


Оффлайн
- Регистрация
- 12.04.17
- Сообщения
- 19.095
- Реакции
- 107
- Репутация
- 0
Привет, дорогие подписчики! Наверное вы уже знаете о том, что мы запустили новый курс
Мое хобби – играть в настольные игры, и поскольку я немного знакома со сверточными нейронными сетями, я решила создать приложение, которое может выиграть у человека в карточной игре. Я хотела с нуля построить модель с помощью своего собственного датасета и посмотреть, насколько хорошо она будет работать с небольшим датасетом. Начать я решила с несложной игры Доббль (также известной как Spot it!).
Если вы не знаете, что такое Доббль, я напомню вкратце правила игры: Доббль — это простая игра на распознавание образов, в которой игроки пытаются найти картинку, изображенную одновременно на двух карточках. Каждая карточка в оригинальной игре Доббль содержит восемь различных символов, при этом на разных карточках они разного размера. У любых двух карточек всего один общий символ. Если вы найдете символ первым, то заберете себе карточку. Когда колода из 55 карточек закончится, выиграет тот, у кого больше всех карточек.

Попробуйте сами: Какой символ общий для этих двух карточек?
С чего начать?
Первый шаг в решении любой задачи анализа данных заключается в сборе данных. Я сделала по шесть фотографий каждой карточки на телефон. Всего получилось 330 фотографий. Четыре из них вы видите ниже. У вас может возникнуть вопрос, достаточно ли этого, чтобы создать хорошую сверточную нейронную сеть? Мы к этому еще вернемся!

Обработка изображений
Хорошо, данные у нас есть, что дальше? Вероятно, самая важная часть на пути к успеху: обработка изображений. Нам нужно получить символы с каждого изображения. Здесь нас подстерегают некоторые трудности. На фотографиях выше заметно, что некоторые символы различить сложнее, чем другие: снеговик и приведение (на третьей фотографии) и иглу (на четвертой) светлых цветов, а кляксы ( на второй фотографии) и восклицательный знак (на четвертой фотографии) состоят из нескольких частей. Чтобы обработать светлые символы мы добавим контраста. После этого мы изменим размер и сохраним изображение.
Добавляем контрастности
Чтобы добавить контраста мы воспользуемся цветовым пространством Lab. L – это lightness (светлота), a – хроматическая составляющая в диапазоне от зеленого до пурпурного, а b – хроматическая составляющая в диапазоне от синего до желтого. Мы можем с легкостью извлечь эти компоненты с помощью
import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)

Слева направо: оригинал изображения, компонент светлоты, компонент a и компонент b
Теперь добавим контраста к компоненту светлоты, снова объединим все компоненты вместе и преобразуем в нормальное изображение:
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)

Слева направо: оригинал изображения, компонент светлоты, изображение с повышенной контрастностью и изображение, конвертированное обратно в RGB
Изменение размера
Теперь поменяем размер и сохраним изображение:
resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
Готово!
Распознавание карточки и символов
Теперь, когда изображение обработано, мы можем обнаружить карточку на изображении. С помощью OpenCV ищем внешние контуры. Затем преобразовываем изображение в полутона, выбираем значение threshold (в нашем случае 190) для создания черно-белого изображения и поиска контура. Код:
image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)

Обработанная картинка, преобразованная в полутона, с применением threshold и выделение внешних контуров
Если мы отсортируем внешние контуры по площади, то найдем контур с самой большой площадью – это и будет наша карточка. Для извлечения символов мы можем создать белый фон.
# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)

Маска, фон, изображение на переднем плане, итоговое изображение
Теперь пришло время распознавания символов! Полученное изображение мы можем использовать, чтобы на нем снова обнаружить внешние контуры, эти контуры и будут являться символами. Если вокруг каждого символа мы создадим квадрат, то сможем извлечь эту область. Тут код немного длиннее:
# just like before (with detecting the card)
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
# handle each contour
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
# draw mask, keep contour
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
# white background
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
# bounding rectangle around contour
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
# squares io rectangles
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
# take out the square with the symbol
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
# save the symbol
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1

Черно-белое изображение (thresholded), обнаруженные контуры, символ приведения и символ сердца (символы, извлеченные с помощью масок)
Посимвольная сортировка
А теперь самое скучное! Нужно отсортировать символы. Понадобятся каталоги train, test и validation, по 57 каталогов в каждом (всего у нас есть 57 различных символов). Структура папок выглядит следующим образом:
symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
Потребуется некоторое время, чтобы поместить извлеченные символы (более 2500 штук) в нужные каталоги! У меня есть код для создания вложенных папок, тестовый набор и набор валидации на
Обучение сверточной нейронной сети
После скучной части снова идет веселая! Пора создать и обучить сверточную нейронную сеть. Информацию про сверточные нейронные сети вы можете
Архитектура модели
У нас стоит задача многоклассовой классификации с одной меткой. Для каждого символа нам понадобится одна метка. Именно поэтому нам понадобится функция активации выходного слоя softmax с 57 узлами и категориальная перекрестная энтропия в качестве функции потерь.
Архитектура итоговой модели выглядит следующим образом:
# imports
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# layers, activation layer with 57 nodes (one for every symbol)
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
Аугментация данных
Для повышения производительности я использовала аугментацию данных. Аугментация данных – это процесс увеличения объема и разнообразия входных данных. Это можно сделать вращая, сдвигая, масштабируя, обрезая и переворачивая имеющиеся изображения. С помощью Keras легко выполнить аугментацию данных:
# specify the directories
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
# data augmentation with ImageDataGenerator from Keras (only train)
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
Если вам было интересно, аугментированное приведение выглядит так:

Оригинальное изображение приведения слева, аугментированные приведения на всех остальных картинках
Обучение модели
Давайте обучим модель, сохраним ее, чтобы использовать для предсказаний, и проверим полученные результаты.
history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
# don't forget to save your model!
model.save('models/model.h5')

Идеальные предсказания!
Результаты
Базовая модель, которую я обучала без аугментации данных, отсева и с меньшим количеством слоев. Эта модель дала следующие результаты:
Результаты базовой модели
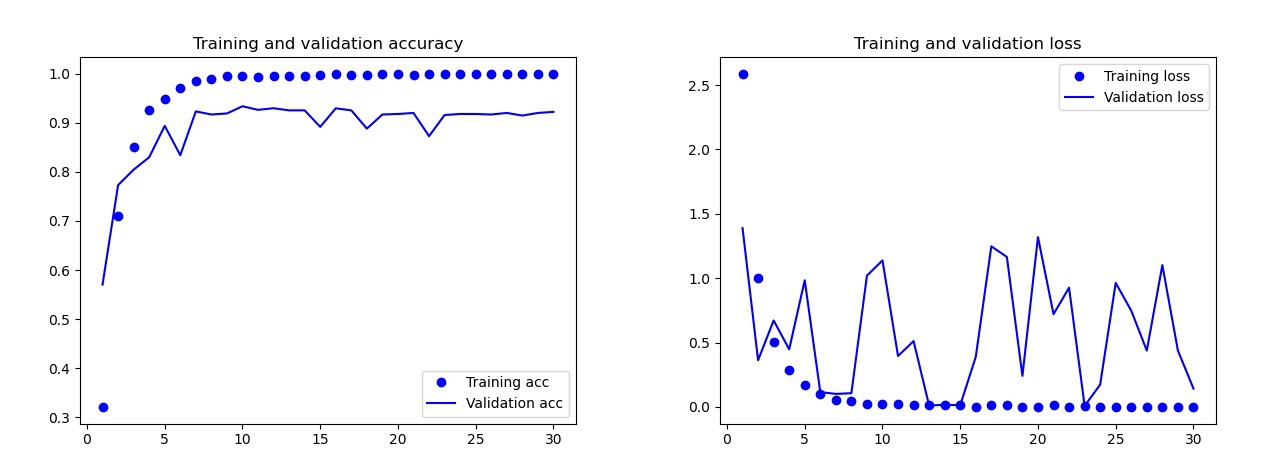
Невооруженным взглядом видно, что эта модель переобучена. Результаты итогового варианта модели (ее код представлен в предыдущих разделах) намного лучше. На графике снизу вы можете увидеть точность и потери при обучении и на наборе валидации.

Результаты итоговой модели
На тестовом наборе эта модель допустила всего одну ошибку, она распознала бомбу как каплю. Я решила остановиться на этой модели, точность на тестовом наборе получилась 0.995.
Распознавание общего символа на двух карточках
Теперь можно начать искать общие символы на двух карточках. Мы используем две фотографии, будем делать предсказания для каждого изображения по отдельности и использовать пересечение множеств, чтобы узнать какой символ есть на обеих карточках. У нас есть 3 варианта работы:
Код для предсказания всех комбинация на двух изображениях в каталоге лежит на
А вот и результаты:

Заключение
Разве это не идеальная модель? К сожалению, нет. Когда я сделала новые фотографии карточек и отдала их модели для предсказания, со снеговиком возникли некоторые проблемы. Иногда он распознавал глаз или зебру как снеговика! В итоге порой результаты были странными:

Ну и где здесь снеговик?
Лучше ли эта модель, чем человек? В зависимости что нам нужно: люди распознают идеально, но модель делает это быстрее! Я засекла время, за которое справляется компьютер: дала колоду из 55 карточек и на выход должна была получить общий символ для каждой комбинации из двух карточек. В общей сложности это 1485 комбинаций. Компьютер справился менее, чем за 140 секунд. Он допустил несколько ошибок, но он определенно выиграет у любого человека, когда речь пойдет о скорости!

Не думаю, что создать рабочую на 100% модель сложно. Добиться этого можно с помощью трансферного обучения. Чтобы понять, что делает модель, мы могли бы визуализировать слои для тестового изображения. Можно заняться этим в следующий раз!
You must be registered for see links
, занятия по которому стартуют уже в ближайшие дни. В преддверии старта занятий подготовили еще один интересный перевод для погружения в мир CV.Мое хобби – играть в настольные игры, и поскольку я немного знакома со сверточными нейронными сетями, я решила создать приложение, которое может выиграть у человека в карточной игре. Я хотела с нуля построить модель с помощью своего собственного датасета и посмотреть, насколько хорошо она будет работать с небольшим датасетом. Начать я решила с несложной игры Доббль (также известной как Spot it!).
Если вы не знаете, что такое Доббль, я напомню вкратце правила игры: Доббль — это простая игра на распознавание образов, в которой игроки пытаются найти картинку, изображенную одновременно на двух карточках. Каждая карточка в оригинальной игре Доббль содержит восемь различных символов, при этом на разных карточках они разного размера. У любых двух карточек всего один общий символ. Если вы найдете символ первым, то заберете себе карточку. Когда колода из 55 карточек закончится, выиграет тот, у кого больше всех карточек.
Попробуйте сами: Какой символ общий для этих двух карточек?
С чего начать?
Первый шаг в решении любой задачи анализа данных заключается в сборе данных. Я сделала по шесть фотографий каждой карточки на телефон. Всего получилось 330 фотографий. Четыре из них вы видите ниже. У вас может возникнуть вопрос, достаточно ли этого, чтобы создать хорошую сверточную нейронную сеть? Мы к этому еще вернемся!
Обработка изображений
Хорошо, данные у нас есть, что дальше? Вероятно, самая важная часть на пути к успеху: обработка изображений. Нам нужно получить символы с каждого изображения. Здесь нас подстерегают некоторые трудности. На фотографиях выше заметно, что некоторые символы различить сложнее, чем другие: снеговик и приведение (на третьей фотографии) и иглу (на четвертой) светлых цветов, а кляксы ( на второй фотографии) и восклицательный знак (на четвертой фотографии) состоят из нескольких частей. Чтобы обработать светлые символы мы добавим контраста. После этого мы изменим размер и сохраним изображение.
Добавляем контрастности
Чтобы добавить контраста мы воспользуемся цветовым пространством Lab. L – это lightness (светлота), a – хроматическая составляющая в диапазоне от зеленого до пурпурного, а b – хроматическая составляющая в диапазоне от синего до желтого. Мы можем с легкостью извлечь эти компоненты с помощью
You must be registered for see links
:import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
Слева направо: оригинал изображения, компонент светлоты, компонент a и компонент b
Теперь добавим контраста к компоненту светлоты, снова объединим все компоненты вместе и преобразуем в нормальное изображение:
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
Слева направо: оригинал изображения, компонент светлоты, изображение с повышенной контрастностью и изображение, конвертированное обратно в RGB
Изменение размера
Теперь поменяем размер и сохраним изображение:
resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
Готово!
Распознавание карточки и символов
Теперь, когда изображение обработано, мы можем обнаружить карточку на изображении. С помощью OpenCV ищем внешние контуры. Затем преобразовываем изображение в полутона, выбираем значение threshold (в нашем случае 190) для создания черно-белого изображения и поиска контура. Код:
image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)
Обработанная картинка, преобразованная в полутона, с применением threshold и выделение внешних контуров
Если мы отсортируем внешние контуры по площади, то найдем контур с самой большой площадью – это и будет наша карточка. Для извлечения символов мы можем создать белый фон.
# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)
Маска, фон, изображение на переднем плане, итоговое изображение
Теперь пришло время распознавания символов! Полученное изображение мы можем использовать, чтобы на нем снова обнаружить внешние контуры, эти контуры и будут являться символами. Если вокруг каждого символа мы создадим квадрат, то сможем извлечь эту область. Тут код немного длиннее:
# just like before (with detecting the card)
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
# handle each contour
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
# draw mask, keep contour
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
# white background
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
# bounding rectangle around contour
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
# squares io rectangles
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
# take out the square with the symbol
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
# save the symbol
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1
Черно-белое изображение (thresholded), обнаруженные контуры, символ приведения и символ сердца (символы, извлеченные с помощью масок)
Посимвольная сортировка
А теперь самое скучное! Нужно отсортировать символы. Понадобятся каталоги train, test и validation, по 57 каталогов в каждом (всего у нас есть 57 различных символов). Структура папок выглядит следующим образом:
symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
Потребуется некоторое время, чтобы поместить извлеченные символы (более 2500 штук) в нужные каталоги! У меня есть код для создания вложенных папок, тестовый набор и набор валидации на
You must be registered for see links
. Возможно, в следующий раз лучше сделать сортировку на основе алгоритма кластеризации…Обучение сверточной нейронной сети
После скучной части снова идет веселая! Пора создать и обучить сверточную нейронную сеть. Информацию про сверточные нейронные сети вы можете
You must be registered for see links
. Архитектура модели
У нас стоит задача многоклассовой классификации с одной меткой. Для каждого символа нам понадобится одна метка. Именно поэтому нам понадобится функция активации выходного слоя softmax с 57 узлами и категориальная перекрестная энтропия в качестве функции потерь.
Архитектура итоговой модели выглядит следующим образом:
# imports
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# layers, activation layer with 57 nodes (one for every symbol)
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
Аугментация данных
Для повышения производительности я использовала аугментацию данных. Аугментация данных – это процесс увеличения объема и разнообразия входных данных. Это можно сделать вращая, сдвигая, масштабируя, обрезая и переворачивая имеющиеся изображения. С помощью Keras легко выполнить аугментацию данных:
# specify the directories
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
# data augmentation with ImageDataGenerator from Keras (only train)
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
Если вам было интересно, аугментированное приведение выглядит так:
Оригинальное изображение приведения слева, аугментированные приведения на всех остальных картинках
Обучение модели
Давайте обучим модель, сохраним ее, чтобы использовать для предсказаний, и проверим полученные результаты.
history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
# don't forget to save your model!
model.save('models/model.h5')
Идеальные предсказания!
Результаты
Базовая модель, которую я обучала без аугментации данных, отсева и с меньшим количеством слоев. Эта модель дала следующие результаты:
Результаты базовой модели
Невооруженным взглядом видно, что эта модель переобучена. Результаты итогового варианта модели (ее код представлен в предыдущих разделах) намного лучше. На графике снизу вы можете увидеть точность и потери при обучении и на наборе валидации.
Результаты итоговой модели
На тестовом наборе эта модель допустила всего одну ошибку, она распознала бомбу как каплю. Я решила остановиться на этой модели, точность на тестовом наборе получилась 0.995.
Распознавание общего символа на двух карточках
Теперь можно начать искать общие символы на двух карточках. Мы используем две фотографии, будем делать предсказания для каждого изображения по отдельности и использовать пересечение множеств, чтобы узнать какой символ есть на обеих карточках. У нас есть 3 варианта работы:
- Что-то пошло не так во время предсказания: общих символов не найдено.
- В пересечении один символ (предсказание может быть истинным или ложным).
- В пересечении больше одного символа. В этом случае я выбираю символ с наибольшей вероятностью (среднее значение обоих предсказаний).
Код для предсказания всех комбинация на двух изображениях в каталоге лежит на
You must be registered for see links
в main.py.А вот и результаты:
Заключение
Разве это не идеальная модель? К сожалению, нет. Когда я сделала новые фотографии карточек и отдала их модели для предсказания, со снеговиком возникли некоторые проблемы. Иногда он распознавал глаз или зебру как снеговика! В итоге порой результаты были странными:
Ну и где здесь снеговик?
Лучше ли эта модель, чем человек? В зависимости что нам нужно: люди распознают идеально, но модель делает это быстрее! Я засекла время, за которое справляется компьютер: дала колоду из 55 карточек и на выход должна была получить общий символ для каждой комбинации из двух карточек. В общей сложности это 1485 комбинаций. Компьютер справился менее, чем за 140 секунд. Он допустил несколько ошибок, но он определенно выиграет у любого человека, когда речь пойдет о скорости!
Не думаю, что создать рабочую на 100% модель сложно. Добиться этого можно с помощью трансферного обучения. Чтобы понять, что делает модель, мы могли бы визуализировать слои для тестового изображения. Можно заняться этим в следующий раз!
You must be registered for see links