


Оффлайн
- Регистрация
- 21.07.20
- Сообщения
- 40.408
- Реакции
- 1
- Репутация
- 0
Здравствуй, Хабр!
Цель этой статьи — рассказать о линейной регрессии, а именно собрать и показать формулировки и интерпретации задачи регрессии с точки зрения математического анализа, статистики, линейной алгебры и теории вероятностей. Хотя в учебниках эта тема изложена строго и исчерпывающе, ещё одна научно-популярная статья не помешает.
! Осторожно, трафик! В статье присутствует заметное число изображений для иллюстраций, часть в формате gif.
Содержание
Введение
Есть три сходных между собой понятия, три сестры: интерполяция, аппроксимация и регрессия.
У них общая цель: из семейства функций выбрать ту, которая обладает определенным свойством.
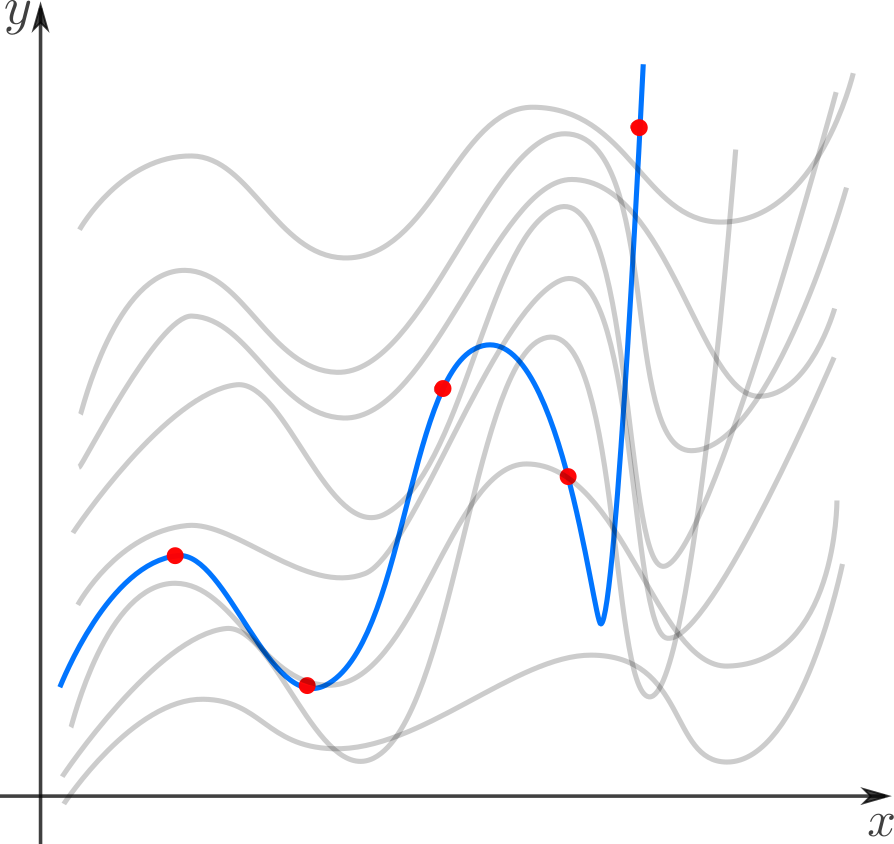 Интерполяция — способ, как из семейства функций выбрать ту, которая проходит через заданные точки. Затем ее обычно используют для вычисления в точках, отличных от заданных. Например, мы вручную задаем цвет нескольким точкам и хотим чтобы цвета остальных точек образовали плавные переходы между заданными. Или задаем ключевые кадры анимации и хотим плавные переходы между ними. Классические примеры: интерполяция полиномами Лагранжа, сплайн-интерполяция.
Интерполяция — способ, как из семейства функций выбрать ту, которая проходит через заданные точки. Затем ее обычно используют для вычисления в точках, отличных от заданных. Например, мы вручную задаем цвет нескольким точкам и хотим чтобы цвета остальных точек образовали плавные переходы между заданными. Или задаем ключевые кадры анимации и хотим плавные переходы между ними. Классические примеры: интерполяция полиномами Лагранжа, сплайн-интерполяция.

 Аппроксимация — способ, как из семейства «простых» функций выбрать приближение для «сложной» функции на отрезке, при этом ошибка не должна превышать определенного предела. Аппроксимацию используют, когда нужно получить функцию, похожую на данную, но более удобную для вычислений и манипуляций (дифференцирования, интегрирования и т.п). При оптимизации критических участков кода часто используют аппроксимацию: если значение функции вычисляется много раз в секунду и не нужна абсолютная точность, то можно обойтись более простым аппроксимантом с меньшей «ценой» вычисления. Классические примеры включают ряд Тейлора на отрезке, аппроксимацию функции ортогональными многочленами, аппроксимацию Паде, аппроксимацию синуса Бхаскара и т.п.
Аппроксимация — способ, как из семейства «простых» функций выбрать приближение для «сложной» функции на отрезке, при этом ошибка не должна превышать определенного предела. Аппроксимацию используют, когда нужно получить функцию, похожую на данную, но более удобную для вычислений и манипуляций (дифференцирования, интегрирования и т.п). При оптимизации критических участков кода часто используют аппроксимацию: если значение функции вычисляется много раз в секунду и не нужна абсолютная точность, то можно обойтись более простым аппроксимантом с меньшей «ценой» вычисления. Классические примеры включают ряд Тейлора на отрезке, аппроксимацию функции ортогональными многочленами, аппроксимацию Паде, аппроксимацию синуса Бхаскара и т.п.
 Регрессия — способ, как из семейства функций выбрать ту, которая минимизирует функцию потерь. Последняя характеризует насколько сильно пробная функция отклоняется от значений в заданных точках. Если точки получены в эксперименте, они неизбежно содержат ошибку измерений, шум, поэтому разумнее требовать, чтобы функция передавала общую тенденцию, а не точно проходила через все точки. В каком-то смысле регрессия — это «интерполирующая аппроксимация»: мы хотим провести кривую как можно ближе к точкам и при этом сохранить ее максимально простой чтобы уловить общую тенденцию. За баланс между этими противоречивыми желаниями как-раз отвечает функция потерь (в английской литературе «loss function» или «cost function»).
Регрессия — способ, как из семейства функций выбрать ту, которая минимизирует функцию потерь. Последняя характеризует насколько сильно пробная функция отклоняется от значений в заданных точках. Если точки получены в эксперименте, они неизбежно содержат ошибку измерений, шум, поэтому разумнее требовать, чтобы функция передавала общую тенденцию, а не точно проходила через все точки. В каком-то смысле регрессия — это «интерполирующая аппроксимация»: мы хотим провести кривую как можно ближе к точкам и при этом сохранить ее максимально простой чтобы уловить общую тенденцию. За баланс между этими противоречивыми желаниями как-раз отвечает функция потерь (в английской литературе «loss function» или «cost function»).
В этой статье мы рассмотрим линейную регрессию. Это означает, что семейство функций, из которых мы выбираем, представляет собой линейную комбинацию наперед заданных базисных функций


Цель регрессии — найти коэффициенты этой линейной комбинации, и тем самым определить регрессионную функцию
 (которую также называют моделью). Отмечу, что линейную регрессию называют линейной именно из-за линейной комбинации базисных функций — это не связано с самыми базисными функциями (они могут быть линейными или нет).
(которую также называют моделью). Отмечу, что линейную регрессию называют линейной именно из-за линейной комбинации базисных функций — это не связано с самыми базисными функциями (они могут быть линейными или нет).
Регрессия с нами уже давно: впервые метод опубликовал Лежандр в 1805 году, хотя Гаусс пришел к нему раньше и успешно использовал для предсказания орбиты «кометы» (на самом деле карликовой планеты) Цереры. Существует множество вариантов и обобщений линейной регрессии: LAD, метод наименьших квадратов, Ridge регрессия, Lasso регрессия, ElasticNet и многие другие.
гифка
Точки генерируются случайно по распределению Гаусса с заданным средним и вариациями. Синяя линия — регрессионная прямая.

Можно
Много других материалов по классическому машинному обучению
Метод наименьших квадратов
Начнём с простейшего двумерного случая. Пусть нам даны точки на плоскости
 и мы ищем такую аффинную функцию
и мы ищем такую аффинную функцию

 чтобы ее график ближе всего находился к точкам. Таким образом, наш базис состоит из константной функции и линейной
чтобы ее график ближе всего находился к точкам. Таким образом, наш базис состоит из константной функции и линейной
 .
.
Как видно из иллюстрации, расстояние от точки до прямой можно понимать по-разному, например геометрически — это длина перпендикуляра. Однако в контексте нашей задачи нам нужно функциональное расстояние, а не геометрическое. Нас интересует разница между экспериментальным значением и предсказанием модели для каждого
 поэтому измерять нужно вдоль оси
поэтому измерять нужно вдоль оси
 .
.
Первое, что приходит в голову, в качестве функции потерь попробовать выражение, зависящее от абсолютных значений разниц
 . Простейший вариант — сумма модулей отклонений
. Простейший вариант — сумма модулей отклонений
 приводит к Least Absolute Distance (LAD) регрессии.
приводит к Least Absolute Distance (LAD) регрессии.
Впрочем, более популярная функция потерь — сумма квадратов отклонений регрессанта от модели. В англоязычной литературе она носит название Sum of Squared Errors (SSE)

Метод наименьших квадратов (по англ. OLS) — линейная регрессия c
 в качестве функции потерь.
в качестве функции потерь.

Такой выбор прежде всего удобен: производная квадратичной функции — линейная функция, а линейные уравнения легко решаются. Впрочем, далее я укажу и другие соображения в пользу
.
гифка
Регрессионная прямая (синяя) и пробная прямая (зеленая). Справа показана функция потерь и точки соответствующие параметра пробной и регрессионной прямых.

Можно
Много других материалов по классическому машинному обучению
Математический анализ
Простейший способ найти
 — вычислить частные производные по
— вычислить частные производные по
 и
и
 , приравнять их нулю и решить систему линейных уравнений
, приравнять их нулю и решить систему линейных уравнений

Значения параметров, минимизирующие функцию потерь, удовлетворяют уравнениям

которые легко решить

Мы получили громоздкие и неструктурированные выражения. Сейчас мы их облагородим и вдохнем в них смысл.
Статистика
Полученные формулы можно компактно записать с помощью статистических эстиматоров: среднего
 , вариации
, вариации
 (стандартного отклонения), ковариации
(стандартного отклонения), ковариации
 и корреляции
и корреляции


Перепишем
 как
как

где
 это нескорректированное (смещенное) стандартное выборочное отклонение, а
это нескорректированное (смещенное) стандартное выборочное отклонение, а
 — ковариация. Теперь вспомним, что коэффициент корреляции (коэффициент корреляции Пирсона)
— ковариация. Теперь вспомним, что коэффициент корреляции (коэффициент корреляции Пирсона)

и запишем

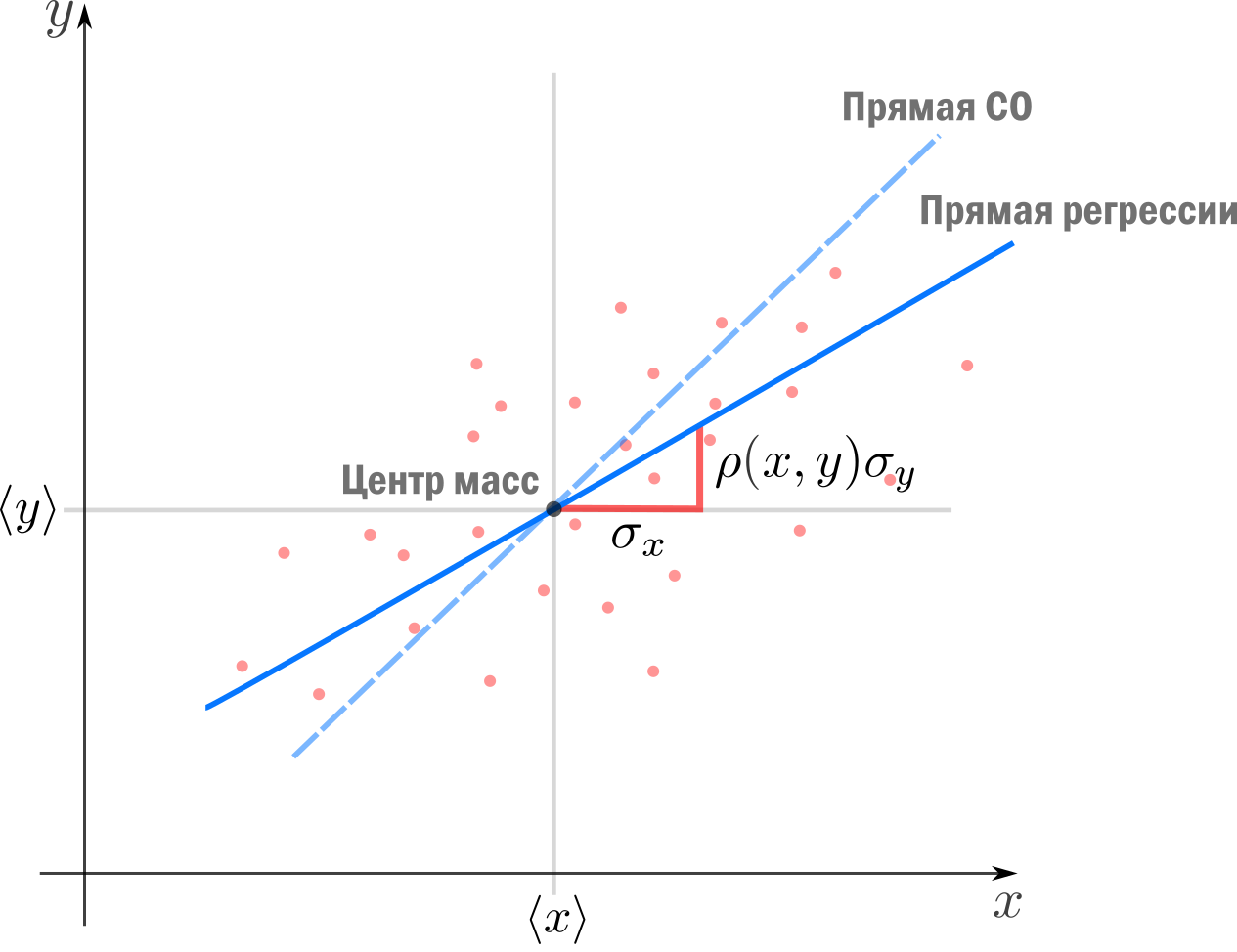
Теперь мы можем оценить все изящество дескриптивной статистики и записать уравнение регрессионной прямой так

Во-первых, это уравнение сразу указывает на два свойства регрессионной прямой:
Во-вторых, теперь становится понятно, почему метод регрессии называется именно так. В единицах стандартного отклонения
отклоняется от своего среднего значения меньше чем
 , потому что
, потому что
 . Это называется регрессией(от лат. regressus — «возвращение») по отношению к среднему. Это явление было описано сэром Фрэнсисом Гальтоном в конце XIX века в его статье «Регрессия к посредственности при наследовании роста». В статье показано, что черты (такие как рост), сильно отклоняющиеся от средних, редко передаются по наследству. Характеристики потомства как-бы стремятся к среднему — на детях гениев природа отдыхает.
. Это называется регрессией(от лат. regressus — «возвращение») по отношению к среднему. Это явление было описано сэром Фрэнсисом Гальтоном в конце XIX века в его статье «Регрессия к посредственности при наследовании роста». В статье показано, что черты (такие как рост), сильно отклоняющиеся от средних, редко передаются по наследству. Характеристики потомства как-бы стремятся к среднему — на детях гениев природа отдыхает.
Возведя коэффициент корреляции в квадрат, получим коэффициент детерминации
 . Квадрат этой статистической меры показывает насколько хорошо регрессионная модель описывает данные.
. Квадрат этой статистической меры показывает насколько хорошо регрессионная модель описывает данные.
 , равный
, равный
 , означает что функция идеально ложится на все точки — данные идеально скоррелированны. Можно доказать, что
показывает какая доля вариативности в данных объясняется лучшей из линейных моделей. Чтобы понять, что это значит, введем определения
, означает что функция идеально ложится на все точки — данные идеально скоррелированны. Можно доказать, что
показывает какая доля вариативности в данных объясняется лучшей из линейных моделей. Чтобы понять, что это значит, введем определения

 — вариация исходных данных (вариация точек
— вариация исходных данных (вариация точек
 ).
).
 — вариация остатков, то есть вариация отклонений от регрессионной модели — от
нужно отнять предсказание модели и найти вариацию.
— вариация остатков, то есть вариация отклонений от регрессионной модели — от
нужно отнять предсказание модели и найти вариацию.
 — вариация регрессии, то есть вариация предсказаний регрессионной модели в точках
— вариация регрессии, то есть вариация предсказаний регрессионной модели в точках
 (обратите внимание, что среднее предсказаний модели совпадает с
(обратите внимание, что среднее предсказаний модели совпадает с
 ).
).

Дело в том, что вариация исходных данных разлагается в сумму двух других вариаций: вариации, которая объясняется моделью, и вариации случайного шума (остатков)

или

Как видим, стандартные отклонения образуют прямоугольный треугольник.

Мы стремимся избавиться от вариативности связанной с шумом и оставить лишь вариативность, которая объясняется моделью, — хотим отделить зерна от плевел. О том, насколько это удалось лучшей из линейных моделей, свидетельствует
, равный единице минус доля вариации ошибок в суммарной вариации

или доле объясненной вариации (доля вариации регрессии в полной вариации)

 равен косинусу угла в прямоугольном треугольнике
равен косинусу угла в прямоугольном треугольнике
 . Кстати, иногда вводят долю необъясненной вариации
. Кстати, иногда вводят долю необъясненной вариации
 и она равна квадрату синуса в этом треугольнике. Если коэффициент детерминации мал, возможно мы выбрали неудачные базисные функции, линейная регрессия неприменима вовсе и т.п.
и она равна квадрату синуса в этом треугольнике. Если коэффициент детерминации мал, возможно мы выбрали неудачные базисные функции, линейная регрессия неприменима вовсе и т.п.
Теория вероятностей
Ранее мы пришли к функции потерь
из соображений удобства, но к ней же можно прийти с помощью теории вероятностей и метода максимального правдоподобия (ММП). Напомню вкратце его суть. Предположим, у нас есть
 независимых одинаково распределенных случайных величин (в нашем случае — результатов измерений). Мы знаем вид функции распределения (напр. нормальное распределение), но хотим определить параметры, которые в нее входят (например
независимых одинаково распределенных случайных величин (в нашем случае — результатов измерений). Мы знаем вид функции распределения (напр. нормальное распределение), но хотим определить параметры, которые в нее входят (например
 и
и
 ). Для этого нужно вычислить вероятность получить
датапоинтов в предположении постоянных, но пока неизвестных параметров. Благодаря независимости измерений, мы получим произведение вероятностей реализации каждого измерения. Если мыслить полученную величину как функцию параметров (функция правдоподобия) и найти её максимум, мы получим оценку параметров. Зачастую вместо функции правдоподобия используют ее логарифм — дифференцировать его проще, а результат — тот же.
). Для этого нужно вычислить вероятность получить
датапоинтов в предположении постоянных, но пока неизвестных параметров. Благодаря независимости измерений, мы получим произведение вероятностей реализации каждого измерения. Если мыслить полученную величину как функцию параметров (функция правдоподобия) и найти её максимум, мы получим оценку параметров. Зачастую вместо функции правдоподобия используют ее логарифм — дифференцировать его проще, а результат — тот же.
Вернемся к задаче простой регрессии. Допустим, что значения
нам известны точно, а в измерении
присутствует случайный шум (свойство слабой экзогенности). Более того, положим, что все отклонения от прямой (свойство линейности) вызваны шумом с постоянным распределением (постоянство распределения). Тогда

где
 — нормально распределенная случайная величина
— нормально распределенная случайная величина


Исходя из предположений выше, запишем функцию правдоподобия

и ее логарифм

Таким образом, максимум правдоподобия достигается при минимуме


что дает основание принять ее в качестве функции потерь. Кстати, если

мы получим функцию потерь LAD регрессии

которую мы упоминали ранее.
Подход, который мы использовали в этом разделе — один из возможных. Можно прийти к такому же результату, используя более общие свойства. В частности, свойство постоянства распределения можно ослабить, заменив на свойства независимости, постоянства вариации (гомоскедастичность) и отсутствия мультиколлинеарности. Также вместо ММП эстимации можно воспользоваться другими методами, например линейной MMSE эстимацией.
Мультилинейная регрессия
До сих пор мы рассматривали задачу регрессии для одного скалярного признака
, однако обычно регрессор — это
 -мерный вектор
-мерный вектор
 . Другими словами, для каждого измерения мы регистрируем
фич, объединяя их в вектор. В этом случае логично принять модель с
. Другими словами, для каждого измерения мы регистрируем
фич, объединяя их в вектор. В этом случае логично принять модель с
 независимыми базисными функциями векторного аргумента —
степеней свободы соответствуют
фичам и еще одна — регрессанту
. Простейший выбор — линейные базисные функции
независимыми базисными функциями векторного аргумента —
степеней свободы соответствуют
фичам и еще одна — регрессанту
. Простейший выбор — линейные базисные функции
 . При
. При
 получим уже знакомый нам базис
.
получим уже знакомый нам базис
.
Итак, мы хотим найти такой вектор (набор коэффициентов)
 , что
, что

Знак "
 " означает, что мы ищем решение, которое минимизирует сумму квадратов ошибок
" означает, что мы ищем решение, которое минимизирует сумму квадратов ошибок

Последнее уравнение можно переписать более удобным образом. Для этого расположим
 в строках матрицы (матрицы информации)
в строках матрицы (матрицы информации)

Тогда столбцы матрицы
 отвечают измерениям
отвечают измерениям
 -ой фичи. Здесь важно не запутаться:
— количество измерений,
— количество признаков (фич), которые мы регистрируем. Систему можно записать как
-ой фичи. Здесь важно не запутаться:
— количество измерений,
— количество признаков (фич), которые мы регистрируем. Систему можно записать как

Квадрат нормы разности векторов в правой и левой частях уравнения образует функцию потерь

которую мы намерены минимизировать

Продифференцируем финальное выражение по
(если забыли как это делается — загляните в

приравняем производную к
 и получим т.н. нормальные уравнения
и получим т.н. нормальные уравнения

Если столбцы матрицы информации
 линейно независимы (нет идеально скоррелированных фич), то матрица
линейно независимы (нет идеально скоррелированных фич), то матрица
 имеет обратную (доказательство можно посмотреть, например, в
имеет обратную (доказательство можно посмотреть, например, в

где

псевдообратная к
. Понятие псевдообратной матрицы введено в 1903 году Фредгольмом, она сыграла важную роль в работах Мура и Пенроуза.
Напомню, что обратить
и найти
 можно только если столбцы
линейно независимы. Впрочем, если столбцы
близки к линейной зависимости, вычисление
можно только если столбцы
линейно независимы. Впрочем, если столбцы
близки к линейной зависимости, вычисление
 уже становится численно нестабильным. Степень линейной зависимости признаков в
или, как говорят, мультиколлинеарности матрицы
, можно измерить числом обусловленности — отношением максимального собственного значения к минимальному. Чем оно больше, тем ближе
к вырожденной и неустойчивее вычисление псевдообратной.
уже становится численно нестабильным. Степень линейной зависимости признаков в
или, как говорят, мультиколлинеарности матрицы
, можно измерить числом обусловленности — отношением максимального собственного значения к минимальному. Чем оно больше, тем ближе
к вырожденной и неустойчивее вычисление псевдообратной.
Линейная алгебра
К решению задачи мультилинейной регрессии можно прийти довольно естественно и с помощью линейной алгебры и геометрии, ведь даже то, что в функции потерь фигурирует норма вектора ошибок уже намекает, что у задачи есть геометрическая сторона. Мы видели, что попытка найти линейную модель, описывающую экспериментальные точки, приводит к уравнению
Если количество переменных равно количеству неизвестных и уравнения линейно независимы, то система имеет единственное решение. Однако, если число измерений превосходит число признаков, то есть уравнений больше чем неизвестных — система становится несовместной, переопределенной. В этом случае лучшее, что мы можем сделать — выбрать вектор
, образ которого
 ближе остальных к
ближе остальных к
 . Напомню, что множество образов или колоночное пространство
. Напомню, что множество образов или колоночное пространство
 — это линейная комбинация вектор-столбцов матрицы
— это линейная комбинация вектор-столбцов матрицы

—
-мерное линейное подпространство (мы считаем фичи линейно независимыми), линейная оболочка вектор-столбцов
. Итак, если
принадлежит
, то мы можем найти решение, если нет — будем искать, так сказать, лучшее из нерешений.
Если в дополнение к векторам
мы рассмотрим все вектора им перпендикулярные, то получим еще одно подпространство и сможем любой вектор из
 разложить на две компоненты, каждая из которых живет в своем подпространстве. Второе, перпендикулярное пространство, можно характеризовать следующим образом (нам это понадобится в дальнейшем). Пускай
разложить на две компоненты, каждая из которых живет в своем подпространстве. Второе, перпендикулярное пространство, можно характеризовать следующим образом (нам это понадобится в дальнейшем). Пускай
 , тогда
, тогда

равен нулю в том и только в том случае, если
 перпендикулярен всем
, а значит и целому
. Таким образом, мы нашли два перпендикулярных линейных подпространства, линейные комбинации векторов из которых полностью, без дыр, «покрывают» все
. Иногда это обозначают c помощью символа ортогональной прямой суммы
перпендикулярен всем
, а значит и целому
. Таким образом, мы нашли два перпендикулярных линейных подпространства, линейные комбинации векторов из которых полностью, без дыр, «покрывают» все
. Иногда это обозначают c помощью символа ортогональной прямой суммы

где
 . В каждое из подпространств можно попасть с помощью соответствующего оператора проекции, но об этом ниже.
. В каждое из подпространств можно попасть с помощью соответствующего оператора проекции, но об этом ниже.

Теперь представим
в виде разложения


Если мы ищем решение
 , то естественно потребовать, чтобы
, то естественно потребовать, чтобы
 была минимальна, ведь это длина вектора-остатка. Учитывая перпендикулярность подпространств и теорему Пифагора
была минимальна, ведь это длина вектора-остатка. Учитывая перпендикулярность подпространств и теорему Пифагора

но поскольку, выбрав подходящий
, я могу получить любой вектор колоночного пространства, то задача сводится к

а
 останется в качестве неустранимой ошибки. Любой другой выбор
сделает ошибку только больше.
останется в качестве неустранимой ошибки. Любой другой выбор
сделает ошибку только больше.

Если теперь вспомнить, что
 , то легко видеть
, то легко видеть

что очень удобно, так как
 у нас нет, а вот
— есть. Вспомним из предыдущего параграфа, что
имеет обратную при условии линейной независимости признаков и запишем решение
у нас нет, а вот
— есть. Вспомним из предыдущего параграфа, что
имеет обратную при условии линейной независимости признаков и запишем решение

где
уже знакомая нам псевдообратная матрица. Если нам интересна проекция
, то можно записать

где
 — оператор проекции на колоночное пространство.
— оператор проекции на колоночное пространство.
Выясним геометрический смысл коэффициента детерминации.

Заметьте, что фиолетовый вектор
 пропорционален первому столбцу матрицы информации
, который состоит из одних единиц согласно нашему выбору базисных функций. В RGB треугольнике
пропорционален первому столбцу матрицы информации
, который состоит из одних единиц согласно нашему выбору базисных функций. В RGB треугольнике

Так как этот треугольник прямоугольный, то по теореме Пифагора

Это геометрическая интерпретация уже известного нам факта, что

Мы знаем, что

а значит

Красиво, не правда ли?
Произвольный базис
Как мы знаем, регрессия выполняется на базисных функциях
и её результатом есть модель

но до сих пор мы использовали простейшие
, которые просто ретранслировали изначальные признаки без изменений, ну разве что дополняли их постоянной фичей
 . Как можно было заметить, на самом деле ни вид
, ни их количество ничем не ограничены — главное чтобы функции в базисе были линейно независимы. Обычно, выбор делается исходя из предположений о природе процесса, который мы моделируем. Если у нас есть основания полагать, что точки
ложатся на параболу, а не на прямую, то стоит выбрать базис
. Как можно было заметить, на самом деле ни вид
, ни их количество ничем не ограничены — главное чтобы функции в базисе были линейно независимы. Обычно, выбор делается исходя из предположений о природе процесса, который мы моделируем. Если у нас есть основания полагать, что точки
ложатся на параболу, а не на прямую, то стоит выбрать базис
 . Количество базисных функций может быть как меньшим, так и большим, чем количество изначальных фич.
. Количество базисных функций может быть как меньшим, так и большим, чем количество изначальных фич.
гифка
Регрессия в полиномиальном базисе. Выделенная часть кода демонстрирует использование стандартных функций scikit-learn для выполнения регрессии полиномами разной степени, снизу — визуализация результата работы.
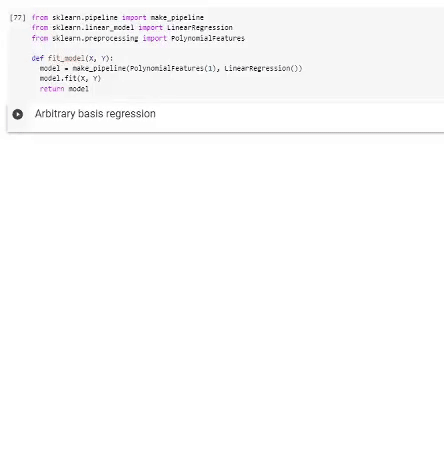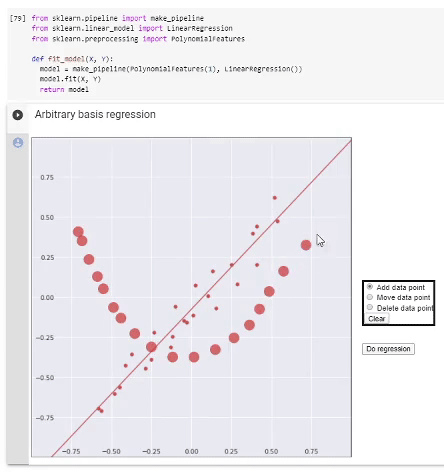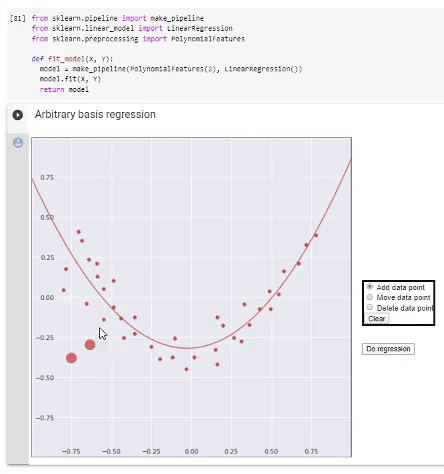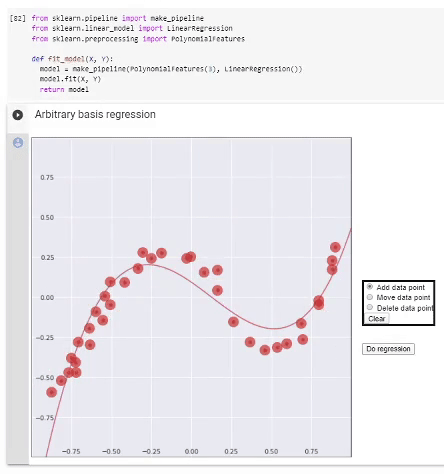
Можно
Много других материалов по классическому машинному обучению
Если мы определились с базисом, то дальше действуем следующим образом. Мы формируем матрицу информации

записываем функцию потерь

и находим её минимум, например с помощью псевдообратной матрицы

или другим методом.
Заключительные замечания
Проблема выбора размерности
На практике часто приходится самостоятельно построить модель явления, то есть определиться сколько и каких нужно взять базисных функций. Первый порыв «набрать побольше» может сыграть злую шутку: модель окажется слишком чувствительной к шумам в данных (переобучение). С другой стороны, если излишне ограничить модель, она будет слишком грубой (недообучение).
Есть два способа выйти из ситуации. Первый: последовательно наращивать количество базисных функций, проверять качество регрессии и вовремя остановиться. Или же второй: выбрать функцию потерь, которая определит число степеней свободы автоматически. В качестве критерия успешности регрессии можно использовать коэффициент детерминации, о котором уже упоминалось выше, однако, проблема в том, что
монотонно растет с ростом размерности базиса. Поэтому вводят скорректированный коэффициент

где
— размер выборки,
— количество независимых переменных. Следя за
 , мы можем вовремя остановиться и перестать добавлять дополнительные степени свободы.
, мы можем вовремя остановиться и перестать добавлять дополнительные степени свободы.
Вторая группа подходов — регуляризации, самые известные из которых Ridge(
 /гребневая/Тихоновская регуляризация), Lasso(
/гребневая/Тихоновская регуляризация), Lasso(
 регуляризация) и Elastic Net(Ridge+Lasso). Главная идея этих методов: модифицировать функцию потерь дополнительными слагаемыми, которые не позволят вектору коэффициентов
неограниченно расти и тем самым воспрепятствуют переобучению
регуляризация) и Elastic Net(Ridge+Lasso). Главная идея этих методов: модифицировать функцию потерь дополнительными слагаемыми, которые не позволят вектору коэффициентов
неограниченно расти и тем самым воспрепятствуют переобучению

где
 и
и
 — параметры, которые регулируют «силу» регуляризации. Это обширная тема с красивой геометрией, которая заслуживает отдельного рассмотрения. Упомяну кстати, что для случая двух переменных при помощи вероятностной интерпретации можно получить Ridge и Lasso регрессии, удачно выбрав априорное распределения для коэффициента
— параметры, которые регулируют «силу» регуляризации. Это обширная тема с красивой геометрией, которая заслуживает отдельного рассмотрения. Упомяну кстати, что для случая двух переменных при помощи вероятностной интерпретации можно получить Ridge и Lasso регрессии, удачно выбрав априорное распределения для коэффициента

Численные методы
Скажу пару слов, как минимизировать функцию потерь на практике. SSE — это обычная квадратичная функция, которая параметризируется входными данными, так что принципиально ее можно минимизировать методом скорейшего спуска или другими методами оптимизации. Так, реализация Lasso регрессии в scikit-learn использует метод координатного спуска.
Также можно решить нормальные уравнения с помощью численных методов линейной алгебры. Эффективный метод, который используется в scikit-learn для МНК — нахождение псевдообратной матрицы с помощью сингулярного разложения. Поля этой статьи слишком узки, чтобы касаться этой темы, за подробностями советую обратиться к курсу лекций К.В.Воронцова.
Реклама и заключение
Эта статья — сокращенный пересказ одной из глав курса классического машинного обучения в
Если хотите посмотреть на результат — загляните на
Надеюсь Вам было интересно, спасибо за внимание.
Цель этой статьи — рассказать о линейной регрессии, а именно собрать и показать формулировки и интерпретации задачи регрессии с точки зрения математического анализа, статистики, линейной алгебры и теории вероятностей. Хотя в учебниках эта тема изложена строго и исчерпывающе, ещё одна научно-популярная статья не помешает.
! Осторожно, трафик! В статье присутствует заметное число изображений для иллюстраций, часть в формате gif.
Содержание
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
-
You must be registered for see links
-
You must be registered for see links
-
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
-
You must be registered for see links
Введение
Есть три сходных между собой понятия, три сестры: интерполяция, аппроксимация и регрессия.
У них общая цель: из семейства функций выбрать ту, которая обладает определенным свойством.
В этой статье мы рассмотрим линейную регрессию. Это означает, что семейство функций, из которых мы выбираем, представляет собой линейную комбинацию наперед заданных базисных функций
Цель регрессии — найти коэффициенты этой линейной комбинации, и тем самым определить регрессионную функцию
Регрессия с нами уже давно: впервые метод опубликовал Лежандр в 1805 году, хотя Гаусс пришел к нему раньше и успешно использовал для предсказания орбиты «кометы» (на самом деле карликовой планеты) Цереры. Существует множество вариантов и обобщений линейной регрессии: LAD, метод наименьших квадратов, Ridge регрессия, Lasso регрессия, ElasticNet и многие другие.
гифка
Точки генерируются случайно по распределению Гаусса с заданным средним и вариациями. Синяя линия — регрессионная прямая.
Можно
You must be registered for see links
.Много других материалов по классическому машинному обучению
You must be registered for see links
Метод наименьших квадратов
Начнём с простейшего двумерного случая. Пусть нам даны точки на плоскости
Как видно из иллюстрации, расстояние от точки до прямой можно понимать по-разному, например геометрически — это длина перпендикуляра. Однако в контексте нашей задачи нам нужно функциональное расстояние, а не геометрическое. Нас интересует разница между экспериментальным значением и предсказанием модели для каждого
Первое, что приходит в голову, в качестве функции потерь попробовать выражение, зависящее от абсолютных значений разниц
Впрочем, более популярная функция потерь — сумма квадратов отклонений регрессанта от модели. В англоязычной литературе она носит название Sum of Squared Errors (SSE)
Метод наименьших квадратов (по англ. OLS) — линейная регрессия c
Такой выбор прежде всего удобен: производная квадратичной функции — линейная функция, а линейные уравнения легко решаются. Впрочем, далее я укажу и другие соображения в пользу
гифка
Регрессионная прямая (синяя) и пробная прямая (зеленая). Справа показана функция потерь и точки соответствующие параметра пробной и регрессионной прямых.
Можно
You must be registered for see links
.Много других материалов по классическому машинному обучению
You must be registered for see links
Математический анализ
Простейший способ найти
Значения параметров, минимизирующие функцию потерь, удовлетворяют уравнениям
которые легко решить
Мы получили громоздкие и неструктурированные выражения. Сейчас мы их облагородим и вдохнем в них смысл.
Статистика
Полученные формулы можно компактно записать с помощью статистических эстиматоров: среднего
Перепишем
где
и запишем
Теперь мы можем оценить все изящество дескриптивной статистики и записать уравнение регрессионной прямой так
Во-первых, это уравнение сразу указывает на два свойства регрессионной прямой:
- прямая проходит через центр масс
;

- если по оси
за единицу длины выбрать
, а по оси
—
, то угол наклона прямой будет от
 до
до . Это связано с тем, что
. Это связано с тем, что .
.
Во-вторых, теперь становится понятно, почему метод регрессии называется именно так. В единицах стандартного отклонения
Возведя коэффициент корреляции в квадрат, получим коэффициент детерминации
Дело в том, что вариация исходных данных разлагается в сумму двух других вариаций: вариации, которая объясняется моделью, и вариации случайного шума (остатков)
или
Как видим, стандартные отклонения образуют прямоугольный треугольник.
Мы стремимся избавиться от вариативности связанной с шумом и оставить лишь вариативность, которая объясняется моделью, — хотим отделить зерна от плевел. О том, насколько это удалось лучшей из линейных моделей, свидетельствует
или доле объясненной вариации (доля вариации регрессии в полной вариации)
Теория вероятностей
Ранее мы пришли к функции потерь
Вернемся к задаче простой регрессии. Допустим, что значения
где
Исходя из предположений выше, запишем функцию правдоподобия
и ее логарифм
Таким образом, максимум правдоподобия достигается при минимуме
что дает основание принять ее в качестве функции потерь. Кстати, если
мы получим функцию потерь LAD регрессии
которую мы упоминали ранее.
Подход, который мы использовали в этом разделе — один из возможных. Можно прийти к такому же результату, используя более общие свойства. В частности, свойство постоянства распределения можно ослабить, заменив на свойства независимости, постоянства вариации (гомоскедастичность) и отсутствия мультиколлинеарности. Также вместо ММП эстимации можно воспользоваться другими методами, например линейной MMSE эстимацией.
Мультилинейная регрессия
До сих пор мы рассматривали задачу регрессии для одного скалярного признака
Итак, мы хотим найти такой вектор (набор коэффициентов)
Знак "
Последнее уравнение можно переписать более удобным образом. Для этого расположим
Тогда столбцы матрицы
Квадрат нормы разности векторов в правой и левой частях уравнения образует функцию потерь
которую мы намерены минимизировать
Продифференцируем финальное выражение по
You must be registered for see links
)
приравняем производную к
Если столбцы матрицы информации
You must be registered for see links
). Тогда можно записать
где
псевдообратная к
Напомню, что обратить
Линейная алгебра
К решению задачи мультилинейной регрессии можно прийти довольно естественно и с помощью линейной алгебры и геометрии, ведь даже то, что в функции потерь фигурирует норма вектора ошибок уже намекает, что у задачи есть геометрическая сторона. Мы видели, что попытка найти линейную модель, описывающую экспериментальные точки, приводит к уравнению
Если количество переменных равно количеству неизвестных и уравнения линейно независимы, то система имеет единственное решение. Однако, если число измерений превосходит число признаков, то есть уравнений больше чем неизвестных — система становится несовместной, переопределенной. В этом случае лучшее, что мы можем сделать — выбрать вектор
Если в дополнение к векторам
равен нулю в том и только в том случае, если
где
Теперь представим
Если мы ищем решение
но поскольку, выбрав подходящий
а
Если теперь вспомнить, что
что очень удобно, так как
где
где
Выясним геометрический смысл коэффициента детерминации.
Заметьте, что фиолетовый вектор
Так как этот треугольник прямоугольный, то по теореме Пифагора
Это геометрическая интерпретация уже известного нам факта, что
Мы знаем, что
а значит
Красиво, не правда ли?
Произвольный базис
Как мы знаем, регрессия выполняется на базисных функциях
но до сих пор мы использовали простейшие
гифка
Регрессия в полиномиальном базисе. Выделенная часть кода демонстрирует использование стандартных функций scikit-learn для выполнения регрессии полиномами разной степени, снизу — визуализация результата работы.
Можно
You must be registered for see links
.Много других материалов по классическому машинному обучению
You must be registered for see links
Если мы определились с базисом, то дальше действуем следующим образом. Мы формируем матрицу информации
записываем функцию потерь
и находим её минимум, например с помощью псевдообратной матрицы
или другим методом.
Заключительные замечания
Проблема выбора размерности
На практике часто приходится самостоятельно построить модель явления, то есть определиться сколько и каких нужно взять базисных функций. Первый порыв «набрать побольше» может сыграть злую шутку: модель окажется слишком чувствительной к шумам в данных (переобучение). С другой стороны, если излишне ограничить модель, она будет слишком грубой (недообучение).
Есть два способа выйти из ситуации. Первый: последовательно наращивать количество базисных функций, проверять качество регрессии и вовремя остановиться. Или же второй: выбрать функцию потерь, которая определит число степеней свободы автоматически. В качестве критерия успешности регрессии можно использовать коэффициент детерминации, о котором уже упоминалось выше, однако, проблема в том, что
где
Вторая группа подходов — регуляризации, самые известные из которых Ridge(
где
Численные методы
Скажу пару слов, как минимизировать функцию потерь на практике. SSE — это обычная квадратичная функция, которая параметризируется входными данными, так что принципиально ее можно минимизировать методом скорейшего спуска или другими методами оптимизации. Так, реализация Lasso регрессии в scikit-learn использует метод координатного спуска.
Также можно решить нормальные уравнения с помощью численных методов линейной алгебры. Эффективный метод, который используется в scikit-learn для МНК — нахождение псевдообратной матрицы с помощью сингулярного разложения. Поля этой статьи слишком узки, чтобы касаться этой темы, за подробностями советую обратиться к курсу лекций К.В.Воронцова.
Реклама и заключение
Эта статья — сокращенный пересказ одной из глав курса классического машинного обучения в
You must be registered for see links
(преемник Киевского отделения Московского физико-технического института, КО МФТИ). Автор статьи помогал в создании этого курса. Технически курс выполнен на платформе Google Colab, что позволяет совмещать формулы, форматированные LaTeX, исполняемый код Python и интерактивные демонстрации на Python+JavaScript, так что студенты могут работать с материалами курса и запускать код с любого компьютера, на котором есть браузер. На
You must be registered for see links
собраны ссылки на конспекты, «рабочие тетради» для практик и дополнительные ресурсы. В основу курса положены следующие принципы:- все материалы должны быть доступны студентам с первой пары;
- лекция нужны для понимания, а не для конспектирования (конспекты уже готовы, нет смысла их писать, если не хочется);
- конспект — больше чем лекция (материала в конспектах больше, чем было озвучено на лекции, фактически конспекты представляют собой полноценный учебник);
- наглядность и интерактивность (иллюстрации, фото, демки, гифки, код, видео с youtube).
Если хотите посмотреть на результат — загляните на
You must be registered for see links
.Надеюсь Вам было интересно, спасибо за внимание.