

Оффлайн
- Регистрация
- 23.09.18
- Сообщения
- 12.347
- Реакции
- 176
- Репутация
- 0

Автоматическое распознавание речи (STT или ASR) прошло долгий путь совершенствования и имеет довольно обширную историю. Расхожим мнением является то, что лишь огромные корпорации способны на создание более-менее работающих "общих" решений, которые будут показывать вменяемые метрики качества вне зависимости от источника данных (разные голоса, акценты, домены). Вот несколько основных причин данного заблуждения:
- Высокие требования к вычислительным мощностям;
- Большое количество данных, необходимых для обучения;
- В публикациях обычно пишут только про так называемые state-of-the-art решения, имеющие высокие показатели качества, но абсолютно непрактичные.
В данной статье мы развеем некоторые заблуждения и попробуем немного приблизить точку "сингулярности" для распознавания речи. А именно:
- Расскажем, что можно достигнуть отличного результата в рамках разумного времени, используя лишь две видеокарты NVIDIA GeForce 1080 Ti;
- На всякий случай еще раз представим датасет
You must be registered for see linksдля русского языка на 20 000 часов;
- Опишем различные подходы, позволяющие ускорить процесс тренировки STT на порядок.
В этой статье есть 3 основных блока — критика литературы и доступных инструментов, паттерны для проектирования своих решений и результаты нашей модели.
Оглавление
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
-
You must be registered for see links
-
You must be registered for see links
-
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
Технологии
Для экспериментов мы выбрали PyTorch, а в качестве отправной точки для нейросети —
You must be registered for see links
.Причины выбора данного стека:
- Масштабируемость вычислительных мощностей количеством GPU;
- Простота. Python и PyTorch упрощают процесс исследования, можно сфокусироваться на самих экспериментах;
- Гибкость. Добавление новых фич не занимает много времени и усилий;
Также немаловажно, что экосистема PyTorch постепенно обрастает такими "вкусными" фичами из коробки как квантизация, деплой на мобилку, обертки и конвертеры для других языков программирования (например, C++ и JAVA).
Датасет Open STT
Ранее мы писали на Хабре об
You must be registered for see links
с более чем 20 000 часами разметки для русского языка. Этот датасет содержит бОльшую часть данных (~90%), используемых для тренировки наших моделей.Критика индустрии
Большинство научных статей, которые мы прочли, как правило, были написаны исследователями из “индустрии” (напр. Google, Baidu, и Facebook). В целом, большую часть критики статей и решений STT можно отнести к опыту исследователя в “индустрии” либо в “академии”.
Если кратко, наши основные претензии к индустрии, когда мы говорим об STT, такие:
- Создание продакшен решений на основе приватных данных, о чем в самих публикациях информации очень мало;
- Сложные фреймворки и инструменты;
- Решение несуществующих проблем;
- Обфусцированные результаты.
Давайте подробно разберём каждый из приведенных пунктов.
Создание продакшен решений на основе приватных данных, о чем в самих публикациях информации очень мало
Знаменитая статья Deep Speech 2 (2015) приводит следующую таблицу:
| Процент данных, % | Часы, ч | Обычные данные WER, % | Шумные данные WER, % |
|---|---|---|---|
1 | 120 | 29,23 | 50,97 |
10 | 1200 | 13,80 | 22,99 |
20 | 2400 | 11,65 | 20,41 |
50 | 6000 | 9,51 | 15,90 |
100 | 12000 | 8,46 | 13,59 |
Сравнение WER (word error rate, процент ошибок на уровне слов) для английского языка для Обычного и Шумного датасетов при увеличении размеров датасета. Архитектура сети: 9-слойная модель с 2 слоями 2D-инвариантных сверток и 7 рекуррентными слоями с 68 млн. параметров,
You must be registered for see links
.Вывод на основе нее такой: чтобы сделать модель хорошего качества, нужно много данных. Это одна из немногочисленных статей, явно на это обращающих внимание и проводящих валидацию на данных из внешних датасетов. Большинство современных STT статей обычно сильно оверфитятся на корпусе
You must be registered for see links
(LibriSpeech) все более и более экстравагантными способами.Вполне вероятно, что Google, Facebook, и Baidu имеют у себя в распоряжении датасеты на 10 000 — 100 000 часов для тренировки своих моделей. На это можно найти намеки, например, в последних публикациях Facebook, но, естественно, корпорациям невыгодно делиться тем, на каких данных натренированы их продакшен решения.
К этому прибавляется еще и относительная трудоемкость ручной разметки. На 1 час разметки может понадобиться от 2 до 10 часов труда разметчика (влияют сложность домена и наличие автоматической разметки на входе, например, результатов распознавания STT модели).
Все это приводит к текущей ситуации, когда все заявляют о невероятных результатах на идеализированном публичном датасете (LibriSpeech), но молчат о том, как эти модели ведут себя на реальных данных и на чем собственно какие продакшен-модели натренированы. Экономического стимула выпускать в open-source большие проприетарные датасеты у таких компаний, как Google, естественно нет. В конечном счете, возникает высокий барьер на вход для тех, кто хочет создать свою STT-систему. Есть, конечно, проекты типа
You must be registered for see links
, но данных там пока очень мало для всех языков кроме английского.Сложные фреймворки и инструменты
| Проект | Коммитов | Разработчиков | Язык/Фреймворк | Комментарий |
|---|---|---|---|---|
Wav2Letter++ | 256 | 21 | C++ | Коммиты тут скорее это релизы версий |
FairSeq | 956 | 111 | PyTorch | � |
OpenNMT | 2 401 | 138 | PyTorch | � |
EspNet | 5 441 | 51 | PyTorch | � |
Типичный ML проект | 300-500 | 1 — 10 | PyTorch | � |
Обычный подход в машинном обучении (как и в разработке в целом) — использование фреймворков вместо написания всего с нуля. Казалось бы, должны быть фреймворки для STT, из которых можно было бы брать готовые части/модели, чтобы не писать модели с нуля на PyTorch и TensorFlow. Но, к сожалению, с речью дело обстоит несколько иначе.
Использовать такие инструменты/фреймворки (таблица выше), чтобы придать первичный импульс своему проекту, нерационально по целому ряду причин:
- Код оптимизирован под большие вычислительные возможности (десятки или даже сотни видеокарт);
- Рецепты (end-to-end примеры, показывающие, как использовать фреймворк) существуют только для небольших академических датасетов и не масштабируются на реальные данные без опять же больших вычислительных мощностей;
- Рецепты очень прожорливы (выдающийся пример — тренировка 10GB-ых языковых моделей на датасетах из нескольких сотен мегабайт текста);
- Даже если сделать претренировку модели на LibriSpeech, вероятнее всего, она не заработает на реальных данных;
- При желании создать внутреннее STT решение на основе таких инструментов, подогнать его под себя, разобраться в нем и оптимизировать, с большой вероятностью вам понадобятся или большая команда, или значительное количество времени;
- Эти инструменты являются либо опубликованными внутренними инструментами, или сделаны в целях PR, в соответствии со стратегией “быть первыми на рынке” или призваны создать “экосистему”. А это значит, что вероятнее всего, эти решения могут служить минимально жизнеспособным продуктом или базовым решением, вот только подогнать их под себя, не инвестировав запретительное количество ресурсов, не удастся (а если вы корпорация, то вы, скорее всего, сами напишете свой инструмент);
- Если вы все-таки дойдете до нужного качества, то скорее всего встанет вопрос скорости работы решения, и не факт, что решение, которое изначально дизайнилось прожорливым, будет очень быстрым;
Исходя из личного опыта, мы несколько раз подходили к некоторым пайплайнам из
You must be registered for see links
и
You must be registered for see links
, и пришли к выводу, что в разумные сроки и разумным количеством усилий их не одолеть. Может быть, у вас получилось?Решение несуществующих проблем
Создание нового инструмента для LibriSpeech, который работает на 8 GPU за US $10 000 не поможет в решении реальных задач.
А помогут — создание и публикация открытых публичных датасетов из реальных данных в разных доменах и публикация претренированных моделей на таких датасетах. По крайней мере, так было с компьютерным зрением.
Тем не менее, пока из внешних датасетов по-настоящему "народным" можно считать разве что Common Voice от Mozilla.
Невоспроизводимые результаты
Регулярно наблюдаемая картина в ML: каждую неделю кто-то заявляет о новом рекордном (state-of-the-art, SOTA) результате, только результаты эти редко воспроизводимы или приведены вместе с запускаемым кодом.
Добавить сюда безумное количество требуемого железа, большие датасеты, время, требуемое для обучения, и задача воспроизводимости становится только сложнее.
Мы верим в то, что фокус должен быть смещен c “пробивания лидербордов” в сторону “решений, достаточных для применения в решении реальных задач” и публичных датасетов.
Критика академии
Если не сильно углубляться, то суть сводится к следующему:
- Когда большая группа людей преследует какую-либо метрику, эта метрика становится бесполезной (см.
You must be registered for see links);
- Оверфиттинг на маленьком “стандартном” датасете сломан ничуть не меньше, чем конкурсные лидерборды (да и по сути, такой оверфиттинг сам же и является лидербордом);
- Использование больших, прожорливых сетей на больших вычислительных мощностях вместе с невоспроизводимостью результатов оставляют желать лучшего;
- Подход к модели как к алгоритму сжатия может быть куда более привлекательным и полезным, чем погоня за высокими метриками на лидерборде;
- В идеальном сценарии статьи должны быть достаточно детальными, чтобы независимый исследователь мог воспроизвести хотя бы 95% того, что удалось достичь авторам. В реальности же содержание и структура статей вызывают вопросы к их действительной цели и возможности реального применения. То есть они опубликованы в соответствии с ментальностью “без бумажки ты букашка” (“publish or perish”), и сложная математика использована для объяснения новых концепций, несмотря на то, что сами исследователи к этой математике никакого отношения не имеют, а для вычислений использовали готовые пакеты;
Когда дело касается генерализации решения, то есть тестирования вне домена, статьи, мягко говоря, расплывчаты. По прочтению статей может сложиться впечатление, что люди проигрывают нейросетям в распознавании речи, но это не так, это всего лишь еще один симптом лидерборда. В противном случае, приложения с идеальным распознаванием речи были бы многочисленны повсюду и на всех устройствах.
Было бы куда проще достигать результатов, если бы ML статьи следовали следующей структуре:
- Использованы следующие инструменты/ имплементации/ идеи;
- Внесены следующие важные модификации;
- Проведены следующие эксперименты и получены следующие результаты.
На что еще можно обратить внимание
На что еще обратить внимание, имея дело с машинным обучением и распознаванием речи:
- Очень мало внимания уделяется стабильности гипер-параметров;
- Совершенно новые semi-supervised и unsupervised подходы обучения (
You must be registered for see links,You must be registered for see links) не проводят никаких проверок прожорливости, устойчивости, генерализуемости и в основном продвигают фактор новизны;
- Академики обычно оверфитят свои языковые модели и методы end-to-end обработки на маленьком и идеализированном датасете (LibriSpeech), при этом их методы очень субоптимальны, так как данных в текстовых доменах как минимум в 1000 раз больше (просто сравните размер Википедии и весь корпус LibriSpeech);
- Привычка слишком сильно полагаться на MFCC в литературе. Мы пока не видели хорошего сравнения разных фильтров. В наших экспериментах на небольших датасетах заметной разницы не было, на реальных же шумных данных лучше всего себя показывал STFT. Ко всему прочему, у нас не получилось запустить какие-то значимые эксперименты на более новых фильтрах вроде
You must be registered for see links.
Критика нашего решения
Мы сами, на самом деле, отчасти подвержены тому же, что критикуем. Можно свести основные пункты к следующему:
- Мы использовали приватные данные для тренировки своих моделей, хотя размер нашего приватного датасета меньше полного размера датасета на порядок;
- Мы не выложили в open-source наш тренировочный пайплайн (во всяком случае, пока).
Как создать действительно хорошую STT модель
Одни из ключевых составляющих действительно хорошей STT модели:
- Быстрый инференс;
- Эффективность с точки зрения количества параметров;
- Простота в поддержке и возможность доработки;
- Нетребовательность к ресурсам и вычислительным мощностям, для тренировки достаточно 2-4 видеокарт 1080Ti.
Методология выбора лучшей модели
Самый распространенный подход при выборе лучшей модели — это сравнение качества на паре "эталонных" вадидационных выборок. Как мы уже разобрались выше, такой способ не всегда отражает истинное положение вещей (получается лидерборд). Также следует помнить, что при работе с реальными данными не существует идеальной валидационной выборки — важно сравнить качество отдельно для каждого домена.
Основная проблема, с которой приходится сталкиваться на практике, — это ограниченность ресурсов. Провести сотни или тысячи полноценных экспериментов с нуля для каждого набора гиперпараметров — чаще всего непозволительная роскошь. А преобладание прожорливых методов и инструментов в индустрии и литературе может отбить желание серьезно браться за оптимизацию своего пайплайна.
Например, AWS предлагает только NVIDIA Tesla GPU, ориентированные на продакшн, которые в 5-10 раз дороже стандартных пользовательских GPU.
Для максимально эффективной оптимизации модели мы придерживаемся следующего набора методов и допущений:
В грубом приближении, качество модели примерно равно [ёмкости модели] x [её производительность]. Как правило, это означает, что нужно оценить следующие две вещи: 1) как быстро модель тренируется и 2) когда кривая функции потерь выходит на плато? Так, если модели не хватает параметров для обучения, функция потерь никогда не выйдет на плато;
Очевидно, что между ёмкостью модели и скоростью тренировки всегда приходится искать компромисс.
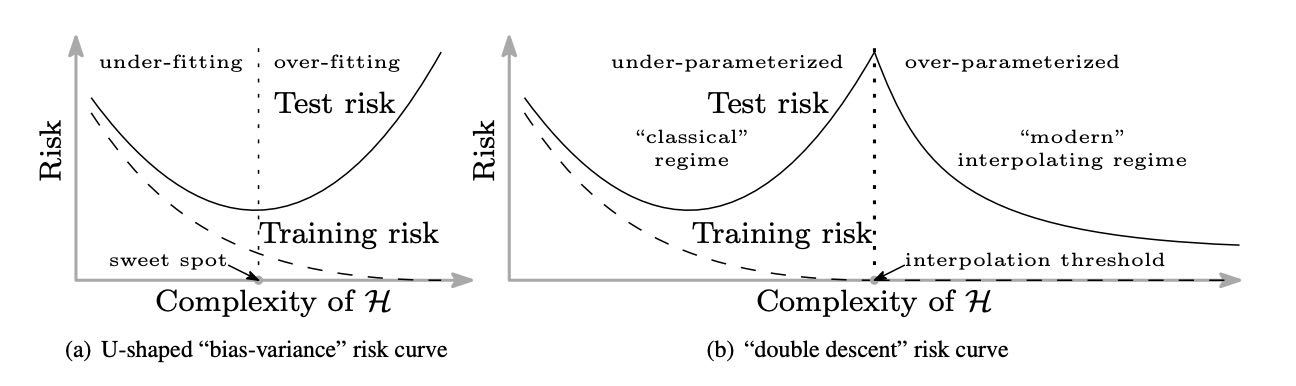
Современные модели обычно не переобучаются, а сходятся как "L-кривые"
Ёмкость модели — функция её сложности. Большие модели, также как и более сложные слои, обучаются гораздо дольше и "капризнее". Поэтому лучше остановить свой выбор на стандартных протестированных модулях с простой параллелизуемой архитектурой;
Тесты с полным перебором гиперпараметров требуют много ресурсов. Поэтому лучше а) объединять гиперпараметры в группы; б) сначала менять только те гиперпараметры, которые отвечают за серьезные изменения в логике модели;
Сначала мы оптимизируем сеть для того, чтобы сделать её более быстрой и компактной, затем добавляем сложность. На первый взгляд, такой подход кажется не самым эффективным, но последние архитектурыYou must be registered for see links/You must be registered for see links/You must be registered for see linksговорят об обратном;
Есть два принципа, которые ML исследователи часто упускают из виду: 1) Бритва Оккама: Мы не используем модуль, если не знаем, зачем он нужен и какие у него свойства; 2) Ceteris paribus: если в пайплайне поменялась одна незначительная вещь, необязательно прогонять эксперимент заново, т.к. скорее всего, можно предсказать поведение модели на основе предыдущих тестов;
Таким образом, чтобы найти лучшую модель, нужно построить (или найти) хороший пайплайн, провести пару полноценных экспериментов с нуля и уже затем начинать добавлять небольшие изменения. Раз в 10 или 20 экспериментов, когда таких изменений накопится слишком много, можно устроить несколько тестов, чтобы проверить свой пайлайн на наличие "бесполезных" фич.
Теми же приниципами мы руководствовались при оптимизации текущей модели (подробнее об основных идеях можно почитать ниже):
- Ceteris paribus: Все прочие условия, кроме указанных как объект эксперимента, оставались постоянными. Тренировочная и валидационная выборки, так же, как и железо, не менялись;
- Сравнение метрик проводилось на валидационном датасете
You must be registered for see links;
- Хотя некоторые изменения и были направлены на улучшение производительности, все эксперименты выполнялись при достаточно высокой нагрузке на железо (не было "узких горлышек" в I/O, обработка данных занимала мало времени, итд итп).
Общий прогресс
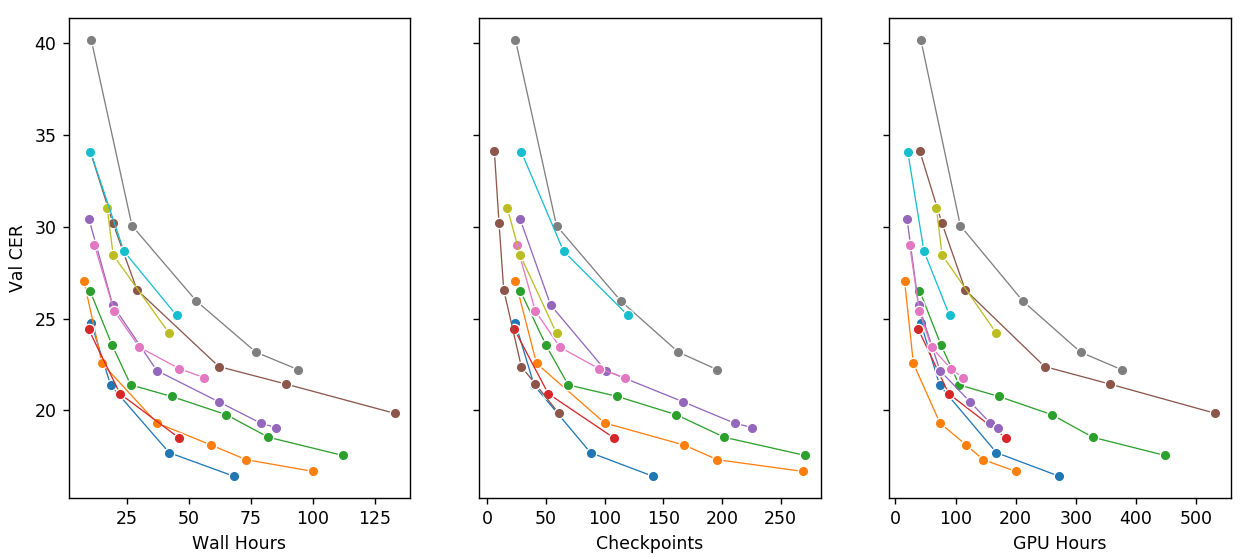
Иллюстрация достигнутого прогресса — кривые схождения моделей. Если экстраполировать первые модели — экономия вычислительного времени на порядок. Самые "плохие" модели на графике — простые сверточные модели в стиле Wav2Letter. Логи для рекуррентных моделей в стиле DeepSpeech не сохранились, но они были еще в 2-3 раза медленней. GPU часы — это часы тренировки модели, умноженные на число использованных видеокарт. Изменения в архитектуру вносились маленькими шагами, все остальные параметры были неизменны.
Мы начинали наш путь с реализации Deep Speech 2 на Pytorch. В основе этой модели лежат глубокие реккурентные LSTM и GRU сети, не отличающиеся высокой скоростью. График выше наглядно иллюстрирует эффект основных оптимизаций, которые мы добавили в оригинальный пайплайн. Как итог, нам удалось сделать следующее, не снизив при этом качество распознавания:
- Уменьшить размер модели в ~3-5 раз;
- Ускорить сходимость в 5-10 раз;
- Натренировать одну из финальных моделей на двух 1080Ti вместо четырех.
Идея №1: Оптимизировать шаг свёртки.
Подробнее
Можно оптимизировать шаг свертки (всей модели целиком) исходя из соотношения полезных токенов к пустым токенам.
Идея №2: Использовать компактные регуляризованные сети.
Подробнее
Сетки, переоптимизированные под мобильные устройства — не лучший источник архитектурных решений. Однако, из первых поколений таких моделей можно почерпнуть довольно много крутых идей: например,
You must be registered for see links
.Как бонус, небольшие регуляризованные модели легче обучать, так как оверфитятся они заметно меньше. С другой стороны, сходятся такие сети медленнее. Судя по нашему опыту, если веса компактной модели в 3-4 раза меньше весов исходной большой модели, при прочих равных условиях ей потребуется в 3-4 раза больше итераций чтобы дойти до того же уровня качества.
Идея №3: Использовать Byte-Pair-Encoding для токенизации текста.
Подробнее
Тут важно найти компромисс. Акустическая модель с BPE на выходе начинает вести себя как слабая языковая модель и, как следствие, WER (доля ошибок в словах) снижается. Однако, тут есть и оборотная сторона: при увеличении размера BPE словаря есть риск переобучить акустическую модель распознавать только знакомые последовательности. Также стоит учесть, что BPE не в силах заменить полноценную языковую модель, натренированную на большом объёме текстов.
Подробнее с этим и альтернативными подходами можно ознакомиться в
You must be registered for see links
.Идея №4: Использовать более эффективный энкодер.
Подробнее
Суть данной идеи в поиске оптимальной архитектуры encoder-decoder. Наш свёрточный энкодер работает так быстро, что мы можем позволить себе гораздо более тяжелый декодер, в том числе state-of-the-art подходы вроде трансформера.
В целом, сети с такой структурой получаются настолько вычислительно эффективными, что им даже не требуются GPU в продакшене. Так, наша акустическая модель может спокойно обрабатывать 500-1000 секунд аудио за одну GPU секунду, и 3-4 секунды аудио за CPU секунду без потерь в качестве распознавания (и это до квантизации, прунинга и некоторых последних оптимизаций). Потенциально, можно получить прирост скорости еще в 2-4 раза, в зависимости от того, какие идеи сработают.
Идея №5: Соблюдать баланс между ёмкостью модели и вычислительными возможностями.
Заголовок спойлера
В общей сложности, оптимизировав разные части модели, нам удалось получить сеть, которая быстро тренируется всего на двух 1080Ti и, в то же время, показывает качество, сравнимое с моделями, требующими 4 или даже 8 GPU для обучения (а в некоторых статьях говорят и про десятки GPU). На наш взгляд, это самое впечатляющее наше достижение на данный момент.
Идея №6: Генерализация и хаки для обучения на нескольких доменах.
Подробнее
Одна из ключевых проблем в распознавании речи, с которой не могут справиться даже регуляризованные сети, — это катастрофическое забывание. По мере обучения, модели подгоняются под новые данные, что может крайне негативно сказываться на распознавании на старых доменах.
Для решения этой проблемы лучше всего подходит метод curriculum learning. Грубо говоря, сначала мы показываем сетке простые примеры, затем постепенно переходим к более сложным.
Идея №7. Быстрая постобработка выдачи акустической модели.
Подробнее
Это уже немного выходит за рамки нашей статьи, но стоит упомянуть декодинг — постобработку выхода акустической модели. Есть два известных подхода:
- Sequence-to-sequence модели;
- Beam search с языковой моделью — довольно медленный по сравнению с AM.
В ходе экспериментов нам удалось в разы ускорить нашу реализацию beam search на базе KenLM и достичь идеализированной скорости обработки в 25 секунд аудио на одно CPU ядро.
Бенчмарки и генерализация
Распознаванию речи присуща большая вариативность данных:
- Уровень шума может варьироваться от студийных записей до телефонных звонков, распознавание которых вызывает трудности даже у людей;
- Произношение. Люди из разных географических областей могут совершенно иначе произносить одни и те же слова и предложения;
- Словари/Область применения. Речь с заседания суда и пранки практически не пересекаются в плане используемых "редких" слов;
- Кодеки для сжатия аудио тоже влияют на качество с точки зрения модели.
Как правило, качество большинства доступных коммерческих решений (за редким исключением) на доменах, которые они не видели при тренировке, оставляет желать лучшего. Интересно, что по поведению модели на широкой области валидацонных сетов можно понять, какие данные были использованы при ее тренировке.
Домены
Чтобы свести предвзятость к минимуму, мы выбрали следующий список доменов разной степени приближенности к реальным данным:
- Чтение. Самый простой и далекий от реальности домен — люди читают в микрофон. Качество идеальное, словарь не очень большой;
- Звонки (такси). Реальные звонки в такси. Словарь перекошен в сторону адресов, качество среднее;
- Публичные выступления. Большое разнообразие кодеков и форматов, большой словарь, довольно высокое качество;
- Радио. Большое разнообразие кодеков и форматов, большой словарь, среднее качество;
- Заседания суда. Большой словарь, перекошенный в сторону юридических терминов, среднее качество записи;
- Аудио книги. Высокое качество речи, монотонные интонации, большой словарь;
- YouTube. Огромное разнообразие по качеству, формату, словарю. Как бонус — аудио с фоновой музыкой;
- Звонки (e-commerce). Довольно среднее качество аудио, много очень специфичной лексики;
- "Yellow pages". Звонки в различные бизнесы с целью бронирования и записи. Низкое и среднее качество, малый словарь, много артефактов телефонии и шумов;
- Медицинские термины. Стресс-тест моделей. Низкое качество записи, все аудиозаписи содержат "непонятные" обычному человеку термины. Мы убрали все записи, где нет таких терминов;
- Звонки (пранки). Низкое качество, много обсценной лексики, очень много шумов, очень неровные интонации.
Результаты
Мы протестировали большую часть доменов на следующих системах:
- Tinkoff (тестировали несколько раз, качество сильно выросло);
- ЦРТ (звонки, общая модель, медицина, телеком, финансы);
- Yandex SpeechKit;
- Google;
- Kaldi 0.6 / Kaldi 0.7 (сначала через свой билд, а потом через vosk-api);
- wit.ai;
- stt.ai;
- Azure;
- Speechmatics;
- Voisi;
Основная метрика в задаче распознавани речи — Word error rate (WER).
Т.к некоторые системы используют денормализацию текста ("первая" -> "1-ая"), мы привели их результаты к общему формату с помощью
You must be registered for see links
. Алгоритм неидеален, поэтому истинный WER может отличаться от указанного нами на ~1 процентный пункт.Большая часть тестов проводилась с использованием публичных АПИ описанных выше сервисов в конце 2019 начале 2020 года. Мы использовали ОДНУ И ТУ ЖЕ нашу модель без разных словарей под каждый домен, за исключением такси. В такси словарь улучшал WER на ~1 процентный пункт. Системы, где был сильный рост по качеству, мы тестировали повторно недавно.
| Домен | Систем лучше | Систем хуже | Наш WER | Лучший WER | Худший WER |
|---|---|---|---|---|---|
Чтение | 2 | 14 | 10% | 3% | 29% |
Звонки (такси) | 0 | 17 | 13% | 13% | 86% |
Публичные выступления | 0 | 16 | 15% | 15% | 60% |
Радио | 0 | 16 | 18% | 18% | 70% |
Заседания суда | 0 | 7 | 21% | 21% | 53% |
Аудио книги | 4 | 14 | 27% | 22% | 70% |
YouTube | 1 | 17 | 31% | 30% | 73% |
Звонки (e-commerce) | 2 | 13 | 32% | 29% | 76% |
Yellow pages | 1 | 6 | 33% | 31% | 72% |
Медицинские термины | 1 | 6 | 40% | 39% | 72% |
Звонки (пранки) | 3 | 14 | 41% | 38% | 85% |
Статья и так получается довольно огромной. Если вас интересует более подробная методология и позиции каждой системы на каждом домене, то расширенный вариант сравнения систем вы найдете
You must be registered for see links
, а описание методологии сравнения
You must be registered for see links
.