

Оффлайн
- Регистрация
- 14.05.16
- Сообщения
- 11.398
- Реакции
- 501
- Репутация
- 0
Перед вами перевод поста Chaitanya Joshi "
Публикуется с любезного разрешения автора поста.
Друзья-датасаентисты часто задают один и тот же вопрос: графовые нейронные сети (Graph Neural Networks) — прекрасная идея, но были ли у них хоть какие-то настоящие истории успеха? Есть ли у них какие-нибудь полезные на практике приложения?

Можно привести в пример и без того известные варианты — рекомендательные системы в
В этом посте мне бы хотелось установить связи между
Начнём с обсуждения основной цели разработки архитектур разных моделей — с обучения представлений (representation learning).
Обучение представлений для NLP
Так или иначе все нейросетевые архитектуры строят представления входных данных в виде векторов, которые "кодируют" полезные статистические и семантические свойства этих данных. Эти латентные (скрытые) (latent/hidden) представления можно затем переиспользовать для какой-нибудь полезной задачи. Например, для классификации изображений или перевода предложений. Нейронные сети обучают представления всё лучше и лучше благодаря обратной связи, которую они обычно получают в виде значений функций потерь (error/loss functions).
Принято, что в обработке естественного языка (natural language processing; NLP), рекуррентные нейронные сети (recurrent neural networks; RNN) для каждого слова в предложении строят отдельное представление — шаг за шагом, по одному слову. Можно представить себе RNN как ленту конвейера, на которой слова обрабатываются авторегрессивно слева направо. В итоге на каждое слово в предложении получаем вектор скрытых представлений, которые мы либо передаём на следующий слой RNN, либо используем для нашей целевой задачи.

Трансформеры были изначально разработаны для машинного перевода и постепенно заменили RNN в основных задачах NLP. В архитектуру заложен свежий подход к обучению представлений: полностью избавившись от рекуррентности, трансформеры для каждого слова строят признаки, используя для этого
Трансформер по частям
Давайте переведём наше интуитивное описание архитектуры в прошлом абзаце на язык формул. Так,
 — скрытое представление
— скрытое представление
 -ого слова в предложении
-ого слова в предложении
 — от слоя
— от слоя
 к слою
к слою
 обновляется вот так:
обновляется вот так:



где за
 мы обозначили множество слов в предложении, а за
мы обозначили множество слов в предложении, а за
 — обучаемые линейные веса (соответственно сокращённые Query, Key и Value). Механизм внимания вычисляется параллельно для каждого слова в предложении, чтобы разом получить их обновлённые признаки. Ещё десять очков трансформерам! — если сравнивать их с RNN, которые обновляют признаки пословно.
— обучаемые линейные веса (соответственно сокращённые Query, Key и Value). Механизм внимания вычисляется параллельно для каждого слова в предложении, чтобы разом получить их обновлённые признаки. Ещё десять очков трансформерам! — если сравнивать их с RNN, которые обновляют признаки пословно.
Механизм внимания легче понять, рассмотрев следующую цепочку шагов:
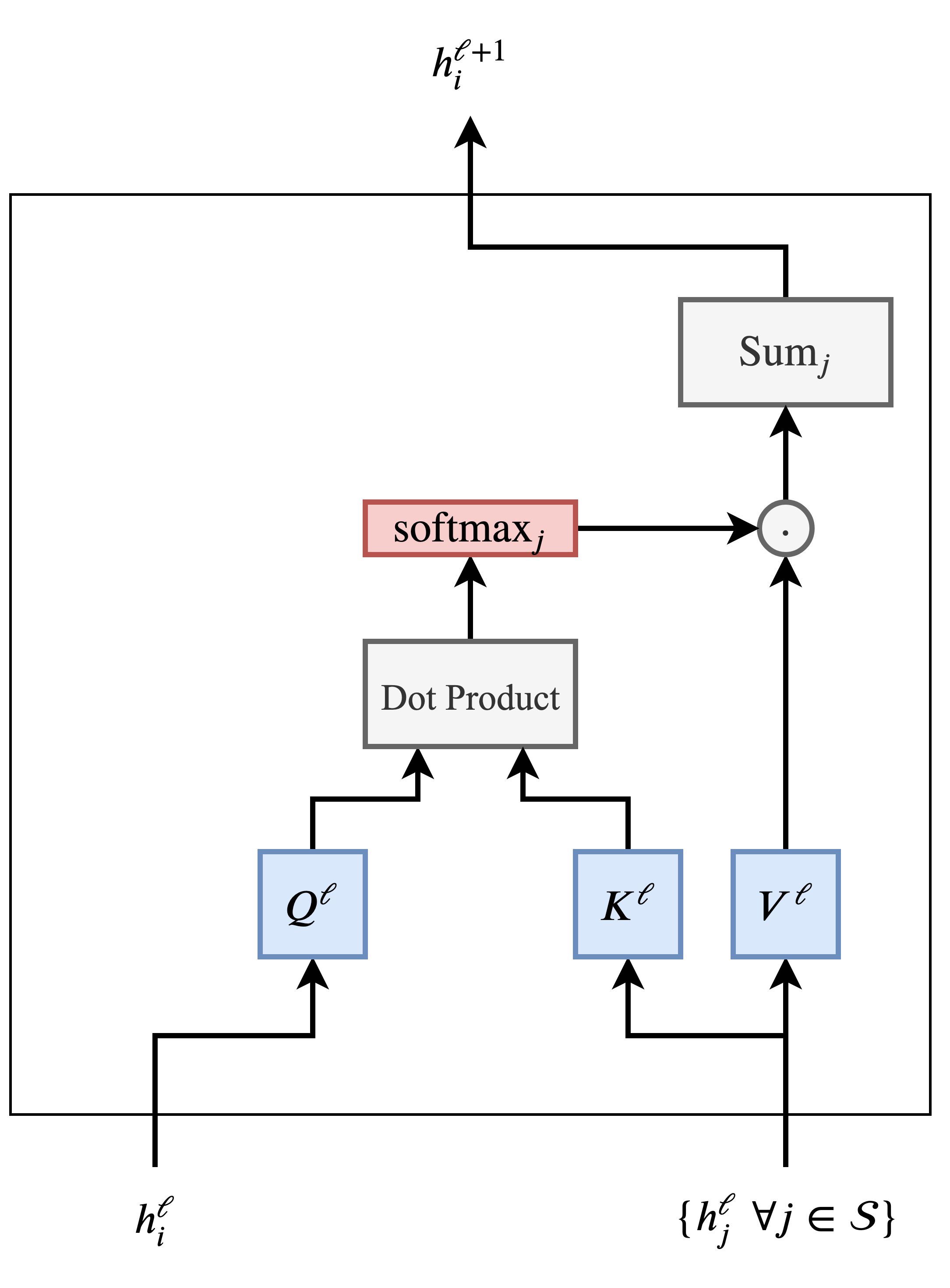
Многоголовое внимание (Multi-Head Attention)
Не так-то просто заставить работать внимание-на-скалярном-произведении (dot product attention): неудачная инициализация случайными значениями может дестабилизировать процесс обучения. С этим справляются, одновременно вычисляя внимание сразу несколькими "головами" (attention heads) и склеивая (конкатенируя) результаты (при этом у каждой "головы" свои обучающиеся веса):


где
 — обучаемые веса
— обучаемые веса
 -й "головы" внимания, а
-й "головы" внимания, а
 — это проекция, чтобы размерности
— это проекция, чтобы размерности
 и
и
 соответствовали по всем слоям.
соответствовали по всем слоям.
В сущности, несколько "голов" позволяют механизму внимания "сделать сразу несколько ставок", давая возможность смотреть на разные преобразования или аспекты признаков с предыдущего слоя. Мы ещё поговорим об этом позже.
Проблемы масштабирования и "подслой" прямого распространения
Scale issues and the Feed-forward sub-layer
Ключевая проблема, из-за которой архитектура трансформеров устроена именно так, как устроена, заключается вот в чём: значения признаков для каждого слова после применения механизма внимания могут быть очень разными по величине. Во-первых (1), это может быть из-за слишком "острых пиков" или, напротив, равномерности в распределении внимания
 . Во-вторых (2), мы для каждого слова склеиваем выходы нескольких голов, и они также могут быть очень разными по "масштабу". Поэтому в итоговом векторе
разброс значения может быть большим. По принятым в машинном обучении практикам, здесь в цепочку вычислений есть смысл добавить
. Во-вторых (2), мы для каждого слова склеиваем выходы нескольких голов, и они также могут быть очень разными по "масштабу". Поэтому в итоговом векторе
разброс значения может быть большим. По принятым в машинном обучении практикам, здесь в цепочку вычислений есть смысл добавить
Проблему (2) трансформеры решают с помощью
Наконец, авторы предлагают ещё один фокус, чтобы справиться с проблемой масштабирования: значения на каждой позиции преобразовывают двухслойным перцептроном с особой структурой. После применения многоголового внимания, они проецируют
на (абсурдно) высокую размерность с помощью обучаемых весов, где затем происходит преобразование нелинейной функцией активации ReLU, а потом значения проецируют в исходную размерность, за которой происходит очередная нормализация:

Итоговая схема трансформера выглядит так:

Архитектура "Трансформер" запросто делается ещё более глубокой, и это позволяет NLP-сообществу
GNN строят представления графов
Давайте на минуту отвлечёмся от NLP.
Графовые нейронные сети (GNN) или графовые свёрточные сети (GCN) строят представления вершин и рёбер на графовых данных. Делают это они с помощью агрегации значений соседей (или, иначе говоря, передачи сообщений). Каждая вершина собирает признаки соседних вершин, чтобы обновить собственное представление локальной структуры графа в её окрестности. Стекинг нескольких слоёв GNN позволяет модели распространять (propagate) признаки каждой вершины по всему графу — от соседей к соседям соседей — и так далее.

В самом простом виде GNN обновляют скрытые признаки
вершин
в слое
 путём нелинейного преобразования признаков
самой вершины, добавленных к агрегации признаков
путём нелинейного преобразования признаков
самой вершины, добавленных к агрегации признаков
 с каждой из соседних вершин
с каждой из соседних вершин
 :
:

где
 — обучаемые матрицы весов слоя GNN, а
— обучаемые матрицы весов слоя GNN, а
 — функция активации (как, например, ReLU). В примере —
— функция активации (как, например, ReLU). В примере —

Сложение по соседним вершинам
можно заменить другими функциями агрегации, не зависящими от количества аргументов, например, среднее/максимум или что-то ещё более выразительное — например, взвешенная сумма или
Звучит знакомо, не так ли?
Если нет, пайплайн поможет установить связь:
Предложения — полные графы, слова — вершины
Чтобы аналогия была более явной, представьте, что предложение — это полный граф, где каждое слово связано с каждым. Теперь можем использовать GNN, чтобы для каждой вершины (т.е. слова) графа (т.е. предложения) построить признаки, с помощью которых далее будем решать задачи обработки языка.

В целом, Трансформеры и представляют собой GNN с многоголовым вниманием в качестве функции агрегации соседей. Стандартные графовые сети агрегируют признаки вершин — непосредственных соседей
, а трансформеры для NLP работают со всем предложением
 как с соседями, агрегируя признаки каждого слова
на каждом слое.
как с соседями, агрегируя признаки каждого слова
на каждом слое.
Важно, что каждая из всевозможных хитростей, специально придуманных под задачу, вроде позиционного кодирования, агрегации с масками, расписания скорости обучения и массированного предобучения, — необходимая составляющая успеха трансформеров. При этом эти трюки редко встречаются в работах GNN-сообщества. В то же время, если посмотреть на трансформеры глазами специалиста по GNN, мы сможем избавиться от разных свистелок и излишеств в архитектуре.
Чему мы можем поучиться друг у друга?
Теперь, после того, как мы установили связь между трансформерами и графовыми нейронными сетями, давайте обсудим несколько идей.
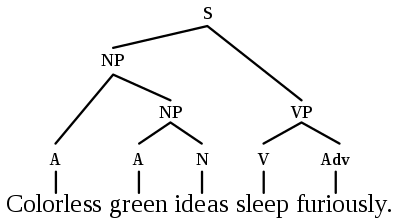
Полный граф — это что, лучший формат данных на входе для NLP?
До появления статистической обработки языка и машинного обучения лингвисты (в частности,
Как работать с дистантными зависимостями (long-term dependencies)?
С представлением в виде полных графов есть ещё одна проблема: так сложно работать с сильно удалёнными друг от друга связями между словами. Дело в том, что количество рёбер в полных графах квадратично зависит от числа вершин, и с ростом числа последних увеличивается очень быстро, то есть в предложении с
 словами трансформер или GNN будут совершать вычисления для
словами трансформер или GNN будут совершать вычисления для
 пар слов. Всё летит в просто выходит из-под контроля для очень больших значений
.
пар слов. Всё летит в просто выходит из-под контроля для очень больших значений
.
Очень интересно видение NLP-сообщества, что делать с длинными последовательностями и дистантными зависимостями. Предлагается сделать внимание
Было бы здорово посмотреть и что получится, если в ход пойдут и идеи от тех, кто занимается GNN. К примеру, интересно было бы попробовать применить

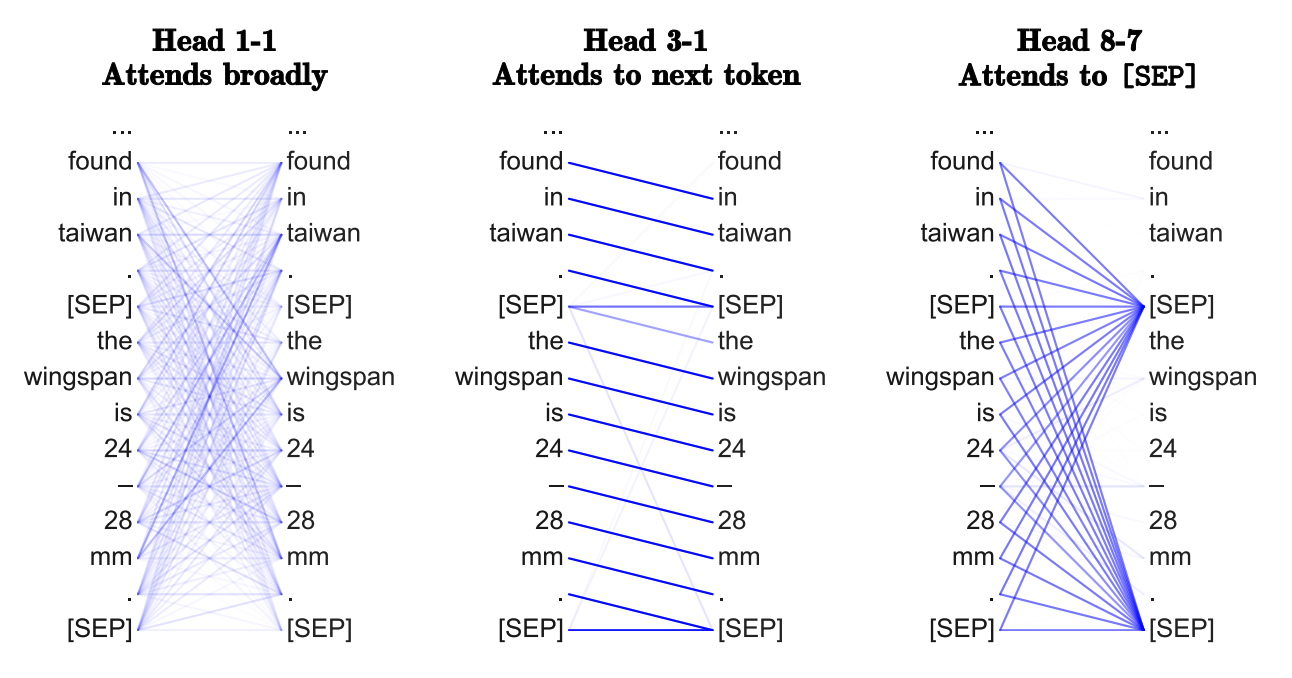
Понимают ли трансформеры "нейронный синтаксис"?
В NLP-мире вышло
И, вероятно, разные головы в многоголовом внимании смотрят на разные "синтаксические свойства".
Если переводить на "графовый" язык — используя GNN на полных графах, можем ли мы выделить наиболее важные рёбра (а с ними и связи, за которые они отвечают) на основе того, как GNN выполняют агрегацию на каждом из слоёв? Пока что меня в этом
Почему голов внимания несколько? Зачем вообще нужно внимание?
Мне больше нравится воспринимать механизм многоголового внимания как оптимизационную задачу. С несколькими головами обучение идёт лучше, и преодолевается проблемы, возникающие из-за "неудачной" инициализации. Например, в
Механизмы "многоголовой" агрегации соседей демонстрируют эффективность и в GNN, например GAT использует многоголовое внимание, а
Вопреки ожиданиям, GNN с куда более простыми функциями агрегации (например, сумма или максимум) не нуждаются в нескольких головах для стабильного обучения. Вот бы трансформерам не нужно было вычислять "величины совместимости" для каждой пары слов в предложении!
Могут ли трансформеры что-то приобрести, избавившись от механизма внимания? В

Почему так трудно обучать трансформеры?
Читая свежие статьи о трансформерах, не могу отделаться от ощущения, что обучение этих моделей требует навыков, близких к чёрной магии, когда дело доходит до определения лучшего расписания скорости обучения (learning rate schedule), способа "разогрева" (warmup strategy) и настроек затухания (decay settings). Возможно, это от того, что модели — гигантские, а рассматриваемые задачи — не из числа простых.
Но вот

В твите я, конечно, просто ворчу, но вот что вызывает мой скепсис: неужели нам и правда так нужны все эти головы вычислительно дорогого попарного внимания, наделённые чрезмерно большим числом параметров "перцептронные подслои" и хитроумные расписания обучения?
Неужели нам настолько необходимы огромные модели с внушительным
Может, сети будет проще обучить, если мы в их архитектуры намеренно внесём
Что ещё почитать
Если хотите получше разобраться в трансформерах с точки зрения задач обработки языка, рекомендую посмотреть вот эти действительно грамотно написанные посты:
Мы не первые связываем GNN с трансформерами: есть
В следующем посте мы, наоборот, будем использовать GNN как трансформеры для NLP (возьмём за основу библиотеку HuggingFace:
И, наконец, мы недавно
Дополнение
Пост был также переведён на
You must be registered for see links
" (12 февраля 2020 года), проливающий свет на схожесть устройства GNN и Transformer: схемы, формулы, идеи, важные ссылки. Публикуется с любезного разрешения автора поста.
Друзья-датасаентисты часто задают один и тот же вопрос: графовые нейронные сети (Graph Neural Networks) — прекрасная идея, но были ли у них хоть какие-то настоящие истории успеха? Есть ли у них какие-нибудь полезные на практике приложения?
Можно привести в пример и без того известные варианты — рекомендательные системы в
You must be registered for see links
,
You must be registered for see links
и
You must be registered for see links
. Но есть и более хитрая история успеха:
You must be registered for see links
You must be registered for see links
You must be registered for see links
You must be registered for see links
You must be registered for see links
You must be registered for see links
архитектура
You must be registered for see links
.В этом посте мне бы хотелось установить связи между
You must be registered for see links
и трансформерами (Transformers). Мы поговорим об интуитивном обосновании архитектур моделей в NLP- и GNN-сообществах, покажем их связь на языке формул и уравнений и порассуждаем, как оба "мира" могут объединить усилия, чтобы продвинуть прогресс.Начнём с обсуждения основной цели разработки архитектур разных моделей — с обучения представлений (representation learning).
Обучение представлений для NLP
Так или иначе все нейросетевые архитектуры строят представления входных данных в виде векторов, которые "кодируют" полезные статистические и семантические свойства этих данных. Эти латентные (скрытые) (latent/hidden) представления можно затем переиспользовать для какой-нибудь полезной задачи. Например, для классификации изображений или перевода предложений. Нейронные сети обучают представления всё лучше и лучше благодаря обратной связи, которую они обычно получают в виде значений функций потерь (error/loss functions).
Принято, что в обработке естественного языка (natural language processing; NLP), рекуррентные нейронные сети (recurrent neural networks; RNN) для каждого слова в предложении строят отдельное представление — шаг за шагом, по одному слову. Можно представить себе RNN как ленту конвейера, на которой слова обрабатываются авторегрессивно слева направо. В итоге на каждое слово в предложении получаем вектор скрытых представлений, которые мы либо передаём на следующий слой RNN, либо используем для нашей целевой задачи.
Настоятельно рекомендую знаменитый блог Кристофера Олаха, если нужно вспомнить,
You must be registered for see links
и
You must be registered for see links
(
You must be registered for see links
на русский) для обработки естественного языка.
Трансформеры были изначально разработаны для машинного перевода и постепенно заменили RNN в основных задачах NLP. В архитектуру заложен свежий подход к обучению представлений: полностью избавившись от рекуррентности, трансформеры для каждого слова строят признаки, используя для этого
You must be registered for see links
You must be registered for see links
(attention mechanism; attention), чтобы выявить важность всех прочих слов в предложении для данного слова. Таким образом, построенные признаки для данного слова — просто сумма линейных преобразований признаков всех слов, взвешенных этой "важностью".В далёком 2017 году эта мысль казалось очень радикальной, так как в сообществе NLP все привыкли к последовательной — по слову за раз — обработке текста с помощью RNN. Название статьи, пожалуй, тоже подлило немало масла в огонь!
Можно вспомнить подробности, посмотрев
Можно вспомнить подробности, посмотрев
You must be registered for see links
Yannic Kilcher.Трансформер по частям
Давайте переведём наше интуитивное описание архитектуры в прошлом абзаце на язык формул. Так,
где за
Механизм внимания легче понять, рассмотрев следующую цепочку шагов:
Взяв признаки для данного слова
и множество других слов в предложении
 вычислим веса механизма внимания
для каждой пары
вычислим веса механизма внимания
для каждой пары
 как скалярное произведение, после которого применим softmax вдоль всех
как скалярное произведение, после которого применим softmax вдоль всех
 . Наконец, на выходе получим обновлённые признаки
для слова
, складывая по всем
, взвешенным соответствующими
. Каждое слово в предложении параллельно проходит через одну и ту же цепочку вычислений.
. Наконец, на выходе получим обновлённые признаки
для слова
, складывая по всем
, взвешенным соответствующими
. Каждое слово в предложении параллельно проходит через одну и ту же цепочку вычислений.
Многоголовое внимание (Multi-Head Attention)
Не так-то просто заставить работать внимание-на-скалярном-произведении (dot product attention): неудачная инициализация случайными значениями может дестабилизировать процесс обучения. С этим справляются, одновременно вычисляя внимание сразу несколькими "головами" (attention heads) и склеивая (конкатенируя) результаты (при этом у каждой "головы" свои обучающиеся веса):
где
В сущности, несколько "голов" позволяют механизму внимания "сделать сразу несколько ставок", давая возможность смотреть на разные преобразования или аспекты признаков с предыдущего слоя. Мы ещё поговорим об этом позже.
Проблемы масштабирования и "подслой" прямого распространения
Scale issues and the Feed-forward sub-layer
Ключевая проблема, из-за которой архитектура трансформеров устроена именно так, как устроена, заключается вот в чём: значения признаков для каждого слова после применения механизма внимания могут быть очень разными по величине. Во-первых (1), это может быть из-за слишком "острых пиков" или, напротив, равномерности в распределении внимания
You must be registered for see links
(normalization layer).Проблему (2) трансформеры решают с помощью
You must be registered for see links
, который нормализовает и выучивает аффинное преобразование на уровне признаков. Кроме того, деление внимания-на-скалярном-произведении на квадратный корень из размерности помогает противодействовать проблеме (1).Наконец, авторы предлагают ещё один фокус, чтобы справиться с проблемой масштабирования: значения на каждой позиции преобразовывают двухслойным перцептроном с особой структурой. После применения многоголового внимания, они проецируют
Честно говоря, мне неочевидно, какими интуитивными соображениями руководствовались авторы, придумывая полносвязный подслой с чрезмерно большим числом параметров. И как будто пока никто и не спрашивал! Я подозреваю, что одни только LayerNorm и отмасштабированные скалярные произведения не вполне справлялись с описанными выше проблемами. Так что большой многослойный перцептрон — это просто хак, чтобы перемасштабировать векторы признаков независимо друг от друга.
Напишите мне на почту, если вам есть что об этом сказать!
Напишите мне на почту, если вам есть что об этом сказать!
Итоговая схема трансформера выглядит так:
Архитектура "Трансформер" запросто делается ещё более глубокой, и это позволяет NLP-сообществу
You must be registered for see links
You must be registered for see links
, и размеры датасетов. Ключевой деталью, позволяющей ставить ("стЕкать") слои трансформера друг на друга, являются остаточные связи (residual connections) между входами и выходами каждого "подслоя" многоголового внимания и полносвязного "подслоя". На диаграмме они не отображены для ясности изложения всего остального.GNN строят представления графов
Давайте на минуту отвлечёмся от NLP.
Графовые нейронные сети (GNN) или графовые свёрточные сети (GCN) строят представления вершин и рёбер на графовых данных. Делают это они с помощью агрегации значений соседей (или, иначе говоря, передачи сообщений). Каждая вершина собирает признаки соседних вершин, чтобы обновить собственное представление локальной структуры графа в её окрестности. Стекинг нескольких слоёв GNN позволяет модели распространять (propagate) признаки каждой вершины по всему графу — от соседей к соседям соседей — и так далее.
Рассмотрим, к примеру, эту социальную сеть из эмоджи: признаки при каждой вершине, обученные с помощью GNN, можно использовать для предсказаний: выделить наиболее влиятельных участников сети или предложить провести потенциально "полезное" ребро.
В самом простом виде GNN обновляют скрытые признаки
где
Сложение по соседним вершинам
You must be registered for see links
.Звучит знакомо, не так ли?
Если нет, пайплайн поможет установить связь:
Если мы несколько раз параллельно делаем агрегацию соседей и заменяем простое сложение по соседям
механизмом внимания, то есть взвешенной суммой, мы получит Graph Attention Network (GAT). А если добавить нормализацию и многослойный перцептрон, то — вуаля — мы получим "графовый" трансформер!
Предложения — полные графы, слова — вершины
Чтобы аналогия была более явной, представьте, что предложение — это полный граф, где каждое слово связано с каждым. Теперь можем использовать GNN, чтобы для каждой вершины (т.е. слова) графа (т.е. предложения) построить признаки, с помощью которых далее будем решать задачи обработки языка.
В целом, Трансформеры и представляют собой GNN с многоголовым вниманием в качестве функции агрегации соседей. Стандартные графовые сети агрегируют признаки вершин — непосредственных соседей
Важно, что каждая из всевозможных хитростей, специально придуманных под задачу, вроде позиционного кодирования, агрегации с масками, расписания скорости обучения и массированного предобучения, — необходимая составляющая успеха трансформеров. При этом эти трюки редко встречаются в работах GNN-сообщества. В то же время, если посмотреть на трансформеры глазами специалиста по GNN, мы сможем избавиться от разных свистелок и излишеств в архитектуре.
Чему мы можем поучиться друг у друга?
Теперь, после того, как мы установили связь между трансформерами и графовыми нейронными сетями, давайте обсудим несколько идей.
Полный граф — это что, лучший формат данных на входе для NLP?
До появления статистической обработки языка и машинного обучения лингвисты (в частности,
You must be registered for see links
) работали в том числе над построением теорий о синтаксическом устройстве преддложения: синтаксические деревья, графы и так далее. К этому уже пробовали подбираться с помощью TreeLSTM, но, может, трансформеры/GNN лучше подходят для сближения лингвистических теорий и статистического NLP?
Как работать с дистантными зависимостями (long-term dependencies)?
С представлением в виде полных графов есть ещё одна проблема: так сложно работать с сильно удалёнными друг от друга связями между словами. Дело в том, что количество рёбер в полных графах квадратично зависит от числа вершин, и с ростом числа последних увеличивается очень быстро, то есть в предложении с
Очень интересно видение NLP-сообщества, что делать с длинными последовательностями и дистантными зависимостями. Предлагается сделать внимание
You must be registered for see links
или
You must be registered for see links
в плане длины входа, добавить
You must be registered for see links
или
You must be registered for see links
в каждый слой и использовать
You must be registered for see links
для эффективного вычисления внимания. Все эти идеи выглядят многообещающими способами улучшить трансформеры.Было бы здорово посмотреть и что получится, если в ход пойдут и идеи от тех, кто занимается GNN. К примеру, интересно было бы попробовать применить
You must be registered for see links
(Binary Partitioning) для прореживания "графа предложения".
Понимают ли трансформеры "нейронный синтаксис"?
В NLP-мире вышло
You must be registered for see links
You must be registered for see links
You must be registered for see links
о том, что, возможно, выучивают трансформеры. Основная предпосылка в том, что применение внимания ко всем парам слов в предложении — чтобы определить, какие из них наиболее ценны, — позволяет трансформерам выучивать что-то вроде особого "синтаксиса под целевую задачу".И, вероятно, разные головы в многоголовом внимании смотрят на разные "синтаксические свойства".
Если переводить на "графовый" язык — используя GNN на полных графах, можем ли мы выделить наиболее важные рёбра (а с ними и связи, за которые они отвечают) на основе того, как GNN выполняют агрегацию на каждом из слоёв? Пока что меня в этом
You must be registered for see links
.
Почему голов внимания несколько? Зачем вообще нужно внимание?
Мне больше нравится воспринимать механизм многоголового внимания как оптимизационную задачу. С несколькими головами обучение идёт лучше, и преодолевается проблемы, возникающие из-за "неудачной" инициализации. Например, в
You must be registered for see links
You must be registered for see links
показано, что часть голов трансформеров можно исключить после обучения без существенного влияния на качество предсказаний.Механизмы "многоголовой" агрегации соседей демонстрируют эффективность и в GNN, например GAT использует многоголовое внимание, а
You must be registered for see links
использует несколько гауссовских ядер (Gaussian kernels) для агрегации признаков. Подход с дополнением модели несколькими головами был придуман для стабилизации механизмов внимания. Станет ли он стандартным способом "выжать" из модели ещё немного?Вопреки ожиданиям, GNN с куда более простыми функциями агрегации (например, сумма или максимум) не нуждаются в нескольких головах для стабильного обучения. Вот бы трансформерам не нужно было вычислять "величины совместимости" для каждой пары слов в предложении!
Могут ли трансформеры что-то приобрести, избавившись от механизма внимания? В
You must be registered for see links
You must be registered for see links
Yann Dauphin и его коллег предлагается альтернативная трансформеру архитектура на свёрточных сетях (ConvNet). В конечном итоге, возможно, трансформеры работают
You must be registered for see links
и
You must be registered for see links
!
Почему так трудно обучать трансформеры?
Читая свежие статьи о трансформерах, не могу отделаться от ощущения, что обучение этих моделей требует навыков, близких к чёрной магии, когда дело доходит до определения лучшего расписания скорости обучения (learning rate schedule), способа "разогрева" (warmup strategy) и настроек затухания (decay settings). Возможно, это от того, что модели — гигантские, а рассматриваемые задачи — не из числа простых.
Но вот
You must be registered for see links
You must be registered for see links
You must be registered for see links
о том, что, может быть, дело в особых перестановках нормализации и остаточных связей внутри самой архитектуры.
Получил удовольствие от чтения новой статьи про DeepMind-овский трансформер, но почему всё-таки обучение этих моделей такая темная магия? "Для языкового моделирования на уровне слов мы использовали 16 000 шагов "разогрева" (warmup), 500 000 шагов "затухания" (decay), а также принесли в жертву 9 000 коз".
В твите я, конечно, просто ворчу, но вот что вызывает мой скепсис: неужели нам и правда так нужны все эти головы вычислительно дорогого попарного внимания, наделённые чрезмерно большим числом параметров "перцептронные подслои" и хитроумные расписания обучения?
Неужели нам настолько необходимы огромные модели с внушительным
You must be registered for see links
?Может, сети будет проще обучить, если мы в их архитектуры намеренно внесём
You must be registered for see links
(inductive bias), подобранные под целевую задачу?Что ещё почитать
Если хотите получше разобраться в трансформерах с точки зрения задач обработки языка, рекомендую посмотреть вот эти действительно грамотно написанные посты:
You must be registered for see links
и
You must be registered for see links
.Мы не первые связываем GNN с трансформерами: есть
You must be registered for see links
Arthur Szlam об истории и связями между Attention/Memory Networks, GNN и трансформерами. Есть также
You must be registered for see links
, некоторые авторы которой — настоящие знаменитости и в которой вводится объединяющий все эти идеи "фреймворк" — графовые сети. А в код можно посмотреть, например, в хорошем
You must be registered for see links
. Там рассматривают seq2seq как задачу для "графовых" методов и "строят" трансформеры как GNN.В следующем посте мы, наоборот, будем использовать GNN как трансформеры для NLP (возьмём за основу библиотеку HuggingFace:
You must be registered for see links
).И, наконец, мы недавно
You must be registered for see links
, в которой применяем трансформеры к датасету с эскизами
You must be registered for see links
. Зацените!Дополнение
Пост был также переведён на
You must be registered for see links
. Присоединяйтесь к его обсуждению на
You must be registered for see links
и в
You must be registered for see links
!Перевод с английского языка: Антон Алексеев
(лаб. искусственного интеллекта, ПОМИ РАН им. В.А. Стеклова)
За ценные замечания переводчик благодарит Дениса Кирьянова
(лаб. искусственного интеллекта, ПОМИ РАН им. В.А. Стеклова)
За ценные замечания переводчик благодарит Дениса Кирьянова
You must be registered for see links
и Михаила Евтихиева
You must be registered for see links
.