесь должна быть представлена в виде конечного взвешенного конечного преобразователя. Для сложных языков такой автомат может получиться довольно громоздким, и в случае изменения или уточнения языковой модели будет необходимо его перестроение. Также необходимо заметить, что композиция трех преобразователей в качестве результата имеет, как правило, еще более громоздкий преобразователь, а эта композиция вычисляется каждый раз при запуске пост-обработки одного результата распознавания. Ввиду громоздкости композиции, поиск оптимального пути на практике приходится выполнять эвристическими методами, такими как A*-search.
Метод на основе проверяющих грамматик
Используя модель проверяющих грамматики можно построить более простую модель задачи пост-обработки результатов распознавания, которая будет не насколько общей, как модель на основе WFST, однако легко расширяемой и простой в имплементации.
Проверяющей грамматикой будем называть пару









Пусть задан результат распознавания (модель гипотез) в виде последовательности ячеек




Любая задача дискретной оптимизации (т.е. с конечным множестве управлений) может быть решена при помощи полного перебора управлений. Описываемый алгоритм эффективно перебирает управления (строки) в порядке убывания значения функционала до того момента, пока предикат допустимости не примет истинного значения. Зададим как

Вначале проведем сортировку альтернатив по убыванию оценок, и будем далее считать что для любой ячейки





В процессе перечисления позиций мы будем выбирать непросмотренную позицию с максимальной оценкой, после чего добавлять в очередь на рассмотрение PositionQueue все позиции, которые можно получить из текущей добавлением единицы к одному из индексов, входящих в позицию. Очередь на рассмотрение PositionQueue будет содержать тройки




На первой итерации алгоритма необходимо рассмотреть позицию





FindSuitableString(M, N, K, P, C[1], ..., C[N]):
для каждого i : 1 ... N:
сортировка C по убыванию оценок альтернатив
(конец цикла)
инициализация PositionBase и PositionQueue
S_1 = {1, 1, 1, ..., 1}
если P(S_1):
ответ: S_1, алгоритм завершается
(конец условия)
добавление S_1 в PositionBase с адресом R(S_1)
для каждого i : 1 ... N:
если K > 1, то:
добавить тройку q[1], R(S_1), i> в PositionQueue
(конец условия)
(конец цикла)
пока количество позиций в PositionBase меньше M:
пока не пуста PositionQueue:
извлечь из PositionQueue тройку с максимальной Q
S_from = позиция в PositionBase по адресу R
S_curr = {S_from[1], S_from[2], ..., S_from + 1, ..., S_from[N]}
если S_curr содержится в PositionBase:
продолжаем цикл
иначе:
добавить S_curr в PositionBase с адресом R(S_curr)
(конец условия)
если P(S_curr):
ответ: S_curr, алгоритм завершается
(конец условия)
для каждого i : 1 ... N:
если K > S_curr:
добавить тройку q[S_curr],
R(S_curr),
i> в PositionQueue
(конец условия)
(конец цикла)
выход из внутреннего цикла
(конец цикла)
(конец цикла)
ответ не найден за M итераций
Заметим, что за



Пожалуй, самым важным недостатком алгоритма на основе проверяющих грамматик является то, что он не может обрабатывать гипотезы разной длины (которые могут возникнуть из-за ошибок
You must be registered for see links
: потеря или возникновение лишних символов, склейки и разрезания символов и т.п.), тогда как изменения гипотез вида “удаление символа”, “добавление символа”, или даже “замена символа парой” могут быть закодированы в модели ошибок алгоритма на основе WFST. Однако быстродействие и простота использования (при работе с новым типом поля нужно просто дать алгоритму доступ к функции валидации значения) делают метод на основе проверяющих грамматик очень мощным инструментом в арсенале разработчика систем распознавания документов. Мы используем данный подход для большого количества разнообразных полей, таких как всевозможные даты, номер банковской карты (предикат – проверка
You must be registered for see links
), поля машинно-читаемых зон документов с контрольными суммами, и многих других. –
Публикация подготовлена на основе
You must be registered for see links
: Универсальный алгоритм пост-обработки результатов распознавания на основе проверяющих грамматик. K.Б. Булатов, Д.П. Николаев, В.В. Постников. Труды ИСА РАН, Т. 65, № 4, 2015, стр. 68-73.