
Оффлайн
- Регистрация
- 23.09.18
- Сообщения
- 12.347
- Реакции
- 176
- Репутация
- 0
Несколько месяцев назад
За прошедшее время вы уже воспользовались им более 6000 раз, но одна из удобных функций могла остаться незамеченной — это структурные подсказки, которые выглядят примерно так:

Прислушивайтесь к ним, и ваши запросы «станут гладкими и шелковистыми».")
А если серьезно, то многие ситуации, которые делают запрос медленным и «прожорливым» по ресурсам, типичны и могут быть распознаны по структуре и данным плана.
В этом случае каждому отдельному разработчику не придется искать вариант оптимизации самостоятельно, опираясь исключительно на свой опыт — мы можем ему подсказать, что тут происходит, в чем может быть причина, и как можно подойти к решению. Что мы и сделали.

Давайте чуть подробнее рассмотрим эти кейсы — как они определяются и к каким рекомендациям приводят.
Для лучшего погружения в тему сначала можно послушать соответствующий блок из
#1: индексная «недосортировка»
Когда возникает
Показать последний счет по клиенту «ООО Колокольчик».
Как опознать
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
Рекомендации
Используемый индекс расширить полями сортировки.
Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
fk_cli = 1 -- отбор по конкретной связи
ORDER BY
pk DESC -- хотим всего одну "последнюю" запись
LIMIT 1;
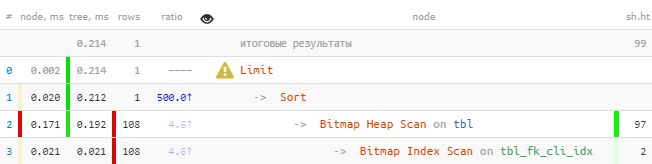
Сразу можно заметить, что по индексу вычиталось больше 100 записей, которые потом все сортировались, а потом была оставлена единственная.
Исправляем:
DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC); -- добавили ключ сортировки

Даже на такой примитивной выборке — в 8.5 раз быстрее и в 33 раза меньше чтений. Эффект будет тем нагляднее, чем больше у вас «фактов» по каждому значению fk.
Замечу, что такой индекс будет работать как «префиксный» не хуже прежнего и по другим запросам с fk, где сортировки по pk не было и нет (подробнее про это можно прочитать
#2: пересечение индексов (BitmapAnd)
Когда возникает
Показать все договоры по клиенту «ООО Колокольчик», заключенные от имени «НАО Лютик».
Как опознать
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan
Рекомендации
Создать составной индекс по полям из обоих исходных или расширить один из существующих полями из второго.
Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org); -- индекс для foreign key
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999); -- отбор по конкретной паре

Исправляем:
DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);

Тут выигрыш меньше, поскольку Bitmap Heap Scan достаточно эффективен сам по себе. Но все-таки в 7 раз быстрее и в 2.5 раза меньше чтений.
#3: объединение индексов (BitmapOr)
Когда возникает
Показать первые 20 самых старых «своих» или неназначенных заявок для обработки, причем свои в приоритете.
Как опознать
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan
Рекомендации
Использовать UNION [ALL] для объединения подзапросов по каждому из OR-блоков условий.
Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL -- с вероятностью 1:16 запись "ничья"
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own;
CREATE INDEX ON tbl(fk_own, pk); -- индекс с "вроде как подходящей" сортировкой
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR -- свои
fk_own IS NULL -- ... или "ничьи"
ORDER BY
pk
, (fk_own = 1) DESC -- сначала "свои"
LIMIT 20;

Исправляем:
(
SELECT
*
FROM
tbl
WHERE
fk_own = 1 -- сначала "свои" 20
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL -- потом "ничьи" 20
ORDER BY
pk
LIMIT 20
)
LIMIT 20; -- но всего - 20, больше и не надо
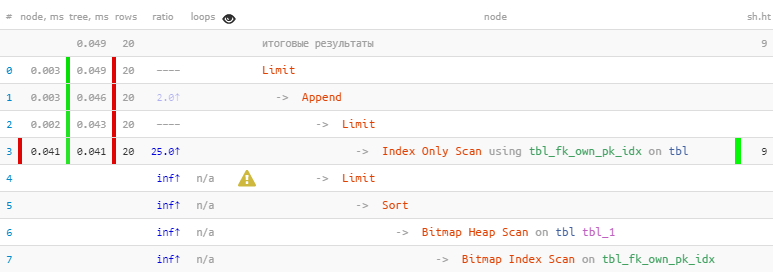
Мы воспользовались тем, что все 20 нужных записей были сразу получены уже в первом блоке, поэтому второй, с более «дорогим» Bitmap Heap Scan, даже не выполнялся — в итоге в 22 раза быстрее, в 44 раза меньше чтений!
#4: читаем много лишнего
Когда возникает
Как правило, возникает при желании «прикрутить еще один фильтр» к уже существующему запросу.
Например, модифицируя задачу выше, показать первые 20 самых старых «критичных» заявок для обработки, независимо от их назначенности.
Как опознать
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- отфильтровано >80% прочитанного
&& loops × RRbF > 100 -- и при этом больше 100 записей суммарно
Рекомендации
Создать [более] специализированный индекс с WHERE-условием или включить в индекс дополнительные поля.
Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own
, (random() < 1::real/50) critical; -- 1:50, что заявка "критичная"
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20;

Исправляем:
CREATE INDEX ON tbl(pk)
WHERE critical; -- добавили "статичное" условие фильтрации

Как видим, фильтрация из плана полностью ушла, а запрос стал в 5 раз быстрее.
#5: разреженная таблица
Когда возникает
Разнообразные попытки сделать собственную очередь обработки задач, когда большое количество обновлений/удалений записей на таблице приводят к ситуации большого количества «мертвых» записей.
Как опознать
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
Рекомендации
Регулярно вручную проводить VACUUM [FULL] или добиться адекватно частой отработки
#6: чтение с «середины» индекса
Когда возникает
Вроде и прочитали немного, и все по индексу, и никого лишнего не фильтровали — а все равно прочитано существенно больше страниц, чем хотелось бы.
Как опознать
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
Рекомендации
Внимательно посмотреть на структуру использовавшегося индекса и ключевые поля, заданные в запросе — скорее всего, часть индекса не задана. Скорее всего, вам придется создать похожий индекс, но без префиксных полей или
Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org, fk_cli); -- все почти как в #2
-- только вот отдельный индекс по fk_cli мы уже посчитали лишним и удалили
SELECT
*
FROM
tbl
WHERE
fk_cli = 999 -- а fk_org не задано, хотя стоит в индексе раньше
LIMIT 20;

Вроде бы все хорошо, даже по индексу, но как-то подозрительно — на каждую из 20 прочитанных записей пришлось вычитать по 4 страницы данных, 32KB на запись — не жирно ли? Да и имя индекса tbl_fk_org_fk_cli_idx наводит на размышления.
Исправляем:
CREATE INDEX ON tbl(fk_cli);
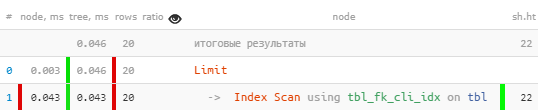
Внезапно — в 10 раз быстрее, и в 4 раза меньше читать!
#7: CTE × CTE
Когда возникает
В запросе набрали «жирных» CTE из разных таблиц, а потом решили сделать между ними JOIN.
Кейс актуален для версий ниже v12 или запросов с WITH MATERIALIZED.
Как опознать
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- слишком большое декартово произведение CTE
Рекомендации
Внимательно проанализировать запрос — а
#8: swap на диск (temp written)
Когда возникает
Разовая обработка (сортировка или уникализация) большого количества записей не влезает в выделенную для этого память.
Как опознать
-> *
&& temp written > 0
Рекомендации
Если использованное операцией количество памяти не сильно превышает установленное значение параметра
Пример:
SHOW work_mem;
-- "16MB"
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1;

Исправляем:
SET work_mem = '128MB'; -- перед выполнением запроса

По понятным причинам, если используется только память, а не диск, то и запрос будет выполняться намного быстрее. При этом еще и часть нагрузки с HDD снимается.
Но надо понимать, что выделять много-много памяти всегда тоже не получится — ее банально не хватит на всех.
#9: неактуальная статистика
Когда возникает
В базу влили сразу много, но не успели прогнать ANALYZE.
Как опознать
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10
Рекомендации
Провести-таки ANALYZE.
#10: «что-то пошло не так»
Когда возникает
Случилось ожидание блокировки, наложенной конкурирующим запросом, или не хватило аппаратных ресурсов CPU/гипервизора.
Как опознать
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- читали мало, но слишком долго
Рекомендации
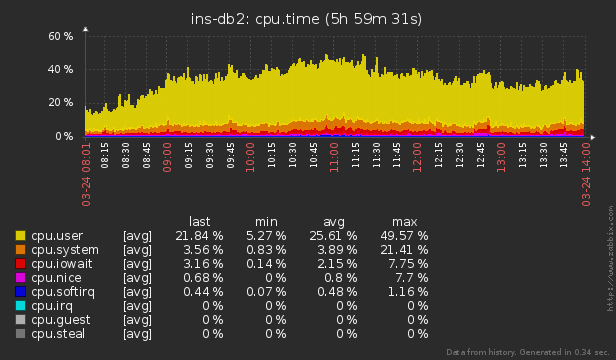
Используйте внешнюю систему для мониторинга сервера на предмет наличия блокировок или нештатного потребления ресурсов. Про наш вариант организации этого процесса для сотен серверов мы уже рассказывали

You must be registered for see links
— публичный
You must be registered for see links
к PostgreSQL.За прошедшее время вы уже воспользовались им более 6000 раз, но одна из удобных функций могла остаться незамеченной — это структурные подсказки, которые выглядят примерно так:
Прислушивайтесь к ним, и ваши запросы «станут гладкими и шелковистыми».
А если серьезно, то многие ситуации, которые делают запрос медленным и «прожорливым» по ресурсам, типичны и могут быть распознаны по структуре и данным плана.
В этом случае каждому отдельному разработчику не придется искать вариант оптимизации самостоятельно, опираясь исключительно на свой опыт — мы можем ему подсказать, что тут происходит, в чем может быть причина, и как можно подойти к решению. Что мы и сделали.
Давайте чуть подробнее рассмотрим эти кейсы — как они определяются и к каким рекомендациям приводят.
Для лучшего погружения в тему сначала можно послушать соответствующий блок из
You must be registered for see links
, а уже потом перейти к детальному разбору каждого примера:#1: индексная «недосортировка»
Когда возникает
Показать последний счет по клиенту «ООО Колокольчик».
Как опознать
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
Рекомендации
Используемый индекс расширить полями сортировки.
Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
fk_cli = 1 -- отбор по конкретной связи
ORDER BY
pk DESC -- хотим всего одну "последнюю" запись
LIMIT 1;
You must be registered for see links
Сразу можно заметить, что по индексу вычиталось больше 100 записей, которые потом все сортировались, а потом была оставлена единственная.
Исправляем:
DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC); -- добавили ключ сортировки
You must be registered for see links
Даже на такой примитивной выборке — в 8.5 раз быстрее и в 33 раза меньше чтений. Эффект будет тем нагляднее, чем больше у вас «фактов» по каждому значению fk.
Замечу, что такой индекс будет работать как «префиксный» не хуже прежнего и по другим запросам с fk, где сортировки по pk не было и нет (подробнее про это можно прочитать
You must be registered for see links
). В том числе, он обеспечит и нормальную поддержку явного foreign key по этому полю.#2: пересечение индексов (BitmapAnd)
Когда возникает
Показать все договоры по клиенту «ООО Колокольчик», заключенные от имени «НАО Лютик».
Как опознать
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan
Рекомендации
Создать составной индекс по полям из обоих исходных или расширить один из существующих полями из второго.
Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org); -- индекс для foreign key
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999); -- отбор по конкретной паре
You must be registered for see links
Исправляем:
DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);
You must be registered for see links
Тут выигрыш меньше, поскольку Bitmap Heap Scan достаточно эффективен сам по себе. Но все-таки в 7 раз быстрее и в 2.5 раза меньше чтений.
#3: объединение индексов (BitmapOr)
Когда возникает
Показать первые 20 самых старых «своих» или неназначенных заявок для обработки, причем свои в приоритете.
Как опознать
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan
Рекомендации
Использовать UNION [ALL] для объединения подзапросов по каждому из OR-блоков условий.
Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL -- с вероятностью 1:16 запись "ничья"
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own;
CREATE INDEX ON tbl(fk_own, pk); -- индекс с "вроде как подходящей" сортировкой
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR -- свои
fk_own IS NULL -- ... или "ничьи"
ORDER BY
pk
, (fk_own = 1) DESC -- сначала "свои"
LIMIT 20;
You must be registered for see links
Исправляем:
(
SELECT
*
FROM
tbl
WHERE
fk_own = 1 -- сначала "свои" 20
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL -- потом "ничьи" 20
ORDER BY
pk
LIMIT 20
)
LIMIT 20; -- но всего - 20, больше и не надо
You must be registered for see links
Мы воспользовались тем, что все 20 нужных записей были сразу получены уже в первом блоке, поэтому второй, с более «дорогим» Bitmap Heap Scan, даже не выполнялся — в итоге в 22 раза быстрее, в 44 раза меньше чтений!
Более детальный рассказ о данном способе оптимизации на конкретных примерах можно прочитать в статьях
Обобщенный вариант упорядоченного отбора по нескольким ключам (а не только по паре const/NULL) рассмотрен в статье
You must be registered for see links
и
You must be registered for see links
.Обобщенный вариант упорядоченного отбора по нескольким ключам (а не только по паре const/NULL) рассмотрен в статье
You must be registered for see links
.#4: читаем много лишнего
Когда возникает
Как правило, возникает при желании «прикрутить еще один фильтр» к уже существующему запросу.
«А у вас нет такого же, но с перламутровыми пуговицами?» х/ф «Бриллиантовая рука»
Например, модифицируя задачу выше, показать первые 20 самых старых «критичных» заявок для обработки, независимо от их назначенности.
Как опознать
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- отфильтровано >80% прочитанного
&& loops × RRbF > 100 -- и при этом больше 100 записей суммарно
Рекомендации
Создать [более] специализированный индекс с WHERE-условием или включить в индекс дополнительные поля.
Если условие фильтрации является «статичным» для ваших задач — то есть не предполагает расширения перечня значений в будущем — лучше использовать WHERE-индекс. В эту категорию хорошо укладываются разные boolean/enum-статусы.
Если же условие фильтрации может принимать разные значения, то лучше расширить индекс этими полями — как в ситуации с BitmapAnd выше.
Если же условие фильтрации может принимать разные значения, то лучше расширить индекс этими полями — как в ситуации с BitmapAnd выше.
Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own
, (random() < 1::real/50) critical; -- 1:50, что заявка "критичная"
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20;
You must be registered for see links
Исправляем:
CREATE INDEX ON tbl(pk)
WHERE critical; -- добавили "статичное" условие фильтрации
You must be registered for see links
Как видим, фильтрация из плана полностью ушла, а запрос стал в 5 раз быстрее.
#5: разреженная таблица
Когда возникает
Разнообразные попытки сделать собственную очередь обработки задач, когда большое количество обновлений/удалений записей на таблице приводят к ситуации большого количества «мертвых» записей.
Как опознать
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
Рекомендации
Регулярно вручную проводить VACUUM [FULL] или добиться адекватно частой отработки
You must be registered for see links
с помощью тонкой настройки его параметров, в том числе
You must be registered for see links
.В большинстве случаев подобные проблемы оказываются вызваны плохой компоновкой запросов при вызовах с бизнес-логики вроде тех, которые были рассмотрены в
Но надо понимать, что даже VACUUM FULL может помочь не всегда. Для таких случаев стоит ознакомиться с алгоритмом из статьи
You must be registered for see links
.Но надо понимать, что даже VACUUM FULL может помочь не всегда. Для таких случаев стоит ознакомиться с алгоритмом из статьи
You must be registered for see links
.#6: чтение с «середины» индекса
Когда возникает
Вроде и прочитали немного, и все по индексу, и никого лишнего не фильтровали — а все равно прочитано существенно больше страниц, чем хотелось бы.
Как опознать
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
Рекомендации
Внимательно посмотреть на структуру использовавшегося индекса и ключевые поля, заданные в запросе — скорее всего, часть индекса не задана. Скорее всего, вам придется создать похожий индекс, но без префиксных полей или
You must be registered for see links
.Пример:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org, fk_cli); -- все почти как в #2
-- только вот отдельный индекс по fk_cli мы уже посчитали лишним и удалили
SELECT
*
FROM
tbl
WHERE
fk_cli = 999 -- а fk_org не задано, хотя стоит в индексе раньше
LIMIT 20;
You must be registered for see links
Вроде бы все хорошо, даже по индексу, но как-то подозрительно — на каждую из 20 прочитанных записей пришлось вычитать по 4 страницы данных, 32KB на запись — не жирно ли? Да и имя индекса tbl_fk_org_fk_cli_idx наводит на размышления.
Исправляем:
CREATE INDEX ON tbl(fk_cli);
You must be registered for see links
Внезапно — в 10 раз быстрее, и в 4 раза меньше читать!
Другие примеры ситуаций неэффективного использования индексов можно увидеть в статье
You must be registered for see links
.#7: CTE × CTE
Когда возникает
В запросе набрали «жирных» CTE из разных таблиц, а потом решили сделать между ними JOIN.
Кейс актуален для версий ниже v12 или запросов с WITH MATERIALIZED.
Как опознать
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- слишком большое декартово произведение CTE
Рекомендации
Внимательно проанализировать запрос — а
You must be registered for see links
? Если все-таки да, то применить «ословаривание» в hstore/json по модели, описанной в
You must be registered for see links
.#8: swap на диск (temp written)
Когда возникает
Разовая обработка (сортировка или уникализация) большого количества записей не влезает в выделенную для этого память.
Как опознать
-> *
&& temp written > 0
Рекомендации
Если использованное операцией количество памяти не сильно превышает установленное значение параметра
You must be registered for see links
, стоит его скорректировать. Можно сразу в конфиге для всех, а можно через SET [LOCAL] для конкретного запроса/транзакции.Пример:
SHOW work_mem;
-- "16MB"
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1;
You must be registered for see links
Исправляем:
SET work_mem = '128MB'; -- перед выполнением запроса
You must be registered for see links
По понятным причинам, если используется только память, а не диск, то и запрос будет выполняться намного быстрее. При этом еще и часть нагрузки с HDD снимается.
Но надо понимать, что выделять много-много памяти всегда тоже не получится — ее банально не хватит на всех.
#9: неактуальная статистика
Когда возникает
В базу влили сразу много, но не успели прогнать ANALYZE.
Как опознать
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10
Рекомендации
Провести-таки ANALYZE.
Подробнее данная ситуация расписана в
You must be registered for see links
.#10: «что-то пошло не так»
Когда возникает
Случилось ожидание блокировки, наложенной конкурирующим запросом, или не хватило аппаратных ресурсов CPU/гипервизора.
Как опознать
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- читали мало, но слишком долго
Рекомендации
Используйте внешнюю систему для мониторинга сервера на предмет наличия блокировок или нештатного потребления ресурсов. Про наш вариант организации этого процесса для сотен серверов мы уже рассказывали
You must be registered for see links
и
You must be registered for see links
.