
Оффлайн
- Регистрация
- 21.07.20
- Сообщения
- 40.408
- Реакции
- 1
- Репутация
- 0
Сложно найти на Хабре человека, который не слышал бы про нейронные сети. Регулярные новости о свежих достижениях нейронных сетей заставляют удивляться широкую публику, а также привлекают новых энтузиастов и исследователей. Привлеченный поток специалистов способствует не только еще большим успехам нейронных моделей, но и приводит к развитию инструментов для более удобного использования Deep Learning подходов. Помимо всем известных фреймворков Tensorflow и PyTorch активно развиваются и другие библиотеки, нередко более гибкие, но менее известные.
Эта статья является переводом одного из постов

Где создается и обсуждается передовое глубокое обучение?
Одним из главных мест обсуждения Deep Learning является
Виртуальные социальные встречи были одной из изюминок ICLR 2020. Организаторы решили запустить проект под названием «Open source tools and practices in state-of-the-art DL research». Тема была выбрана из-за того, что соответствующий инструментарий является неизбежной частью работы исследователя глубокого обучения. Достижения в этой области привели к распространению крупных экосистем (
Цель упомянутого мероприятия заключалась во встрече с создателями и пользователями инструментов с открытым исходным кодом, а также в обмене опытом и впечатлениями среди сообщества Deep Learning. В общей сложности было собрано более 100 человек, включая основных вдохновителей и руководителей проектов, которым мы дали короткие промежутки времени для представления своей работы. Участники и организаторы были удивлены широким разнообразием и креативностью представленных инструментов и библиотек.
В этой статье собраны яркие проекты, представленные с виртуальной сцены.
Инструменты и библиотеки
Далее будут рассмотрены восемь инструментов, которые были продемонстрированы на ICLR с подробным обзором возможностей.
Каждый раздел представляет ответы на ряд пунктов в очень сжатой форме:
Вы можете перейти к конкретному разделу ниже или просто просмотреть их все один за другим. Наслаждайтесь чтением!
AmpliGraph
Тема: Модели эмбеддингов на основе Knowledge Graph.
Язык программирования: Python
Автор: Люка Костабелло
Графы знаний являются универсальным инструментом для представления сложных систем. Будь то социальная сеть, набор данных биоинформатики или данные о розничных покупках, моделирование знаний в виде графа позволяет организациям выявить важные связи, которые в противном случае были бы упущены из виду.
Для выявления связей между данными требуются особые модели машинного обучения, специально разработанные для работы с графами.
AmpliGraph снижает исследователям барьер входа для темы графовых эмбеддингов, делая упомянутые модели доступными для неопытных пользователей. Благодаря преимуществу API с открытым исходным кодом, проект поддерживает сообщество энтузиастов, использующих графы в машинном обучении. Проект позволяет узнать, как создавать и визуализировать эмбеддинги из графов знаний на основе данных реального мира и как использовать их в последующих задачах машинного обучения.
Для начала работы ниже приводится минимальный фрагмент кода, обучающий модель на одном из эталонных датасетов и прогнозирующий недостающие связи:

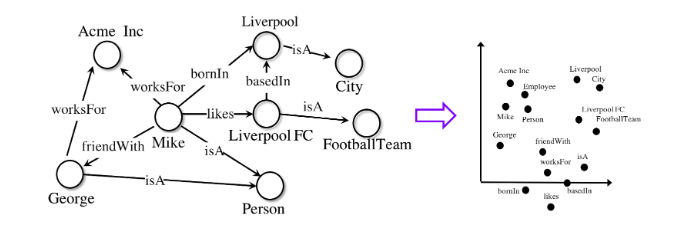
Модели машинного обучения AmpliGraph генерируют графовые эмбеддинги, представления в векторном пространстве.

Далее эмбеддинги объединяются со специальными функциями для того, что прогнозировать новые и не замеченные ранее связи.
AmpliGraph изначально был разработан в
Automunge
Платформа подготовки табличных данных
Язык программирования: Python
Автор: Николас Тиг
Проще говоря:
automunge (.) подготавливаются табличные данные для использования в машинном обучении,
postmunge (.) последовательно и с высокой эффективностью обрабатываются дополнительные данные.
Automunge доступен для установки посредством pip:

После установки достаточно импортировать библиотеку в Jupyter Notebook для инициализации:

Для автоматической обработки данных из тренировочной выборки с параметрами по умолчанию достаточно использовать команду:

Далее для последующей обработки данных из тестовой подвыборки, достаточно запустить команду, использующую словарь postprocess_dict, полученный вызовом automunge (.) выше:

С помощью параметров assigncat и assigninfill в вызове automunge (.) могут быть определены детали преобразований и типы данных для заполнения пропусков. Например, для набора данных со столбцами 'column1' и 'column2' можно назначить масштабирование на основе минимальных и максимальных значений ('mnmx') с ML-заполнением пропусков для column1 и one-hot encoding ('text') с заполнением пропусков на основе наиболее часто встречающегося значения для column2. Не указанные в явном виде данные из других столбцов будут обрабатываться автоматически.

Ресурсы и ссылки
DynaML
Машинное обучение для Scala
Язык программирования: Scala
Автор: Мандар Чандоркар
DynaML — это набор инструментов для исследований и машинного обучения на основе Scala. Он направлен на предоставление пользователю сквозной среды, которая может помочь в:
DynaML использует сильные стороны языка и экосистемы Scala для создания среды, обеспечивающей производительность и гибкость. Он основан на таких превосходных проектах, как
Ключевым компонентом DynaML является REPL / оболочка, которая имеет подсветку синтаксиса и продвинутую систему автозаполнения.
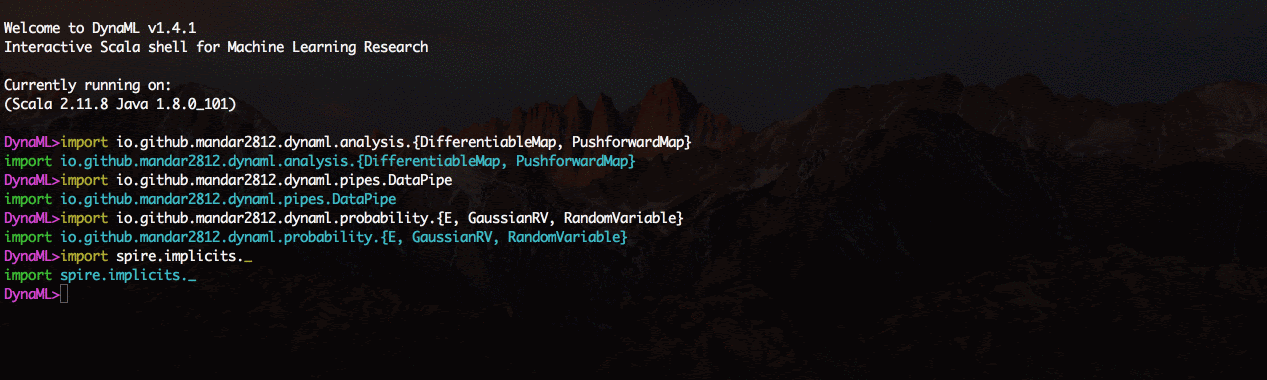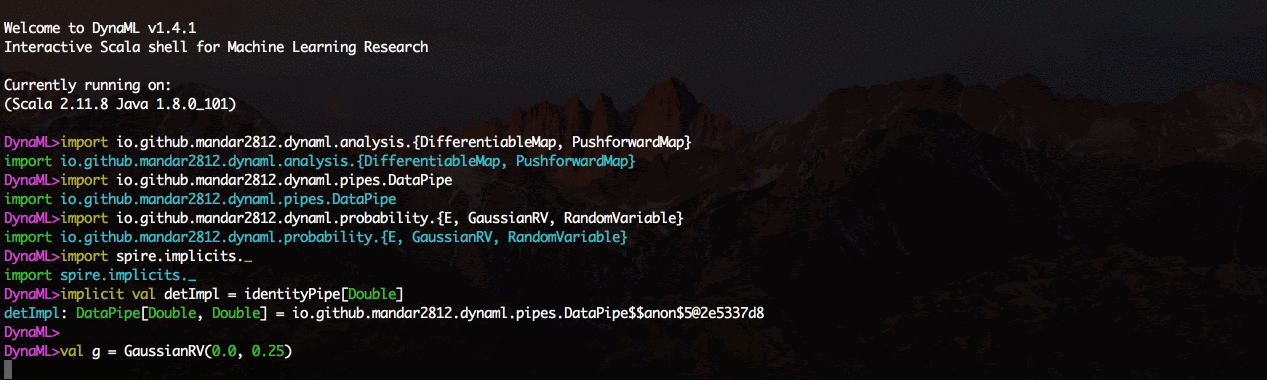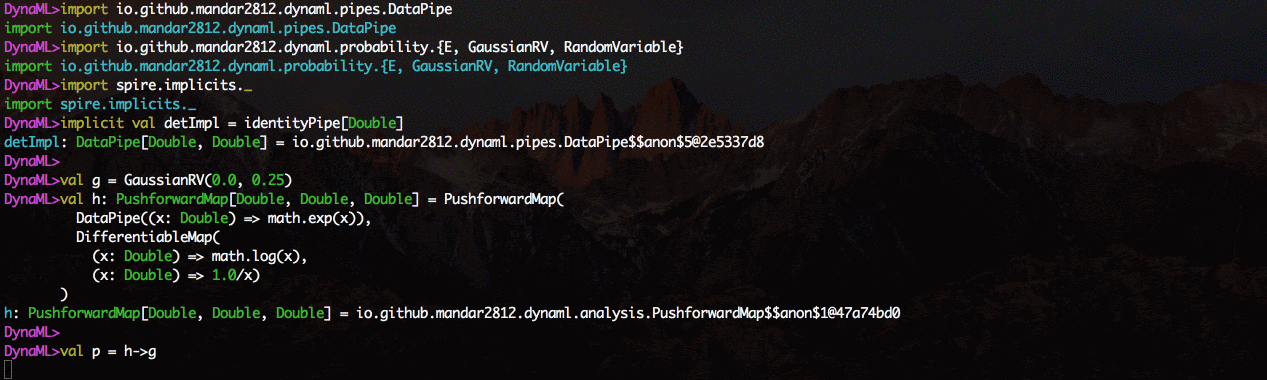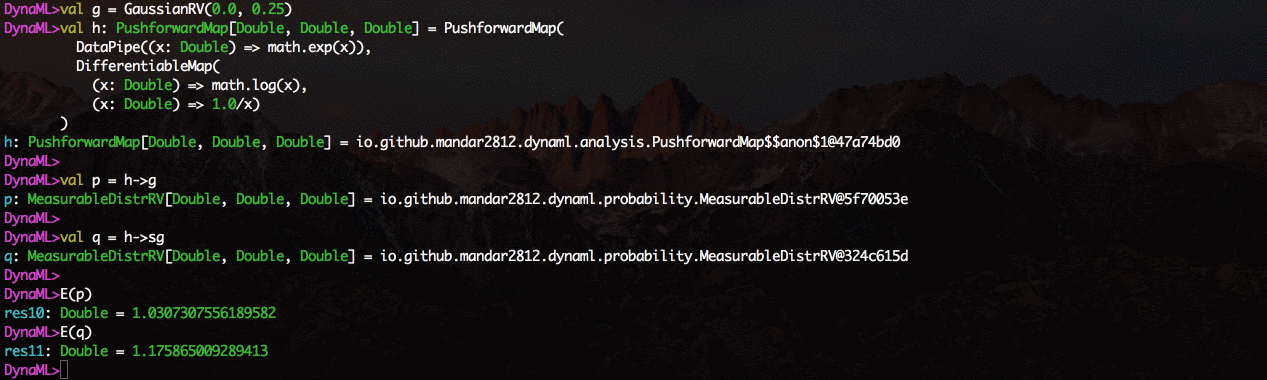
Скопируйте и вставьте фрагменты кода в командную строку, чтобы запустить их.
Среда поставляется с поддержкой 2D и 3D-визуализации, результаты могут быть отображены непосредственно из командной оболочки.

3D-диаграммы отображаются с помощью Java API
Модуль
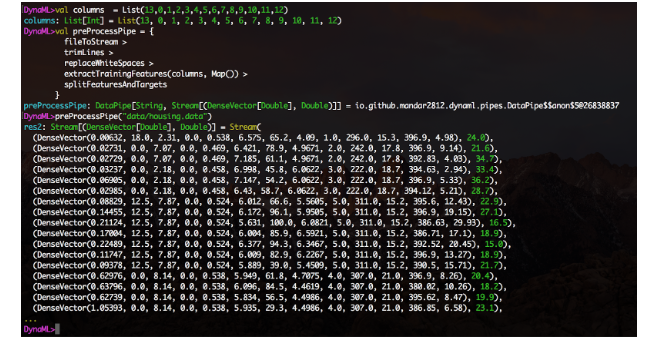
Обработка потоков данных выглядит интуитивно понятной, когда pipeline логически делится на этапы, а на каждом шаге выполняется одно единственное преобразование.
Также доступна экспериментальная функция интеграции c Jupyter notebook, каталог notebooks в репозитории содержит несколько примеров использования ядра DynaML-Scala Jupyter.

Notebook c
Ниже приводятся некоторые интересные приложения, которые подчеркивают сильные стороны DynaML:
Ресурсы и ссылки
*****
Configuration and parameters manager
Язык программирования: Python
Автор: Омры Ядан
Разработанная в Facebook AI, ***** — платформа Python, которая упрощает разработку исследовательских приложений, предоставляя возможность создавать и переопределять конфигурации с помощью конфигурационных файлов и командной строки. Платформа также обеспечивает поддержку автоматической развертки параметров, удаленное и параллельное выполнение посредством плагинов, автоматическое управление рабочим каталогом и динамическое предложение вариантов дополнения с помощью нажатия клавиши TAB.
Использование ***** также делает ваш код более переносимым в различных средах машинного обучения. Позволяет вам переключаться между личными рабочими станциями, общедоступными и частными кластерами без изменения кода. Описанное выше достигается путем модульной архитектуры.
Основной пример
В приведенном примере используется конфигурация базы данных, но вы можете легко заменить ее моделями, датасетами или чем-либо еще по необходимости.
config.yaml:

my_app.py:

Вы можете переопределить что угодно в конфигурации из командной строки:

Пример композиции:
Возможно, вы захотите переключаться между двумя разными конфигурациями баз данных.
Создать эту структуру директорий:

config.yaml:
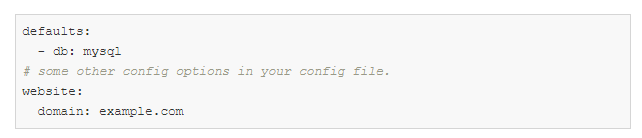
defaults — это специальная директива, указывающая ***** использовать db / mysql.yaml при составлении объекта конфигурации.
Теперь вы можете выбрать, какую использовать конфигурацию базы данных, а также переопределить значения параметров из командной строки:

Ознакомьтесь с
Кроме того, в ближайшее время появятся новые интересные функции:
Larq
Бинаризованные нейронные сети
Язык программирования: Python
Автор: Лукас Гайгер
Larq — это экосистема пакетов Python с открытым исходным кодом для построения, обучения и развертывания бинаризованных нейронных сетей (BNN). BNN — это модели глубокого обучения, в которых активации и веса кодируются не с использованием 32, 16 или 8 бит, а с использованием только 1 бита. Это может значительно ускорить время логического вывода и снизить энергопотребление, что делает BNN идеально подходящими для мобильных и периферийных устройств.
Экосистема Larq с открытым исходным кодом состоит из трех основных компонентов.
Авторы проекта постоянно создают более быстрые модели и расширяют экосистему Larq на новые аппаратные платформы и приложения для глубокого обучения. Например, в настоящее время идет работа над сквозной интеграцией восьмиразрядного квантования, чтобы была возможность обучать и развертывать комбинации двоичных и восьмиразрядных сетей, используя Larq.
Ресурсы и ссылки
McKernel
Ядерные методы в логарифмически линейное время
Язык программирования: C/C++
Автор: J. de Curtó i Díaz
Первая библиотека C++ с открытым исходным кодом, предоставляющая как аппроксимацию ядерных методов на основе случайных признаков, так и полноценный Deep Learning фреймворк.
McKernel предоставляет четыре различные возможности использования.
Уравнение, описывающее все вычисления, выглядит следующим образом:

Здесь авторы в качестве первопроходцев применяют формализм для объяснения с помощью случайных признаков как
С прицелом на типичного пользователя
Основной аудиторией McKernel являются исследователи и практические специалисты в области робототехники, машинного обучения для здравоохранения, обработки сигналов и коммуникаций, которые нуждаются в эффективной и быстрой реализации на C++. В описанном случае большинство библиотек Deep Learning не удовлетворяют заданным условиям, поскольку они по большей части основаны на высокоуровневых реализациях на Python. Кроме того, аудиторией могут быть представители более широкого сообщества машинного обучения и Deep Learning, которые пребывают в поиске улучшения архитектуры нейронных сетей, используя ядерные методы.
Сверхпростой наглядный пример для запуска библиотеки без затрат времени выглядит следующим образом:

Что дальше?
Сквозное обучение, self-supervised learning, meta-learning, интеграция с эволюционными стратегиями, существенное сокращение пространства поиска с помощью NAS ,…
Ресурсы и ссылки
SCCH Training Engine
Подпрограммы для автоматизации Deep Learning
Язык программирования: Python
Автор: Наталья Шепелева
Разработка типичного pipeline для Deep Learning довольно стандартна: предварительная обработка данных, проектирование/реализация задачи, обучение модели и оценка результата. Тем не менее, от проекта к проекту его использование требует участия инженера на каждом этапе разработки, что ведет к повторению одних и тех же действий, дублированию кода и в конце концов приводит к ошибкам.
Целью SCCH Training Engine является унификация и автоматизация процедуры Deep Learning разработки для двух самых популярных фреймворков PyTorch и TensorFlow. Архитектура с одним входом позволяет минимизировать время разработки и защищает от программных ошибок.
Для кого?
Гибкая архитектура SCCH Training Engine обладает двумя уровнями взаимодействия с пользователем.
Основной. На этом уровне пользователь должен предоставить данные для тренировки и прописать параметры тренировки модели в файле конфигурации. После этого все процессы, включая обработку данных, обучение модели и валидацию результатов будут выполнены в автоматическом режиме. В результате будет получена обученная модель в рамках одного из основных фреймворков.
Продвинутый. Благодаря модульной концепции компонент, пользователь может модифицировать модули в соответствии со своими потребностями, разворачивая свои собственные модели и используя различные функции потерь и метрики качества. Подобная модульная архитектура позволяет добавлять дополнительные признаки, не мешая работе основного pipeline-а.
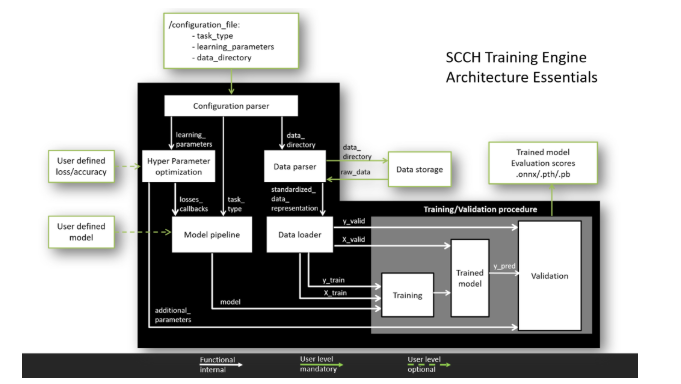
Что он может делать?
Текущие возможности:
Возможности на стадии разработки:
Как это работает?
Чтобы увидеть SCCH Training Engine во все красе, вам нужно сделать два шага.
Всю информацию о том, как создать файл конфигурации и как использовать продвинутые возможности, можно найти на странице
Стабильный релиз с основными функциями: был запланирован на конец мая 2020 г.
Ресурсы и ссылки
Tokenizers
Текстовые токенизаторы
Язык программирования: Rust с Python API
Автор: Энтони Муа
Ключевые особенности
Пример:

И скоро:
Ресурсы и ссылки
Заключение
В заключении необходимо отметить, что есть большое количество библиотек, полезных для Deep Learning и машинного обучения в целом, и нет возможности описать в одной статье все их множество. Некоторые из описанных выше проектов будут полезны в специфических случаях, некоторые являются и так достаточно известными, а некоторые замечательные проекты, к сожалению не попали в статью.
Мы в компании
Уверен, что у каждого практикующего специалиста есть свои излюбленные инструменты и библиотеки, в том числе и малоизвестные широкой аудитории. Если вам кажется, что какие-либо полезные в работе инструменты были напрасно обойдены вниманием, то напишите их, пожалуйста, в комментариях: даже упоминание в обсуждении поможет перспективным проектам привлечь новых последователей, а прирост популярности в свою очередь приводит к улучшению функционала и развитию самих библиотек.
Благодарю за внимание и надеюсь, что представленный набор библиотек окажется полезным в вашей работе!
Эта статья является переводом одного из постов
You must be registered for see links
и освещает самые интересные инструменты для глубокого обучения, представленные на конференции по машинному обучения
You must be registered for see links
2020.
Где создается и обсуждается передовое глубокое обучение?
Одним из главных мест обсуждения Deep Learning является
You must be registered for see links
— ведущая конференция по глубокому обучению, которая состоялась 27-30 апреля 2020 года. Более 5500 участников и почти 700 презентаций и докладов — это большой успех для полностью онлайн-мероприятия. Найти исчерпывающую информацию о конференции вы можете
You must be registered for see links
,
You must be registered for see links
или
You must be registered for see links
.Виртуальные социальные встречи были одной из изюминок ICLR 2020. Организаторы решили запустить проект под названием «Open source tools and practices in state-of-the-art DL research». Тема была выбрана из-за того, что соответствующий инструментарий является неизбежной частью работы исследователя глубокого обучения. Достижения в этой области привели к распространению крупных экосистем (
You must be registered for see links
,
You must be registered for see links
, MXNet), а также более мелких целевых инструментов, отвечающих за решение конкретных потребностей исследователей.Цель упомянутого мероприятия заключалась во встрече с создателями и пользователями инструментов с открытым исходным кодом, а также в обмене опытом и впечатлениями среди сообщества Deep Learning. В общей сложности было собрано более 100 человек, включая основных вдохновителей и руководителей проектов, которым мы дали короткие промежутки времени для представления своей работы. Участники и организаторы были удивлены широким разнообразием и креативностью представленных инструментов и библиотек.
В этой статье собраны яркие проекты, представленные с виртуальной сцены.
Инструменты и библиотеки
Далее будут рассмотрены восемь инструментов, которые были продемонстрированы на ICLR с подробным обзором возможностей.
Каждый раздел представляет ответы на ряд пунктов в очень сжатой форме:
- Какую проблему решает инструмент / библиотека?
- Как запустить или создать минимальный пример использования?
- Внешние ресурсы для более глубокого погружения в библиотеку / инструмент.
- Профиль представителей проекта на случай, если будет желание к ним обратиться.
Вы можете перейти к конкретному разделу ниже или просто просмотреть их все один за другим. Наслаждайтесь чтением!
AmpliGraph
Тема: Модели эмбеддингов на основе Knowledge Graph.
Язык программирования: Python
Автор: Люка Костабелло
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
Графы знаний являются универсальным инструментом для представления сложных систем. Будь то социальная сеть, набор данных биоинформатики или данные о розничных покупках, моделирование знаний в виде графа позволяет организациям выявить важные связи, которые в противном случае были бы упущены из виду.
Для выявления связей между данными требуются особые модели машинного обучения, специально разработанные для работы с графами.
You must be registered for see links
— это набор моделей машинного обучения под лицензией Apache2 для извлечения эмбеддингов из графов знаний. Такие модели кодируют узлы и ребра графа в вектором виде и объединяют их для предсказания недостающих фактов. Графовые эмбеддинги применяются в таких задачах, как в довершение графа знаний, обнаружение знаний, кластеризация на основе связей и другие.AmpliGraph снижает исследователям барьер входа для темы графовых эмбеддингов, делая упомянутые модели доступными для неопытных пользователей. Благодаря преимуществу API с открытым исходным кодом, проект поддерживает сообщество энтузиастов, использующих графы в машинном обучении. Проект позволяет узнать, как создавать и визуализировать эмбеддинги из графов знаний на основе данных реального мира и как использовать их в последующих задачах машинного обучения.
Для начала работы ниже приводится минимальный фрагмент кода, обучающий модель на одном из эталонных датасетов и прогнозирующий недостающие связи:
Модели машинного обучения AmpliGraph генерируют графовые эмбеддинги, представления в векторном пространстве.
Далее эмбеддинги объединяются со специальными функциями для того, что прогнозировать новые и не замеченные ранее связи.
AmpliGraph изначально был разработан в
You must be registered for see links
, где он и используется в различных промышленных проектах.Automunge
Платформа подготовки табличных данных
Язык программирования: Python
Автор: Николас Тиг
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
You must be registered for see links
— библиотека Python, помогающая в подготовке табличных данных для использование в машинном обучении. Посредством инструментария пакета возможны простые преобразования для feature engeenering-a с целью нормализации, кодировки и заполнения пропусков. Преобразования применяются к тренировочной подвыборке, а затем аналогичным образом применяются к данным из тестовой подвыборки. Преобразования могут выполняться в автоматическом режиме, назначаться из внутренней библиотеки или гибко настраиваться пользователем. Варианты заполнения включают «заполнение на основе машинного обучения», в котором модели обучаются для каждого столбца данных прогнозировать недостающую информацию.Проще говоря:
automunge (.) подготавливаются табличные данные для использования в машинном обучении,
postmunge (.) последовательно и с высокой эффективностью обрабатываются дополнительные данные.
Automunge доступен для установки посредством pip:
После установки достаточно импортировать библиотеку в Jupyter Notebook для инициализации:
Для автоматической обработки данных из тренировочной выборки с параметрами по умолчанию достаточно использовать команду:
Далее для последующей обработки данных из тестовой подвыборки, достаточно запустить команду, использующую словарь postprocess_dict, полученный вызовом automunge (.) выше:
С помощью параметров assigncat и assigninfill в вызове automunge (.) могут быть определены детали преобразований и типы данных для заполнения пропусков. Например, для набора данных со столбцами 'column1' и 'column2' можно назначить масштабирование на основе минимальных и максимальных значений ('mnmx') с ML-заполнением пропусков для column1 и one-hot encoding ('text') с заполнением пропусков на основе наиболее часто встречающегося значения для column2. Не указанные в явном виде данные из других столбцов будут обрабатываться автоматически.
Ресурсы и ссылки
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
DynaML
Машинное обучение для Scala
Язык программирования: Scala
Автор: Мандар Чандоркар
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
DynaML — это набор инструментов для исследований и машинного обучения на основе Scala. Он направлен на предоставление пользователю сквозной среды, которая может помочь в:
- разработке / макетировании моделей,
- работе с громоздкими и сложными pipelines,
- визуализацией данных и результатов,
- повторном использовании кода в виде скриптов и Notebook-ов.
DynaML использует сильные стороны языка и экосистемы Scala для создания среды, обеспечивающей производительность и гибкость. Он основан на таких превосходных проектах, как
You must be registered for see links
scala,
You must be registered for see links
и библиотеке высокопроизводительных численных расчётов
You must be registered for see links
.Ключевым компонентом DynaML является REPL / оболочка, которая имеет подсветку синтаксиса и продвинутую систему автозаполнения.
Скопируйте и вставьте фрагменты кода в командную строку, чтобы запустить их.
Среда поставляется с поддержкой 2D и 3D-визуализации, результаты могут быть отображены непосредственно из командной оболочки.
3D-диаграммы отображаются с помощью Java API
You must be registered for see links
.Модуль
You must be registered for see links
позволяет легко создавать pipelines обработки данных в пригодном для компоновки модульном виде. Создавайте функции, оборачивайте их с помощью конструктора DataPipe и составляйте блоки функций с помощью оператора «>».
Обработка потоков данных выглядит интуитивно понятной, когда pipeline логически делится на этапы, а на каждом шаге выполняется одно единственное преобразование.
Также доступна экспериментальная функция интеграции c Jupyter notebook, каталог notebooks в репозитории содержит несколько примеров использования ядра DynaML-Scala Jupyter.
Notebook c
You must be registered for see links
ей (linear-regression notebook) демонстрирует использование низкоуровневого API Tensorflow для вычисления коэффициентов линейной регрессионной модели.
You must be registered for see links
содержит обширную справочную информацию и документацию для освоения и получения максимальной отдачи от среды DynaML.Ниже приводятся некоторые интересные приложения, которые подчеркивают сильные стороны DynaML:
- физика вдохновила нейронные сети на решение
You must be registered for see linksиYou must be registered for see links,
- тренировка Deep Learning,
- модели Гауссовских процессов для авторегрессионного прогнозирования временных рядов.
Ресурсы и ссылки
You must be registered for see links
|
You must be registered for see links
*****
Configuration and parameters manager
Язык программирования: Python
Автор: Омры Ядан
You must be registered for see links
|
You must be registered for see links
Разработанная в Facebook AI, ***** — платформа Python, которая упрощает разработку исследовательских приложений, предоставляя возможность создавать и переопределять конфигурации с помощью конфигурационных файлов и командной строки. Платформа также обеспечивает поддержку автоматической развертки параметров, удаленное и параллельное выполнение посредством плагинов, автоматическое управление рабочим каталогом и динамическое предложение вариантов дополнения с помощью нажатия клавиши TAB.
Использование ***** также делает ваш код более переносимым в различных средах машинного обучения. Позволяет вам переключаться между личными рабочими станциями, общедоступными и частными кластерами без изменения кода. Описанное выше достигается путем модульной архитектуры.
Основной пример
В приведенном примере используется конфигурация базы данных, но вы можете легко заменить ее моделями, датасетами или чем-либо еще по необходимости.
config.yaml:
my_app.py:
Вы можете переопределить что угодно в конфигурации из командной строки:
Пример композиции:
Возможно, вы захотите переключаться между двумя разными конфигурациями баз данных.
Создать эту структуру директорий:
config.yaml:
defaults — это специальная директива, указывающая ***** использовать db / mysql.yaml при составлении объекта конфигурации.
Теперь вы можете выбрать, какую использовать конфигурацию базы данных, а также переопределить значения параметров из командной строки:
Ознакомьтесь с
You must be registered for see links
, чтобы узнать больше.Кроме того, в ближайшее время появятся новые интересные функции:
- строго типизированные конфигурации (структурированные конфигурационные файлы),
- оптимизация гиперпараметров с помощью плагинов Ax и Nevergrad,
- запуск AWS с помощью плагина Ray launcher,
- локальный параллельный запуск посредством плагина joblib и многое другое.
Larq
Бинаризованные нейронные сети
Язык программирования: Python
Автор: Лукас Гайгер
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
Larq — это экосистема пакетов Python с открытым исходным кодом для построения, обучения и развертывания бинаризованных нейронных сетей (BNN). BNN — это модели глубокого обучения, в которых активации и веса кодируются не с использованием 32, 16 или 8 бит, а с использованием только 1 бита. Это может значительно ускорить время логического вывода и снизить энергопотребление, что делает BNN идеально подходящими для мобильных и периферийных устройств.
Экосистема Larq с открытым исходным кодом состоит из трех основных компонентов.
-
You must be registered for see links— это мощная, но простая в использовании библиотека для построения и обучения крайне квантованных нейронных сетей. Она предлагает единообразные и простые API, которые расширяемы и обладают совместимостью с более крупной экосистемой TensorFlow Keras. Это позволяет сделать постепенное внедрение в текущую кодовую базу и обеспечивает быструю итерацию при разработке моделей. Хотя библиотека Larq в основном ориентирована на BNNs, она также может быть использована для обучения сетей с произвольными функциями активации и весами произвольной точности.
-
You must be registered for see linksпредоставляет базовые реализации BNNs, доступные наряду с предобученными весами. Целью Larq Zoo является стимулирование воспроизводимых исследований, а исследователям предоставляется возможность использовать последние достижения из литературы по BNN без затрат времени на попытки воспроизвести существующие работы.
-
You must be registered for see links— это библиотека для логического вывода и развертывания BNNs. Она собрана поверх TensorFlow Lite и включает в себя конвертер на основе MLIR для преобразования моделей Larq в файлы FlatBuffer, совместимые с окружением TF Lite. В настоящее время он поддерживает мобильные платформы на базе ARM64, такие, как телефоны на Android и Raspberry Pi, и достигает самой высокой производительности в скорости логического вывода на устройствах с помощью ядер двоичной свертки, оптимизированных вручную, а также оптимизации на сетевом уровне для моделей BNN.
Авторы проекта постоянно создают более быстрые модели и расширяют экосистему Larq на новые аппаратные платформы и приложения для глубокого обучения. Например, в настоящее время идет работа над сквозной интеграцией восьмиразрядного квантования, чтобы была возможность обучать и развертывать комбинации двоичных и восьмиразрядных сетей, используя Larq.
Ресурсы и ссылки
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
McKernel
Ядерные методы в логарифмически линейное время
Язык программирования: C/C++
Автор: J. de Curtó i Díaz
You must be registered for see links
|
You must be registered for see links
Первая библиотека C++ с открытым исходным кодом, предоставляющая как аппроксимацию ядерных методов на основе случайных признаков, так и полноценный Deep Learning фреймворк.
McKernel предоставляет четыре различные возможности использования.
- Самодостаточный молниеносный код Адамара с открытым исходником. Для использования в таких областях, как компрессия, шифрование или квантовые вычисления.
- Чрезвычайно быстрые ядерные методы. Могут использоваться везде, где методы SVM (Метод Опорных Векторов:
You must be registered for see links) превосходят Deep Learning. Например, в некоторых приложениях робототехники и ряде случаев использования машинного обучения в здравоохранении, а также в других областях, включают Federated Learning и выбор канала коммуникации.
- Интеграция методов Deep Learning и ядерных методов, позволяет развивать Deep Learning архитектуры в априорно антропоморфном / математическом направлении.
- Исследовательский фреймворк Deep Learning для решения ряда открытых вопросов в машинном обучении.
Уравнение, описывающее все вычисления, выглядит следующим образом:
Здесь авторы в качестве первопроходцев применяют формализм для объяснения с помощью случайных признаков как
You must be registered for see links
Deep Learning
You must be registered for see links
. Теоретическая основа опирается на четырех гигантов: Гаусса, Винера, Фурье и Калмана. Фундамент для этого был заложен Рахими и Рехтом (NIPS 2007) и Le et al. (ICML 2013).С прицелом на типичного пользователя
Основной аудиторией McKernel являются исследователи и практические специалисты в области робототехники, машинного обучения для здравоохранения, обработки сигналов и коммуникаций, которые нуждаются в эффективной и быстрой реализации на C++. В описанном случае большинство библиотек Deep Learning не удовлетворяют заданным условиям, поскольку они по большей части основаны на высокоуровневых реализациях на Python. Кроме того, аудиторией могут быть представители более широкого сообщества машинного обучения и Deep Learning, которые пребывают в поиске улучшения архитектуры нейронных сетей, используя ядерные методы.
Сверхпростой наглядный пример для запуска библиотеки без затрат времени выглядит следующим образом:
Что дальше?
Сквозное обучение, self-supervised learning, meta-learning, интеграция с эволюционными стратегиями, существенное сокращение пространства поиска с помощью NAS ,…
Ресурсы и ссылки
You must be registered for see links
|
You must be registered for see links
SCCH Training Engine
Подпрограммы для автоматизации Deep Learning
Язык программирования: Python
Автор: Наталья Шепелева
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
Разработка типичного pipeline для Deep Learning довольно стандартна: предварительная обработка данных, проектирование/реализация задачи, обучение модели и оценка результата. Тем не менее, от проекта к проекту его использование требует участия инженера на каждом этапе разработки, что ведет к повторению одних и тех же действий, дублированию кода и в конце концов приводит к ошибкам.
Целью SCCH Training Engine является унификация и автоматизация процедуры Deep Learning разработки для двух самых популярных фреймворков PyTorch и TensorFlow. Архитектура с одним входом позволяет минимизировать время разработки и защищает от программных ошибок.
Для кого?
Гибкая архитектура SCCH Training Engine обладает двумя уровнями взаимодействия с пользователем.
Основной. На этом уровне пользователь должен предоставить данные для тренировки и прописать параметры тренировки модели в файле конфигурации. После этого все процессы, включая обработку данных, обучение модели и валидацию результатов будут выполнены в автоматическом режиме. В результате будет получена обученная модель в рамках одного из основных фреймворков.
Продвинутый. Благодаря модульной концепции компонент, пользователь может модифицировать модули в соответствии со своими потребностями, разворачивая свои собственные модели и используя различные функции потерь и метрики качества. Подобная модульная архитектура позволяет добавлять дополнительные признаки, не мешая работе основного pipeline-а.
Что он может делать?
Текущие возможности:
- работа с TensorFlow и PyTorch,
- стандартизированный pipeline парсинга данных из различных форматов,
- стандартизированный pipeline тренировки модели и валидации результатов,
- поддержка задач классификации, сегментации и детекции,
- поддержка кросс-валидации.
Возможности на стадии разработки:
- поиск оптимальных гиперпараметров модели,
- загрузка весов модели и тренировка от конкретной контрольной точки,
- поддержка архитектуры GAN.
Как это работает?
Чтобы увидеть SCCH Training Engine во все красе, вам нужно сделать два шага.
- Просто скопируйте репозиторий и установите требующиеся пакеты с помощью команды: pip install requirements.txt.
- Запустите python main.py, чтобы увидеть учебный пример MNIST с процессом обработки и обучения на модели LeNet-5.
Всю информацию о том, как создать файл конфигурации и как использовать продвинутые возможности, можно найти на странице
You must be registered for see links
.Стабильный релиз с основными функциями: был запланирован на конец мая 2020 г.
Ресурсы и ссылки
You must be registered for see links
|
You must be registered for see links
Tokenizers
Текстовые токенизаторы
Язык программирования: Rust с Python API
Автор: Энтони Муа
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
You must be registered for see links
обеспечивает доступ к самым современным токенизаторам, с акцентом на производительность и многоцелевое использование. Tokenizers позволяет обучать и использовать токенизаторы без усилий. Токенизаторы могут помочь вам независимо от того, являетесь ли вы ученым или практиков в области NLP.Ключевые особенности
- Чрезвычайная скорость: токенизация не должна быть узким местом в вашем pipeline, кроме того вам не нужно заниматься предварительной обработкой ваших данных. Благодаря нативной реализации на Rust, токенизация гигабайт текстов занимает всего несколько секунд.
- Смещения / выравнивание: обеспечивает контроль смещения даже при обработке текста со сложной процедурой нормализации. Это позволяет легко извлекать текст для таких задач, как NER или question answering.
- Предварительная обработка: заботится о любой предварительной обработке, необходимой перед подачей данных в вашу языковую модель (усечение, заполнение, добавление специальных токенов и т. д.).
- Простота в обучении: Тренируйте любой токенизатор на новом корпусе. Например, обучение токенизатора для BERT на новом языке никогда не было таким простым.
- Multi-languages: связка с несколькими языками. Прямо сейчас вы можете начать использовать его с Python, Node.js, или Rust. Работа в этом направлении продолжается!
Пример:
И скоро:
- сериализация в единый файл и загрузка в одну строчку для любого токенизатора,
- поддержка Unigram.
You must be registered for see links
видят свою миссию в том, чтобы помогать в продвижении и демократизации NLP.Ресурсы и ссылки
You must be registered for see links
|
You must be registered for see links
|
You must be registered for see links
Заключение
В заключении необходимо отметить, что есть большое количество библиотек, полезных для Deep Learning и машинного обучения в целом, и нет возможности описать в одной статье все их множество. Некоторые из описанных выше проектов будут полезны в специфических случаях, некоторые являются и так достаточно известными, а некоторые замечательные проекты, к сожалению не попали в статью.
Мы в компании
You must be registered for see links
стараемся следить за появлением новых инструментов и полезных библиотек, а также активно применяем свежие подходы в нашей работе, связанной с использованием Deep Learning и Машинного Обучения. Со своей стороны я хотел бы обратить внимание читателей на эти две библиотеки, не вошедшие в основную статью, но существенно помогающие в работе с нейронными сетями: Catalyst (
You must be registered for see links
) и Albumentation (
You must be registered for see links
). Уверен, что у каждого практикующего специалиста есть свои излюбленные инструменты и библиотеки, в том числе и малоизвестные широкой аудитории. Если вам кажется, что какие-либо полезные в работе инструменты были напрасно обойдены вниманием, то напишите их, пожалуйста, в комментариях: даже упоминание в обсуждении поможет перспективным проектам привлечь новых последователей, а прирост популярности в свою очередь приводит к улучшению функционала и развитию самих библиотек.
Благодарю за внимание и надеюсь, что представленный набор библиотек окажется полезным в вашей работе!