


Оффлайн
- Регистрация
- 12.04.17
- Сообщения
- 19.095
- Реакции
- 107
- Репутация
- 0

ВСТУПЛЕНИЕ
В каком году — рассчитывай,
В какой земле — угадывай,
На столбовой дороженьке
Сошлись семь мужиков:
Семь временнообязанных,
Подтянутой губернии,
Уезда Терпигорева,
Пустопорожней волости,
Из смежных деревень:
Заплатова, Дырявина,
Разутова, Знобишина.
Горелова, Неелова —
Неурожайка тож,
Сошлися — и заспорили:
Кому живется весело,
Вольготно на Руси?
Н.Некрасов
Пару месяцев назад на одном IT мероприятии мне довелось лицезреть в работе Pandas. Парень, который с ним работал не делал ничего особенно удивительного. Но простые сложения значений, вычисления средних, группировки производились так виртуозно, что, даже при всей своей предвзятости к Питону, я был очарован. Манипуляции выполнялись на довольно приличных датасетах по данным капитального ремонта за период кажется с 2004 по 2019 год. Сотни тысяч строк, но все работало очень быстро.
В общем когда мне еще через пару месяцев пришлось кое-что анализировать, я решил попробовать сделать это с помощью Pandas. Провозился пару дней с тем, что с помощью Excel я бы смог сделать за день. Тем не менее мне удалось.
С апреля мы все сидим на карантине. Сидел я и думал, что бы мне такое сделать, чтобы не очень сложное и чтобы стильно и модно было. К тому времени я уже видел кучу всякой инфографики про коронавирус, про пожары в лесу, про выборы. Делать то, что уже делали не хотелось, да и браться сразу за сложное не решался, сомневаясь, что смогу закончить. Тут мне попалась какая-то статья про уже отшумевшее явление "barchart race" или по-русски "гонки столбчатых диаграмм". Вы можете подумать, что эта статья будет про barchart race. Да, но только отчасти. Barchart race будет только в конце, а статья скорее о том, как не обладая, какими-то выдающимися способностями и знаниями в области матана и прочей черной магии, можно сделать анализ
Идея
Сами "гонки" мне уже не раз попадались в ленте Твиттера, тогда я даже не знал, что это вот называется гонками. А узнал я об этом, когда прочитал очередную статью, возможно даже здесь на Хабре. Не помню точно как это было, помню только, что я сильно воодушевился возможностью сорвать покровы и стать первооткрывателем. Идея сделать свою гонку на базе форм бюджетной отчетности по исполнению федерального бюджета. Я довольно давно так или иначе касаюсь сферы госфинансов, но годного сравнительного анализа мне видеть не доводилось, что сильно увеличивало шансы сделать что-то новое. Взять за источник формы бюджетной отчетности круто по двум причинам:
- Эти бюрократические бумажки сильно формализованы, что делает их чуть ли не единственным государственным сырьем машиночитаемых данных.
- Отчетность делается годами с монотонной регулярностью, те кто эту отчетность готовит в стопятидесятый раз вообще не переживает, что в ней может быть что-то ценное. Поэтому отчетность в свободном доступе на сайте Казначейства и Минфина.
План был такой:
Взять как можно более длинный временной диапазон данных об исполнении федерального бюджета России. Посмотреть из каких показателей можно сделать красочную гонку ну и сделать эту гонку.
Коротко о бюджетной классификации
Как говорит наш президент: "Буду краток". Постараюсь только самую суть. Говорим только о бюджетных расходах. Все бюджетные расходы предусматриваются на какую-то конкретную цель. Эта запланированная цель отражается в коде бюджетной классификации.
КБК — 20-ти разрядный цифровой код, отражающий цель расходов, их экономический и функциональный характер. В теории, зная КБК каких-то определенных расходов, можно определить не только их цель но и способ их расходования (например, заработная плата), отрасль экономики и функцию государства, к которой расход относится и, наконец, ведомство через которое эти расходы будут производится.
По-умному это все называется функциональная, экономическая и ведомственная классификация бюджетных расходов. Структура КБК постоянно меняется, более или менее неизменными являются первые 7 разрядов КБК, а имено первые 3 — код ППП (перечень прямых получателей) разряды 4, 5 — раздел, 6, 7 — подраздел. Остальные разряды КБК меняются так часто, что даже не заглядывая в данные, можно быть уверенным, что сопоставить расходы даже двух соседних лет будет почти невозможно.
Сейчас структура КБК расходов федерального бюджета выглядит так:
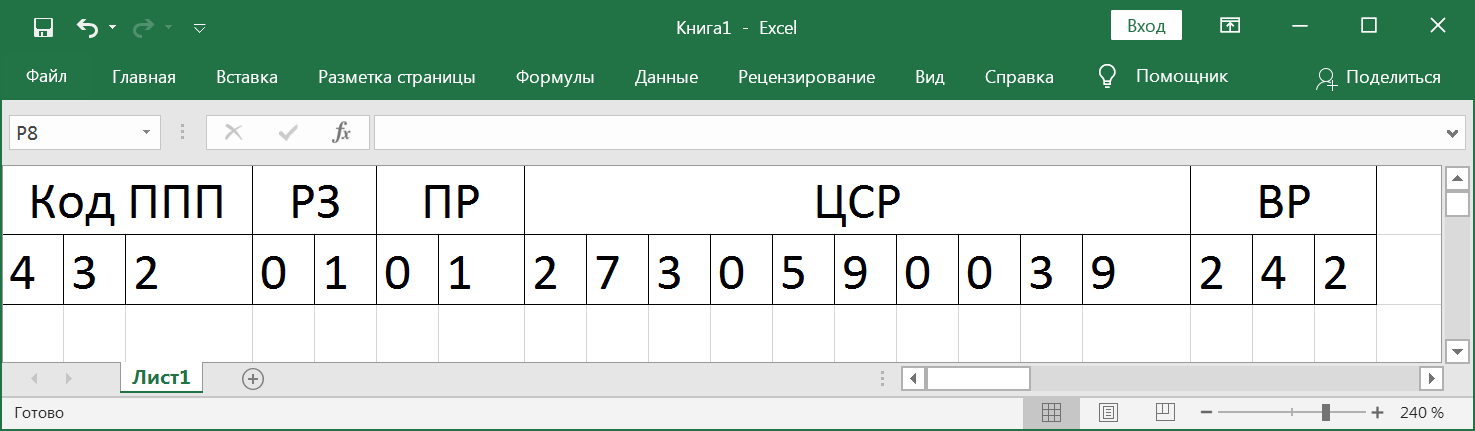
- Ведомственная классификация
- ППП — код ведомства
- Функциональная классификация
- РЗ — раздел
- ПР — подраздел
- ЦСР — целевая статья расходов
- ГП — госпрограмма
- ПП — подпрограмма
- ОМ — основное мероприятие
- НП — направление расходов
- Экономическая класссификация
- ВР — вид расходов
Классификация представляет собой иерархическую структуру, чем глубже ты погружаешься, тем более конкретными становятся расходы.
Мой первоначальный план был в том, чтобы сгруппировать расходы на уровне раздела и подраздела. Я наивно полагал, что бюрократам будет лень выдумывать новые коды и они из года в год будут использовать одни и те же. Я был прав только отчасти. Почти неизменными являются только коды ведомств. Пока ведомство существует оно имеет один и тот же код, когда ведомство умирает, его код уже не присваивается новому ведомству. Всего из 3 десятичных разрядов можно получить 10 в третьей степени вариантов, то есть тысячу комбинаций. Сейчас максимальный код у Министерства спорта. Номерок блатной три семерочки под силу пробить не каждому министру. Тут код пробивал еще сам Мутко. В бытность Госкомспорта это ведомство носило скромный номер 164. Именно с приходом Мутко Минспорта получило счастливые три семерки.
Часть первая. Наивная лобовая атака.
Довольно быстро мне удалось собрать у Казначейства и Минфина различные формы бюджетной отчетности по исполнению бюджета. Мой выбор пал на отчет по форме ОКУД 0507011, отчетность по этой форме мне удалось найти с 2002 по 2019. Остальные формы отчета об исполнении бюджета начинались где-то с 2007 года.
Попытка сопоставить коды сразу по подразделам с треском провалилась, мне не удалось найти ни одного кода подраздела, который бы не изменил своего содержания с 2002 по 2019 год.
Например, код РЗПР 0501 в 2003 был кодом "Органы внутренних дел", а в 2006 уже "Жилищное хозяйство". Даже относительно стабильные коды в 01 разделе менялись. 0103 в 2002 году был "Функционирование исполнительных органов государственной власти", а в 2005 стал уже "Функционирование законодательных (представительных) органов государственной власти и местного самоуправления".
С разделами не получилось, но я был готов к такому повороту. Следующая попытка была сгруппироваться уровнем выше, по разделам, но и здесь меня ждал неприятный сюрприз. Раздел 02 успел побыть национальной обороной и судебной властью, а раздел 03 был и международной и правоохранительной деятельностью. Менялись не только коды но и названия поэтому привязаться по названиям тоже не получалось. Такого поворота я не ждал, работа остановилась на несколько дней.
Поковыряв матчасть я наткнулся на очень интересные международные документы. Оказывается международное сообщество, в лице ООН, ОЭСР и МВФ озабоченные необходимостью сбора и анализа данных по государственным финансам разработали и в 1986 году издали эпохальный документ под названием A Manual on Government Finance Statistics (GFSM 1986).
You must be registered for see links
Труд оказался настолько удачным, что изменения в него вносились лишь дважды: в 2001 году и в 2014 году. Именно GFSM 2014 является действующей редакцией.
В составе этого мануала в 4 части есть глава "Functional classification", в которой сформулирована функциональная классификация государственных расходов. Называется она Classicifation of the Functions of Government или сокращенно COFOG. По-русски это назвали Классификацией функций органов государственного управления (КФОГУ). КФОГУ это достаточно общая, чтобы быть универсальной для любой страны иерархическая классификация. Коды КФОГУ состоят из 4 разрядов: первые 2 разряда — раздел, 3 разряд это глава и 4 разряд это класс. Судя по некоторому сходству и в нумерации и по содержанию российского КБК с международным КФОГУ, наш Минфин пытается приблизить КБК к международной классификации. Попытки продолжаются как минимум с 2002 года. Минфин с завидным упороством год, через год меняет содержание разделов и подразделов КБК, не говоря уже обо всем остальном.
В результате в России нет ни собственной функциональной классификации, ни международной.
В общем я решил привязать подразделы наших КБК к этой международной классификации COFOG, чтобы потом сгруппировать расходы именно по разделам COFOG.
Учитывая, что разделы и подразделы в российском КБК постоянно меняются, привязывать коды COFOG я решил не к кодам КБК, а к названиям. Для этого я собрал перечень всех уникальных названий подразделов отечественного КБК и сматчил их через самое короткое расстояние Левенштейна. Результат получился не очень точный, ошибки пришлось исправлять вручную. Пару дней я возился расставляя в таблице названий российских подразделов КБК правильные коды КФОГУ. Как же я обломался, когда стало понятно, что сделать это вообще невозможно, потому что в России по подразделу "Другие расходы" могут проходить и расходы на армию и на экологию, а по разделу 01 (Общие расходы) прохотят расходы из тематических разделов. Понять из каких именно тематических разделом эти расходы можно только, если каждый подраздел рассматривать отдельно по каждому ведомству, что кратно увеличивает количество. Но главное, что я уже начал сопоставление без кодов ведомств. Тут я совсем приуныл. Анализ расходов нашего государства на решение своих социально-экономических задач не удался. Снова приуныл.
Думаю: "Гори оно огнем, сделаю хоть что-то!"
Часть вторая. О том как что-то получилось.
Сделал я в итоге так. Собрал все расходы бюджета по ведомствам, сделал outer join всех лет по кодам ППП. Получилась таблица вида:
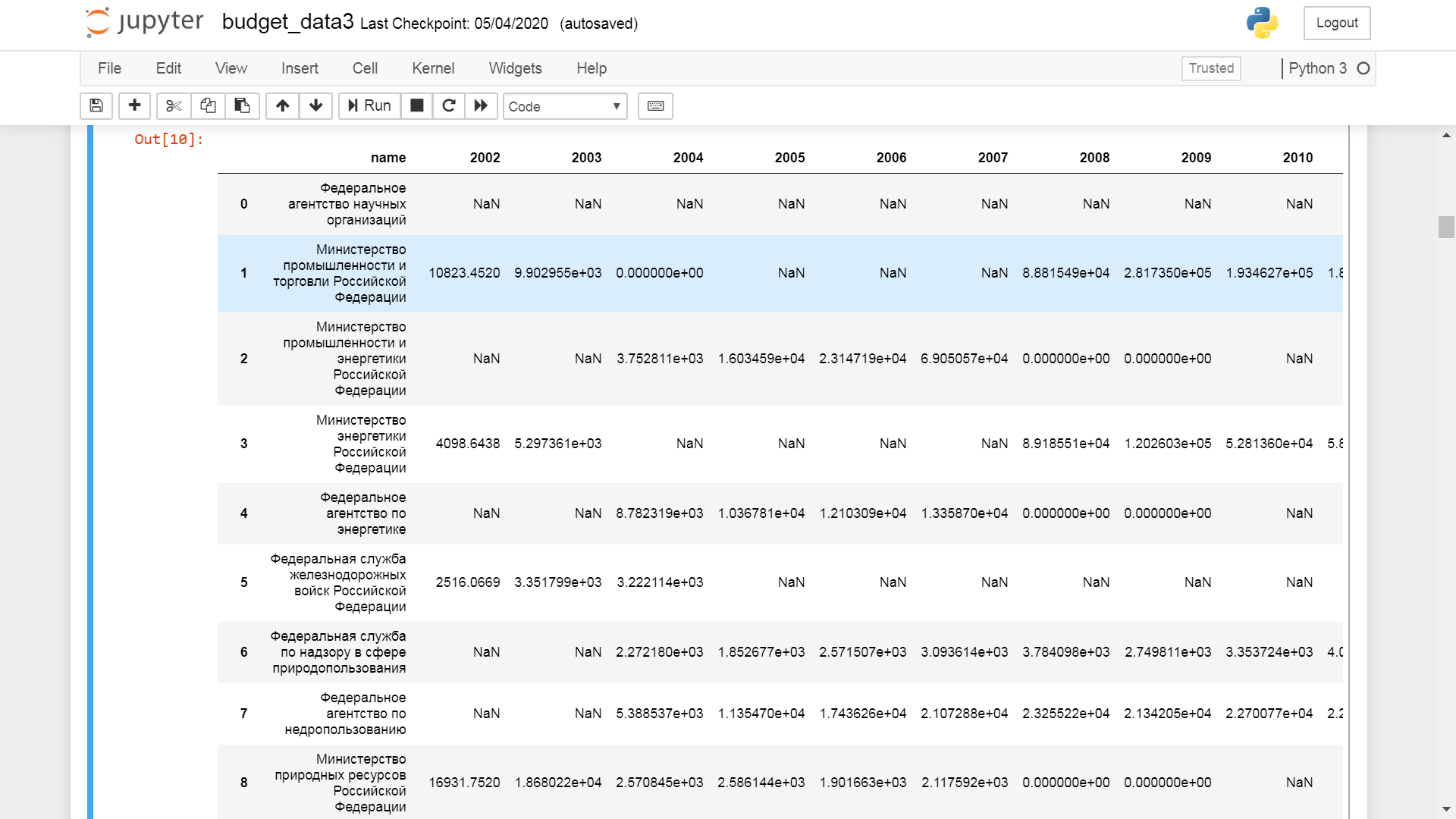
Дальше была довольно долгая и неприятная возня с названиями. В отчете об исполнении бюджета используются только полные наименования, поэтому даже у относительно коротких названий вроде Министерство спорта был хвост Российской Федерации. Просто менять Российской Федерации на РФ я не стал и названия вручную менял с официальные сокращенные. Пришлось посидеть, но зато я теперь я гораздо лучше ориентируюсь в российкой бюрократии. В период с 2002 по 2019 год существует или существовало 240 ведомств, там есть и отдельные бюджетные учреждения вроде Большого театра или Эрмитажа, но в основном там ведомства. Российская бюрократия каждый год представлена в ассортименте около 95 наименований. Если с 2002 их было 240, то каждый год за 17 лет менялось примерно 8 ведомств. Из вышепредставленной таблицы гонка получилась довольно быстро.
Посмотреть ее можете по ссылке:
Или в виде html тут:
You must be registered for see links
Видео с ведомственной группировкой получилось хорошим, но Минфин, который выполняет функции передаста по почти всем межбюджетным трансфертам просто затмевает всех остальных. А что же там у него внутри увидеть на уровне ведомства невозможно. Поэтому я отдохнул немного и снова взялся за дело.
Часть третья. Кому на нашем бюджете живется лучше других?
Пока я разбирался в хитросплетениях российского КБК я заметил 1 интересную особенность. Почти во всех ведомствах присутствовали расходы по 01 разделу, а этот раздел наиболее стабильный Владимир Путин с расходами на себя занимает в нем гордое первое место. Расходы на Президента всегда проходят по подразделу 0101.
За 17 лет его название менялось все однажды, а по содержанию это всегда расходы на Президента. Я подумал, что раз Минфин так любит проводить расходы на содержание самих ведомств по 01 разделу, то я смогу оценить т.н. "Затраты на руководство и управление" государственных функций просто сгруппировав подразделы по разделу 01. Впоследствии оказалось, что расходы на содержание ведомств проходят по 01, но так происходит далеко не всегда. Очень часто расходы проходят так, как это предусмотрено GFSM 2014, а именно расходы на управление какой-то функцией проходят по соответствующему тематическому разделу. Например, расходы на руководство полицией классифицируются по коду 70310 Руководство деятельностью полиции и связанными с ней услугами, включая регистрацию иностранцев, выдачу рабочих и проездных документов иммигрантам, ведение документации на арестованных и связанной с работой полиции статистики, регулирование дорожного движения и контроль за ним, предупреждение контрабандной деятельности и контроль за морским и океаническим рыболовным промыслом;
В отдельные годы расходы на управление проходили по 01 разделу, а в другие по какому-то тематическому. Я снова застрял в начале пути. Приходилось бросать сделанное и придумывать что-то другое. Была нужна какая-то более изощренная модель группировки. К тому времени я уже собрал для себя некоторый набор полезных функций для Pandas, которые постоянно использовал в работе. Я уже упомянал про levenshtein_merge(). С помощью этой функции можно сделать join двух Pandas DataFrame через нечеткое соответствие, а именно чере самое короткое расстояние Левенштейна. Функций становилось больше, я решил собрать их в библиотеку. Когда я начал свой бюджетный квест, это был просто класс в том же файле, что и основной проект, но сейчас это вполне годная самостоятельная библиотека, которую можно поставить через pip install и сильно облегчить себе жизнь при работе с Pandas DataFrame. Библиотеку я назвал полуфабрикат, что в переводе на английский будет prepack.
Сейчас без четверти 2 и я уже немного утомился, поэтому постараюсь продолжить статью в формате комментариев кода jupyter notebook в котором я и проводил все манипуляции.
# Сначала импорт нужных модулей
import pandas as pd
import numpy as np
import os, sys
# это мой модуль полуфабрикат
from prepack import prepack as pp
# Это настройки отображения данных в блокноте
pd.options.display.max_rows = 2000
pd.options.display.max_columns = 200
pd.options.display.max_colwidth = 500
pd.options.display.min_rows = 40
А вот здесь начинает работать полуфабрикат prepack. Этой функцией считывается zip архив. Содержимое архива возвращается в виде перечня имен файлов из архива и file-like объектов,
которые можно обрабатывать дальше. К примеру через pd.read_excel(), если в архиве файлы excel.
names, files = pp.read_zip("raw_data.zip")
Эта простая функция отличается от pd.read_excel() только тем, что меняет параметры открытия excel по умолчанию
Мой read_excel читает весь excel как текст, и не пытается взять заголовки колонок из первой строки.
Я открываю начало файла, чтобы правильно задать параметры для массового чтения всех файлов в архиве. По структуре файлы
не отличаются. Я задаю параметры для одного файла, а подходят они и ко всем остальным.
pp.read_excel(files[0]).iloc[8:13,:]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | (тыс. руб.) | (тыс. руб.) | � | |||||||||||||||||||||||||
| 9 | Наименование показателя | Код по бюджетной \nклассификации | Коды ФКР | Коды ЦСР | Коды ВР | Утверждено Федеральным законом «О федеральном бюджете на 2002 год» | Уточненная сводная бюджетная роспись | Финансирование | Лимиты бюджетных обязательств | Исполнено | Процент исполнения уточненной сводной бюджетной росписи по финансировагию | Процент исполнения уточненной сводной бюджетной росписи,% | � | |||||||||||||||
| 10 | ППП | РзПр | ЦСР | ВР | � | |||||||||||||||||||||||
| 11 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 8 | 9 | 10 | 10 | � | |||||||||||||||
| 12 | Министерство энергетики Российской Федерации | 020 | 10443678.700000001 | 10823452 | 10307275.3 | 10259178.000000002 | 95.23094203217238 | 94.78656162562555 | � |
Эта функцию я очень люблю, она сильно экономит время. Делает она вот что. Читает сразу несколько файлов excel, соединяя их
в 1 большой DataFrame, сразу задавая правильные заголовки и убирая мусор из файла, оставляя только данные.
Функции нужно минимум 3 первых аргумента: files, columns, fltr. Первый аргумент это список excel файлов, второй аргумент — горизонтальные границы данных в файле, нужно указать первый и последний столбец с данными. Третий аргумент — фильтры, которые
будут применены ко всем файлам, чтобы убрать пустые строки в конце и заголовки в начале каждого файла файла. 4 аргумент
опциональный. С его помощью можно укзаать в каких столбах первого файла есть заголовки.
Изучив первый файл, который я открыл выше можно видеть, что данные с 0 по 11 столбец, а данные только в тех строках, где
в первом столбце текст, а во втором число. Этих двух фильтров достаточно, чтобы убрать весь мусок. Заголовки у нас 3 столбцах:
8,9,10
# считывает все наши данные в 1 большой DataFrame
df = pp.parse_excels(files, columns=[0,12], fltr={0: 'istext',1: 'isnum'}, header=[8,9,10])
#смотрим, что получилось
df.head(5)
| Наименование показателя | Код по бюджетной классификации ППП | Коды ФКР РзПр | Коды ЦСР ЦСР | Коды ВР ВР | Утверждено Федеральным законом «О федеральном бюджете на 2002 год» | Уточненная сводная бюджетная роспись | Финансирование | Лимиты бюджетных обязательств | (тыс. руб.) Исполнено | Процент исполнения уточненной сводной бюджетной росписи по финансировагию | Процент исполнения уточненной сводной бюджетной росписи,% | src_filename |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Министерство энергетики Российской Федерации | 020 | 10443678.700000001 | 10823452 | 10307275.3 | 10259178.000000002 | 95.23094203217238 | 94.78656162562555 | 2002 | � | ||
| 1 | Государственное управление и местное самоуправление | 020 | 0100 | 158826.9 | 153149.8 | 153149.8 | 150806.5 | 100 | 98.46992944163166 | 2002 | � | |
| 2 | Функционирование исполнительных органов государственной власти | 020 | 0103 | 158826.9 | 153149.8 | 153149.8 | 150806.5 | 100 | 98.46992944163166 | 2002 | � | |
| 3 | Центральный аппарат | 020 | 0103 | 037 | 147458.5 | 141865 | 141865 | 140224.4 | 100 | 98.84354844394319 | 2002 | � |
| 4 | Денежное содержание аппарата | 020 | 0103 | 037 | 027 | 80921.6 | 75448.3 | 75448.3 | 74517.7 | 100 | 98.76657260667237 | 2002 |
Еще 1 полезная функция из библиотеки, это обертка для pickle, начиная с версии prepack 0.4.2 умеет читать и писать в pkl.gz
# сохраняем в файл
df.to_csv('raw_data.csv.gz')
pp.save(df, 'raw_data.pkl.gz')
Одна из основных функций prepack. С ее помощью можно фильтровать DataFrame, получаяя вектор с булевой маской
Первым аргументом задается сам фильтруемый DataFrame, второым задается фильтр, а третий аргумент определяет, будут
ли использованы названия столбцов или их индексы. Сейчас я адресуюсь по индексам, поэтому 3 аргумент iloc=True.
Первое что нужно сделать это получить список всех названий ведомств, для этого я получу из массива строки, где
заполнено "наименоавние показателя" и "код ППП", остальные части КБК должны быть пустыми. Именно в этих строках записаны
названия ведомств
# тут будут только названия получателей и их коды ППП
f = pp.df_filter_and(df, {0: 'istext', 1: 'isnum', 2: 'isblank', 3: 'isblank'}, iloc=True)
ppp = df[f]
idx = ppp['Наименование показателя'].index
ppp = ppp.loc[idx,:]
Теперь я сделаю функции, которые позволят мне вырезать из DataFrame нужные строки по фильтру, а с полученными строками делать небольшой постпроцессинг.
#эта функция позволяет вырезать строки из фрейма по фильтру, сохраняя вырезанное отдельно
def df_filter(df, fltr):
f = pp.df_filter_and(df, fltr)
res = df[f]
df.drop(res.index, axis=0, inplace=True)
return res
Этой функцией я буду готовить наборы критериев, по которым буду выбирать из общего DataFrame нужные строки
На входе общих датафрейм, фильтр для фильтрации нужных названий ведомств, чтобы записать их коды ППП. Дальше передается
список подразделов КБК, которые нужно брать в расчет. Последний аргумент label задает дополнительный критерий для
поиска по целевым статьям. Это нужно для того, чтобы выбрать такие расходы на содержание ведомства, которые только часть
подраздела, что не позволяет включать такой родительский подраздел полностью.
def df_filter_post_proc(df, fltr, rzpr, label):
df_ = df_filter(df, fltr)
codes = df_['Код по бюджетной классификации ППП'].unique()
names = df_['Наименование показателя'].unique()
return {'name': list(names), 'ppp': list(codes), 'rzpr': list(rzpr), 'label': list(label)}
Здесь функция, в которой происходит основная работа. Получилось довольно громоздко, но оптимизировать не стану, все равно функция только на 1 раз. Делает она вот что. Сначала получаем срез массива df по кодам ППП у группы и кодам подразделов. Потому получаем срез по тем же заданным кодам ППП, но уже те строки, где указаны целевые статьи, ищем нужные целевые статьи по их характерным названиям. Дальше можно было бы просто сложить эти срезы и отправить в результат по группе для последующего сложения сумм. Но ведь у нас иерархическая структура. Если найденная целевая статья будет из найденного подраздела, то сумма по этой целевой статье посчитается дважды: 1 раз по строке самой целевой статьи, а второй раз в составе суммы по подразделу. Поэтому нужно найти пересечение двух этих срезов. В случае если есть пересечение по коду ППП и подразделу, тогда из второго среза такую строку убираем.
То что останется во втором срезе вместе с первым срезом записываем в результат для этой группы и переходим к следующей группе.
# основная функция в которой и проиходит выборка нужных строк для каждой нужной нам функции
def groups_fill(df, groups):
res = pd.DataFrame([])
for g in groups:
el = groups[g]
ppp = el['ppp']
rzpr = el['rzpr']
label = el['label']
#Если кодов ppp нет, то искать нечего - пропускаем цикл
if len(ppp) == 0:
continue
#тут 1 фильтр по кодам
f1 = {'Код по бюджетной классификации ППП': ppp}
#тут 2 фильтр по тем подразделам, которые можно считать расходами на управление
f2 = {'Коды ФКР РзПр': rzpr}
#тут 3 фильтр, что убрать лишние строки с кодами статей
f3 = {'Коды ЦСР ЦСР': 'isblank'}
#тут 3 фильтр, что убрать лишние строки с видами расходов
f4 = {'Коды ВР ВР': 'isblank'}
#маски по фильтрам
m1 = pp.df_filter_or(df, f1)
m2 = pp.df_filter_or(df, f2)
m3 = pp.df_filter_or(df, f3)
m4 = pp.df_filter_or(df, f4)
#соединим все маски в одну через логическое и
df1 = df[m1 & m2 & m3 & m4]
#Второй срез будет по кодам ppp, кодам ВР и label (наименованию показателя)
#по кодам ppp и кодам ВР маски уже есть
df_ = df[m1 & m4]
f5 = {'Наименование показателя': label}
m5 = pp.df_filter_or(df_, f5)
df2 = df_[m5].copy()
#для исключения дублирования двух срезов надо убрать те позиции в label (df2), раздел/подраздел которых
#совпадает с заданными разделами/подразделами в rzpr (df1). Это делается потому что если label указан для ЦСР,
#а РЗ/ПР совпадает, то общая сумма по РЗ/ПР уже включает в себя сумму, которая указана в строке с ЦСР.
#пересечение ищем только для совпадений сразу по 3 параметрам: ППП, РЗПР, год (src_filename)
#сначала найдем пересечение df1 и df2
#нам нужны будут индексы из df2, поэтому сохраним их
df2['idx'] = df2.index
intersect = pd.merge(df1.loc[:,['Код по бюджетной классификации ППП','Коды ФКР РзПр', 'src_filename']],
df2.loc[:,['Код по бюджетной классификации ППП','Коды ФКР РзПр', 'src_filename','idx']],
on=['Код по бюджетной классификации ППП','Коды ФКР РзПр', 'src_filename'], how='inner')
#удалим найденные строки из df2 по индексу
df2_filtered = df2.drop(intersect['idx'], axis=0)
#теперь то, что есть в df1 и df2 соединяем в 1 срез, через копирование данных
df3 = pd.concat([df1, df2_filtered], axis=0)
v = df3[['Наименование показателя',
'Код по бюджетной классификации ППП',
'Коды ФКР РзПр',
'(тыс. руб.) Исполнено',
'src_filename']].copy()
#добавим столбец имя
v['name'] = g
#добавим все в итоговый датафрейм
res = pd.concat([res, v], axis=0)
return res
Теперь зададим сами группы и критерии для включения записей в них.
Концепция работы следущая:
- для каждой группы формируем список ведомств, входящих в эту группу.
- Дальше выбираем там расходы из подразделов с 0101 по 0107 в этих подразделах в период с 2002 по 2019 только расходы на содержание ведомств.
- Задаем ключевые слова для поиска целевых статей, которые помимо подразделов с 0101 по 0107 будут включены в расходы. В основном это будут общие ключевые слова, но для некоторых групп задаются дополнительные.
lst = {}
#это стандартные подразделы для расходов на собственное содержание ОИВ
rzpr_base = ['0101','0102','0103','0104','0105','0106','0107']
#Это стандартная ЦСР для расходов на содержание
label_base = ['Руководство и управление в сфере установленных функций',
r'contains=.*(?:Обеспечение.*аппарата).*',
r'contains=.*(?:обеспечение функций государственных органов).*',
r'contains=.*(?:обеспечение функций органов.*власти).*'
]
# Тут идут сами группы и заданные для них параметры для фильтрации
f = {'Наименование показателя': r'contains=.*(?:избирательная комиссия).*'}
rzpr = ['isblank']
df_slice = df_filter_post_proc(ppp, f, rzpr, label_base)
lst['выборы'] = df_slice
rzpr = ['0101','0102','0103','0104','0105','0106','0107','0201']
f = {'Наименование показателя': r'contains=.*(?:армии|оборон|внешней разведки|боеприпас|вооружен|военн).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['армия'] = df_slice
rzpr = ['0101','0102','0103','0104','0105','0106','0107','0201']
f = {'Наименование показателя': r'contains=.*(?:чрезвычайн|медико-биологическ|государственным резервам).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['ГО ЧС'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:надзор|контрол|инспекц).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['надзор и контроль'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:космос|космическ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['космос'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:государственная дума|совет федерации).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['федеральное собрание'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:счетная палата).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['счетная палата'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:культур|художеств|зодчеств|живопис|большой театр|эрмитаж|фонд кинофильмов).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['культура'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:наук|научн|фундаментальных исследований|курчатовский институт|образован|просвещения|университет).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['наука и образование'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:налог).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['налоги'] =df_slice
f = {'Наименование показателя': r'contains=.*(?:имуществ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['имущество'] =df_slice
f = {'Наименование показателя': r'contains=.*(?:финансов|казначейство|ценных бумаг|финансовых).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['финансы'] =df_slice
f = {'Наименование показателя': r'contains=.*(?:метролог|стандартизац|статистик|архив).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['статистика, стандартизация и архив'] =df_slice
f = {'Наименование показателя': r'contains=.*(?:аккредитац|интеллектуальной собственности|алкогольного рынка|тариф|патент|лицензирован|антимонопольн|экономик|экономическими зонами|экономического развития|экономических реформ|содействия развитию|экономической конъюнктуры).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['экономика, тарифы, патенты, лицензии'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:таможн|таможенная).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['таможня'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:кадастр|картограф|регистрацион).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['кадастр и картография'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:судостроен|промышленности|энергетик|энергетическая|атомной).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['промышленность и энергетика'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:транспорт|навигацион|дорожн).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['транспорт'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:телеграф|связи|коммуникац|информационным технолог|системам управления|фельдъегер).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['связь'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:правительство).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['правительство'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:президент).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['президент'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:прокуратур|следственный комитет|внутренних дел|миграцион|национальной гвардии|служба безопасности|служба охраны).*'}
label = label_base.copy()
label = label + ['Органы прокуратуры','Военная реформа']
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['прокуратура, полиция и спецслужбы'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:конституционный|верховный суд|арбитражный суд|судебный департамент).*'}
label = label_base.copy()
label = label + ['Судебная власть']
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label)
lst['суды'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:пристав).*'}
label = label_base.copy()
label = label + [r'contains=.*судебных приставов.*']
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label)
lst['судебные приставы'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:юстиции|исполнения наказаний).*'}
label = label_base.copy()
label = label + ['Уголовно-исполнительная система']
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label)
lst['тюрьмы'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:сельск|рыболовств).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['сельское хозяйство'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:водных ресурсов|недропользован|природных|экологии|лесного хозяйства|метеоролог).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['экология, вода, недра, метеорология'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:жилищн|регионального развития|строительств).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['ЖКХ'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:здравохранения|здравоохранен|медицинс|социальной защиты|социального развития).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['здравохранение и соцзащита'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:спорт).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['спорт'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:труд[ау]|занятост).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['занятость'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:пенсионный фонд|фонд социального страхования).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['пенсионный фонд и фонд соцстрахования'] = df_slice
f = {'Наименование показателя': r'contains=.*(?:иностранных дел).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['пенсионный фонд и фонд соцстрахования'] = df_slice
#прочие министерства агентства и службы
f = {'Наименование показателя': r'contains=.*министерство.*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['прочие министерства'] = df_slice
f = {'Наименование показателя': r'contains=.*агентств.*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['прочие агентства'] = df_slice
f = {'Наименование показателя': r'contains=.*служба.*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['прочие службы'] = df_slice
# все что осталось
f = {'Наименование показателя': r'contains=.*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst['прочие'] = df_slice
Когда группы и фильтр в них настроены, проверим, что получилось.
# посмотрим, сколько ведомств получилось по каждой группе
for group in lst:
el = lst[group]
print(len(el['name']), group, 'ppp:', '|'.join(el['ppp']))
print('осталось', len(ppp))
1 выборы ppp: 308
11 армия ppp: 125|126|177|464|722|184|187|186|721|185
3 ГО ЧС ppp: 160|171|388
23 надзор и контроль ppp: 083|316|497|204|048|059|060|077|079|081|093|106|141|151|498|587|086|085|087|096
3 космос ppp: 258|259|730
2 федеральное собрание ppp: 330|333
1 счетная палата ppp: 305
20 культура ppp: 056|164|166|409|424|425|591|597|057|058|167|175|054
35 наука и образование ppp: 075|139|190|226|319|386|401|423|486|494|573|589|677|693|073|074|144|385|595|384|007
3 налоги ppp: 181|205|182
3 имущество ppp: 163|166|167
7 финансы ppp: 092|520|720|723|521|724|100
6 статистика, стандартизация и архив ppp: 149|154|159|155|157|172
13 экономика, тарифы, патенты, лицензии ppp: 140|162|165|197|263|161|168|307|142|139|160
1 таможня ppp: 153
6 кадастр и картография ppp: 071|156|072|173|321
10 промышленность и энергетика ppp: 020|099|129|306|021|023|101|143|022|725
7 транспорт ppp: 029|104|103|107|108|109|110|179
12 связь ppp: 078|089|128|134|397|201|070|084|088|135|071
0 правительство ppp:
6 президент ppp: 206|303|352|588|304
10 прокуратура, полиция и спецслужбы ppp: 153|188|415|189|202|192|416|417|180
4 суды ppp: 434|436|437|438
1 судебные приставы ppp: 322
2 тюрьмы ppp: 318|320
4 сельское хозяйство ppp: 076|082|080|085
7 экология, вода, недра, метеорология ppp: 050|158|049|052|053|169|051
6 ЖКХ ppp: 133|279|132|309|360|069
7 здравохранение и соцзащита ppp: 054|148|387|055|061|064|056|149
2 спорт ppp: 777
1 занятость ppp: 150
1 пенсионный фонд и фонд соцстрахования ppp: 310
5 прочие министерства ppp: 022|350|340|370
5 прочие агентства ppp: 174|091|095|260|380
0 прочие службы ppp:
3 прочие ppp: 152|302|090
осталось 0
# посмотрим сколько ведомств не попалу ни в одну из тематических групп, но попало сюда
lst['прочие агентства']
{'name': ['Федеральное агентство по туризму',
'Федеральное агентство по делам молодежи',
'Федеральное агентство по делам Содружества Независимых Государств, соотечественников, проживающих за рубежом, и по международному гуманитарному сотрудничеству',
'Федеральное агентство по обустройству государственной границы Российской Федерации',
'Федеральное агентство по делам национальностей'],
'ppp': ['174', '091', '095', '260', '380'],
'rzpr': ['0101', '0102', '0103', '0104', '0105', '0106', '0107'],
'label': ['Руководство и управление в сфере установленных функций',
'contains=.*(?:Обеспечение.*аппарата).*',
'contains=.*(?:обеспечение функций государственных органов).*',
'contains=.*(?:обеспечение функций органов.*власти).*']}
Теперь запустим основную функцию, которая соберет данные по созданным группам.
# запустим основную функцию, передав ей в качестве аргументов список с группами и настройками фильтров к ним
df2 = groups_fill(df,lst)
# Смотрим, что получилось
df2
| Наименование показателя | Код по бюджетной классификации ППП | Коды ФКР РзПр | (тыс. руб.) Исполнено | src_filename | name | � |
|---|---|---|---|---|---|---|
| 3220 | Центральная избирательная комиссия Российской Федерации | 308 | 1518661.7000000002 | 2002 | выборы | � |
| 7896 | Центральная избирательная комиссия Российской Федерации | 308 | 9827426.6 | 2003 | выборы | � |
| 13252 | Центральная избирательная комиссия Российской Федерации | 308 | 727006.7 | 2004 | выборы | � |
| 18372 | Центральная избирательная комиссия Российской Федерации | 308 | 2315399.80987 | 2005 | выборы | � |
| 24253 | Центральная избирательная комиссия Российской Федерации | 308 | 2450335.73052 | 2006 | выборы | � |
| 30681 | Центральная избирательная комиссия Российской Федерации | 308 | 11218927.1657 | 2007 | выборы | � |
| 40626 | Центральная избирательная комиссия Российской Федерации | 308 | 4199158.0443899995 | 2008 | выборы | � |
| 52179 | Центральная избирательная комиссия Российской Федерации | 308 | 3063409.77061 | 2009 | выборы | � |
| 62733 | Центральная избирательная комиссия Российской Федерации | 308 | 3042519.67003 | 2010 | выборы | � |
| 72953 | Центральная избирательная комиссия Российской Федерации | 308 | 11343783.96668 | 2011 | выборы | � |
| 91622 | Центральная избирательная комиссия Российской Федерации | 308 | 13596252.48087 | 2012 | выборы | � |
| 111864 | Центральная избирательная комиссия Российской Федерации | 308 | 3329199.29163 | 2013 | выборы | � |
| 131099 | Центральная избирательная комиссия Российской Федерации | 308 | 4392301.7968500005 | 2014 | выборы | � |
| 149219 | Центральная избирательная комиссия Российской Федерации | 308 | 3237166.95 | 2015 | выборы | � |
| 170925 | Центральная избирательная комиссия Российской Федерации | 308 | 15800336.160000002 | 2016 | выборы | � |
| 195070 | Центральная избирательная комиссия Российской Федерации | 308 | 6073661.12 | 2017 | выборы | � |
| 221000 | Центральная избирательная комиссия Российской Федерации | 308 | 18414539.61 | 2018 | выборы | � |
| 247026 | Центральная избирательная комиссия Российской Федерации | 308 | 2237048.2 | 2019 | выборы | � |
| 18375 | Руководство и управление в сфере установленных функций | 308 | 0107 | 709851.8584799999 | 2005 | выборы |
| 24256 | Руководство и управление в сфере установленных функций | 308 | 0107 | 776471.9299999999 | 2006 | выборы |
| ... | ... | ... | ... | ... | ... | ... |
| 3035 | Прочие расходы на общегосударственное управление | 302 | 0105 | 57201.7 | 2002 | прочие |
| 7723 | Прочие расходы на общегосударственное управление | 302 | 0105 | 63374.3 | 2003 | прочие |
| 13055 | Прочие расходы на общегосударственное управление | 302 | 0105 | 70769.9 | 2004 | прочие |
| 18205 | Руководство и управление в сфере установленных функций | 302 | 0115 | 96531.57899 | 2005 | прочие |
| 24063 | Руководство и управление в сфере установленных функций | 302 | 0115 | 114431.64898 | 2006 | прочие |
| 26993 | Руководство и управление в сфере установленных функций | 090 | 0115 | 2614.72679 | 2007 | прочие |
| 30479 | Руководство и управление в сфере установленных функций | 302 | 0115 | 137220.76789999998 | 2007 | прочие |
| 35246 | Руководство и управление в сфере установленных функций | 090 | 0114 | 0 | 2008 | прочие |
| 40281 | Руководство и управление в сфере установленных функций | 302 | 0114 | 166654.65854 | 2008 | прочие |
| 51820 | Руководство и управление в сфере установленных функций | 302 | 0114 | 176770.48262000002 | 2009 | прочие |
| 62366 | Руководство и управление в сфере установленных функций | 302 | 0114 | 173045.54285 | 2010 | прочие |
| 72563 | Руководство и управление в сфере установленных функций | 302 | 0113 | 167953.68991000002 | 2011 | прочие |
| 90966 | Руководство и управление в сфере установленных функций | 302 | 0113 | 178229.35486999998 | 2012 | прочие |
| 111207 | Руководство и управление в сфере установленных функций | 302 | 0113 | 227229.21458 | 2013 | прочие |
| 130549 | Расходы на обеспечение функций государственных органов, в том числе территориальных органов, по непрограммному направлению расходов 'Обеспечение деятельности Уполномоченного по правам человека в Российской Федерации' в рамках непрограммного направления деятельности 'Уполномоченный по правам человека в Российской Федерации' | 302 | 0113 | 42004.586409999996 | 2014 | прочие |
| 148654 | Расходы на обеспечение функций государственных органов, в том числе территориальных органов, по непрограммному направлению расходов 'Обеспечение деятельности Уполномоченного по правам человека в Российской Федерации' в рамках непрограммного направления деятельности 'Уполномоченный по правам человека в Российской Федерации' | 302 | 0113 | 49886.67 | 2015 | прочие |
| 170236 | Расходы на обеспечение функций государственных органов, в том числе территориальных органов | 302 | 0113 | 53390.83 | 2016 | прочие |
| 194281 | Расходы на обеспечение функций государственных органов, в том числе территориальных органов | 302 | 0113 | 56313.880000000005 | 2017 | прочие |
| 220127 | Расходы на обеспечение функций государственных органов, в том числе территориальных органов | 302 | 0113 | 72847.51000000001 | 2018 | прочие |
| 246185 | Расходы на обеспечение функций государственных органов, в том числе территориальных органов | 302 | 0113 | 46021.01 | 2019 | прочие |
2970 rows × 6 columns
# тут мы поменяем тип данных в столбце с суммой
df3 = df2.loc[:,['(тыс. руб.) Исполнено', 'src_filename', 'name']]
#новые названия столбцов
df3.columns = ['value', 'year', 'name']
#индекс тех строк, где пусто
idx = df3[df3.loc[:,'value'] == ''].index
#меняем на 0
df3.loc[idx, 'value'] = '0.0'
#ставим тип float64
df3 = df3.astype({'value': 'float64'})
# группируем данные по году и названию группы
df4 = df3.groupby(['year','name']).sum().reset_index()
#функция для создания таблицы с группами и расходами по годам
def manuscript(df):
res = pd.DataFrame([])
for i in df.index:
n = df.loc[i,'name']
y = df.loc[i,'year']
v = df.loc[i,'value']
res.loc[n,y] = v
res['name'] = res.index
#так я перемещу последний столбец в начало
last_idx = res.shape[1] - 1
order = [last_idx]
order = order + list(range(0, last_idx))
res = res.iloc[:,order]
return res
# запускаем функцию и смотрим результат ее работы
df5 = manuscript(df4)
df5
| name | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | � |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ЖКХ | ЖКХ | 55118.3 | 69206.0 | 174787.2 | 3.179523e+05 | 4.059359e+05 | 6.988135e+05 | 8.693810e+05 | 1.227829e+06 | 1.197151e+06 | 1.499655e+06 | 1.472361e+06 | 1.485361e+06 | 1.113370e+06 | 8.331200e+05 | 1.149470e+06 | 1.293278e+06 | 1.228704e+06 | 7.812578e+05 |
| армия | армия | 199462.9 | 291924.9 | 468451.0 | 4.028164e+06 | 4.184440e+06 | 1.308096e+07 | 5.179386e+07 | 2.047398e+07 | 2.367009e+07 | 2.389663e+07 | 2.879189e+07 | 3.625769e+07 | 4.483317e+06 | 3.927149e+05 | 1.936604e+07 | 1.814460e+07 | 1.823454e+07 | 1.212784e+07 |
| выборы | выборы | 1518661.7 | 9827426.6 | 727006.7 | 3.025252e+06 | 3.226808e+06 | 1.215190e+07 | 5.344751e+06 | 4.289653e+06 | 4.252440e+06 | 1.255509e+07 | 1.480231e+07 | 4.778233e+06 | 5.448697e+06 | 3.489300e+06 | 2.632606e+07 | 6.440813e+06 | 3.324976e+07 | 2.636338e+06 |
| здравохранение и соцзащита | здравохранение и соцзащита | 6888901.5 | 5191349.3 | 496970.0 | 5.117778e+05 | 7.624081e+05 | 9.944042e+05 | 1.535074e+06 | 2.527582e+06 | 2.513591e+06 | 3.070057e+06 | 3.095424e+06 | 3.213713e+06 | 2.043384e+06 | 1.630418e+06 | 1.984821e+06 | 2.008460e+06 | 2.020177e+06 | 6.730164e+05 |
| имущество | имущество | 794096.1 | 943669.8 | 1236022.8 | 1.143905e+06 | 1.359334e+06 | 1.644650e+06 | 2.372177e+06 | 4.427220e+06 | 4.299786e+06 | 6.742122e+06 | 5.628042e+06 | 5.303888e+06 | 1.711631e+06 | 1.495427e+06 | 1.285239e+06 | 1.296881e+06 | 1.219905e+06 | 6.484055e+05 |
| кадастр и картография | кадастр и картография | 604832.7 | 779822.5 | 930441.0 | 9.573190e+06 | 1.463692e+07 | 1.815751e+07 | 2.795691e+07 | 2.301704e+07 | 2.195236e+07 | 2.351573e+07 | 3.705156e+07 | 2.353878e+07 | 1.119027e+07 | 1.172543e+07 | 1.373801e+07 | 1.051243e+07 | 1.111666e+07 | 5.087854e+06 |
| космос | космос | 56971.8 | 70000.6 | 98668.3 | 1.181241e+05 | 1.383519e+05 | 1.828012e+05 | 2.497096e+05 | 3.089730e+05 | 3.540486e+05 | 3.443083e+05 | 3.396623e+05 | 3.611192e+05 | 1.789257e+06 | 2.145743e+06 | 7.194247e+06 | 1.714675e+06 | 1.333223e+06 | 2.213795e+05 |
| культура | культура | 244286.1 | 251179.4 | 1125325.4 | 1.436764e+06 | 1.773667e+06 | 2.067159e+06 | 2.920725e+06 | 4.878187e+06 | 4.813045e+06 | 7.640206e+06 | 8.280279e+06 | 7.615266e+06 | 3.322063e+06 | 2.750865e+06 | 2.331090e+06 | 2.500820e+06 | 2.482645e+06 | 1.073571e+06 |
| надзор и контроль | надзор и контроль | 856340.8 | 1027204.1 | 6176704.0 | 1.717242e+07 | 2.367843e+07 | 2.996330e+07 | 3.597592e+07 | 3.839959e+07 | 3.769431e+07 | 3.900493e+07 | 3.809575e+07 | 3.996433e+07 | 1.205323e+07 | 1.187536e+07 | 8.373596e+06 | 8.764745e+06 | 9.350644e+06 | 5.261310e+06 |
| налоги | налоги | 24294501.9 | 29965687.1 | 34938483.1 | 4.267415e+07 | 6.058325e+07 | 9.738464e+07 | 1.066937e+08 | 1.017134e+08 | 9.750056e+07 | 1.020170e+08 | 1.049288e+08 | 1.095579e+08 | 1.235494e+08 | 1.183094e+08 | 1.295426e+08 | 1.401987e+08 | 1.641590e+08 | 1.168560e+08 |
| наука и образование | наука и образование | 256746.5 | 314463.2 | 320622.2 | 3.843661e+05 | 4.614256e+05 | 5.944249e+05 | 4.372921e+06 | 6.078403e+06 | 5.492050e+06 | 6.231623e+06 | 6.255479e+06 | 6.830796e+06 | 4.332645e+06 | 7.610444e+06 | 7.112033e+06 | 5.669845e+06 | 6.670268e+06 | 2.440637e+06 |
| пенсионный фонд и фонд соцстрахования | пенсионный фонд и фонд соцстрахования | 738567.6 | 937116.8 | 1655342.4 | 1.473230e+07 | 1.436403e+07 | 2.029405e+07 | 2.347219e+07 | 3.066014e+07 | 3.164116e+07 | 3.242956e+07 | 3.368836e+07 | 3.491896e+07 | 3.741200e+07 | 6.415048e+07 | 5.411862e+07 | 3.814101e+07 | 3.722678e+07 | 2.967170e+07 |
| президент | президент | 3982138.7 | 5450851.3 | 7313133.0 | 7.295283e+06 | 8.261189e+06 | 8.996543e+06 | 1.216107e+07 | 1.526446e+07 | 1.395581e+07 | 1.139751e+07 | 1.736144e+07 | 2.546027e+07 | 2.338378e+07 | 2.420630e+07 | 2.255378e+07 | 2.530381e+07 | 2.881064e+07 | 1.958996e+07 |
| прокуратура, полиция и спецслужбы | прокуратура, полиция и спецслужбы | 29356.9 | NaN | NaN | 4.086273e+07 | 5.955347e+07 | 8.714469e+07 | 1.112304e+08 | 1.190517e+08 | 1.188130e+08 | 1.355925e+08 | 1.447262e+08 | 1.695464e+08 | 8.024443e+07 | 7.469808e+07 | 7.097024e+07 | 7.359769e+07 | 8.050007e+07 | 5.685519e+07 |
| промышленность и энергетика | промышленность и энергетика | 374737.2 | 581511.9 | 920630.1 | 1.025631e+06 | 1.291313e+06 | 1.679555e+06 | 2.112708e+06 | 2.495217e+06 | 2.507740e+06 | 2.548311e+06 | 2.392012e+06 | 4.119598e+06 | 1.153400e+07 | 1.049128e+07 | 4.193052e+07 | 3.526767e+07 | 3.388927e+07 | 2.525769e+07 |
| прочие | прочие | 57201.7 | 63374.3 | 70769.9 | 9.653158e+04 | 1.144316e+05 | 1.398355e+05 | 1.666547e+05 | 1.767705e+05 | 1.730455e+05 | 1.679537e+05 | 1.782294e+05 | 2.272292e+05 | 4.200459e+04 | 4.988667e+04 | 5.339083e+04 | 5.631388e+04 | 7.284751e+04 | 4.602101e+04 |
| прочие министерства | прочие министерства | 102794.5 | 170606.0 | NaN | NaN | NaN | NaN | 4.746758e+05 | 9.010814e+05 | 8.974934e+05 | 8.749721e+05 | 8.920889e+05 | 1.951463e+06 | 2.274708e+06 | 2.492276e+06 | 5.389089e+06 | 3.413066e+06 | 3.802542e+06 | 2.572781e+06 |
| связь | связь | 775849.6 | 1007700.0 | 243261.2 | 4.159233e+05 | 4.419006e+05 | 5.578016e+05 | 7.366907e+05 | 1.017874e+06 | 1.062586e+06 | 1.503976e+06 | 1.438637e+07 | 2.216447e+06 | 3.794126e+06 | 4.711565e+06 | 8.426905e+06 | 4.390055e+06 | 3.707722e+06 | 1.053583e+06 |
| сельское хозяйство | сельское хозяйство | 242701.7 | 216446.7 | 400336.1 | 4.992449e+05 | 6.603246e+05 | 1.115254e+06 | 4.911316e+06 | 3.458776e+06 | 3.272414e+06 | 3.271444e+06 | 3.727729e+06 | 7.070989e+06 | 6.109341e+06 | 2.636282e+06 | 2.762238e+06 | 4.253678e+06 | 4.969401e+06 | 2.624879e+06 |
| статистика, стандартизация и архив | статистика, стандартизация и архив | 5428673.4 | 3463846.8 | 4047470.7 | 6.130480e+06 | 9.678373e+06 | 7.989950e+06 | 9.796944e+06 | 1.252393e+07 | 2.076566e+07 | 1.356919e+07 | 1.250955e+07 | 1.375976e+07 | 3.484282e+06 | 3.883531e+06 | 5.191875e+06 | 5.138944e+06 | 4.397301e+06 | 2.012586e+06 |
| суды | суды | 19461752.1 | 25119241.4 | 33012562.4 | 4.236063e+07 | 5.965057e+07 | 7.893130e+07 | 9.276448e+07 | 1.073020e+08 | 1.090315e+08 | 1.170127e+08 | 1.206795e+08 | 1.317020e+08 | 1.437869e+08 | 1.518439e+08 | 1.671576e+08 | 1.726870e+08 | 1.770484e+08 | 1.262668e+08 |
| счетная палата | счетная палата | 514159.2 | 578396.5 | 686709.5 | 1.047412e+06 | 1.106151e+06 | 1.273900e+06 | 1.691962e+06 | 1.817420e+06 | 1.945046e+06 | 1.995006e+06 | 2.159396e+06 | 2.443649e+06 | 2.903754e+06 | 3.565171e+06 | 3.454455e+06 | 3.484411e+06 | 3.780981e+06 | 2.791526e+06 |
| таможня | таможня | 29356.9 | NaN | NaN | 1.952272e+07 | 3.177810e+07 | 5.183096e+07 | 5.701153e+07 | 5.431895e+07 | 5.355175e+07 | 6.228234e+07 | 5.793620e+07 | 6.371512e+07 | 6.195291e+07 | 5.720779e+07 | 5.445615e+07 | 5.600562e+07 | 5.757791e+07 | 4.080228e+07 |
| транспорт | транспорт | 997293.2 | 1259272.4 | 526374.2 | 6.916618e+05 | 9.645825e+05 | 1.386756e+06 | 1.745424e+06 | 2.676544e+06 | 2.677625e+06 | 2.834927e+06 | 3.045155e+06 | 3.773597e+06 | 2.172722e+06 | 2.443524e+06 | 2.937038e+06 | 2.856930e+06 | 3.673195e+06 | 2.140081e+06 |
| тюрьмы | тюрьмы | 33821966.6 | 45644003.1 | 48200940.5 | 4.939072e+06 | 6.193123e+06 | 7.251381e+06 | 1.059864e+07 | 1.989783e+07 | 9.343257e+06 | 1.005613e+07 | 1.879268e+07 | 2.570202e+07 | 9.172114e+05 | 1.345042e+06 | 7.543578e+05 | 7.162469e+05 | 9.785970e+05 | 4.562662e+05 |
| федеральное собрание | федеральное собрание | 2453820.2 | 2629797.7 | 3197238.2 | 4.181236e+06 | 4.659688e+06 | 5.362667e+06 | 6.895839e+06 | 7.361260e+06 | 7.344989e+06 | 7.554316e+06 | 9.326065e+06 | 1.053433e+07 | 1.131073e+07 | 1.242822e+07 | 1.333192e+07 | 1.376513e+07 | 1.475574e+07 | 1.075951e+07 |
| финансы | финансы | 9795825.7 | 12659262.1 | 12562536.2 | 1.846512e+07 | 2.636404e+07 | 3.143353e+07 | 3.908707e+07 | 4.227111e+07 | 4.224021e+07 | 4.577294e+07 | 4.783098e+07 | 4.669822e+07 | 4.723468e+07 | 4.649914e+07 | 5.315978e+07 | 5.486682e+07 | 5.314100e+07 | 3.516734e+07 |
| экология, вода, недра, метеорология | экология, вода, недра, метеорология | 1414479.3 | 1648065.4 | 790980.7 | 1.769120e+06 | 2.288039e+06 | 2.148871e+06 | 2.325598e+06 | 2.668416e+06 | 2.607731e+06 | 3.113915e+06 | 2.991145e+06 | 3.765731e+06 | 2.026427e+06 | 2.593518e+06 | 2.144792e+06 | 2.022290e+06 | 2.086581e+06 | 1.043217e+06 |
| экономика, тарифы, патенты, лицензии | экономика, тарифы, патенты, лицензии | 1097438.7 | 1623486.0 | 1329962.8 | 2.610266e+06 | 2.771028e+06 | 4.104223e+06 | 7.108139e+06 | 8.975361e+06 | 7.927798e+06 | 8.869630e+06 | 9.727466e+06 | 1.045263e+07 | 6.037323e+06 | 8.090558e+06 | 8.451552e+06 | 7.718410e+06 | 8.110111e+06 | 4.289423e+06 |
| ГО ЧС | ГО ЧС | NaN | 179252.0 | 235819.3 | 3.320298e+05 | 7.943606e+05 | 9.523479e+05 | 1.196923e+06 | 1.920132e+06 | 2.167992e+06 | 2.569884e+06 | 2.851141e+06 | 3.595451e+06 | 2.266321e+06 | 2.925800e+06 | 2.474541e+06 | 2.691113e+06 | 2.724423e+06 | 3.500916e+06 |
| занятость | занятость | NaN | NaN | 1770603.2 | 1.932432e+06 | 2.208957e+06 | 1.519598e+06 | 1.871774e+06 | 2.332351e+06 | 2.251716e+06 | 2.253084e+06 | 2.228262e+06 | 2.336381e+06 | 1.148488e+06 | 1.224942e+06 | 1.309529e+06 | 1.352477e+06 | 1.331878e+06 | 6.551340e+05 |
| прочие агентства | прочие агентства | NaN | NaN | NaN | 4.959079e+04 | 8.257997e+04 | 8.007811e+04 | 3.208375e+05 | 1.905577e+06 | 2.141823e+06 | 2.734147e+06 | 2.566841e+06 | 3.105008e+06 | 4.561860e+06 | 5.291365e+06 | 4.921941e+06 | 3.635852e+06 | 3.703932e+06 | 2.351683e+06 |
| судебные приставы | судебные приставы | NaN | NaN | NaN | 2.114784e+07 | 2.847243e+07 | 4.374566e+07 | 5.803671e+07 | 6.700059e+07 | 6.942675e+07 | 7.403237e+07 | 8.238733e+07 | 8.780665e+07 | 5.812453e+07 | 5.460078e+07 | 5.271739e+07 | 5.339494e+07 | 5.971298e+07 | 4.166289e+07 |
| спорт | спорт | NaN | NaN | NaN | NaN | NaN | NaN | 1.449746e+05 | 5.344759e+05 | 4.945119e+05 | 4.737492e+05 | 5.309736e+05 | 8.497661e+05 | 8.696530e+05 | 4.209008e+05 | 3.525698e+05 | 3.390244e+05 | 3.446490e+05 | 1.438859e+05 |
# Эта функция подготовит данные для их загрузки d3.js скрипту для визуализации гонок
def prep_data(df):
lst = []
size = df.shape[0]
for i in range(0, size):
row = df.iloc[i,:]
name = row['name']
#skip first column
row_ = row[1:]
for k, y in enumerate(row_.index):
begin = float(row_[k]) # current year
try:
end = float(row_[k + 1]) # next year
except:
end = float(row_[k])
range_ = end - begin
step = range_ / 10
cur = begin
for n in range(0,10):
last = cur
cur = begin + step * (n+1)
if cur < 0:
cur = 0.0
lst.append({'name': name,
'value': round(cur, 2),
'year': float(str(y) + '.' + str(n)),
'lastValue': round(last, 2),
'rank': 0})
df2 = pd.DataFrame(lst)
df2 = df2.sort_values(by=['year','value'])
df2.reset_index(drop=True, inplace = True)
df2['rank'] = range(1,df2.shape[0]+1)
return df2
# делаем данные
data = prep_data(df5)
data
| name | value | year | lastValue | rank | � |
|---|---|---|---|---|---|
| 0 | ЖКХ | 5.652707e+04 | 2002.0 | 5.511830e+04 | 1 |
| 1 | прочие | 5.781896e+04 | 2002.0 | 5.720170e+04 | 2 |
| 2 | космос | 5.827468e+04 | 2002.0 | 5.697180e+04 | 3 |
| 3 | прочие министерства | 1.095756e+05 | 2002.0 | 1.027945e+05 | 4 |
| 4 | армия | 2.087091e+05 | 2002.0 | 1.994629e+05 | 5 |
| 5 | сельское хозяйство | 2.400762e+05 | 2002.0 | 2.427017e+05 | 6 |
| 6 | культура | 2.449754e+05 | 2002.0 | 2.442861e+05 | 7 |
| 7 | наука и образование | 2.625182e+05 | 2002.0 | 2.567465e+05 | 8 |
| 8 | промышленность и энергетика | 3.954147e+05 | 2002.0 | 3.747372e+05 | 9 |
| 9 | счетная палата | 5.205829e+05 | 2002.0 | 5.141592e+05 | 10 |
| 10 | кадастр и картография | 6.223317e+05 | 2002.0 | 6.048327e+05 | 11 |
| 11 | пенсионный фонд и фонд соцстрахования | 7.584225e+05 | 2002.0 | 7.385676e+05 | 12 |
| 12 | связь | 7.990346e+05 | 2002.0 | 7.758496e+05 | 13 |
| 13 | имущество | 8.090535e+05 | 2002.0 | 7.940961e+05 | 14 |
| 14 | надзор и контроль | 8.734271e+05 | 2002.0 | 8.563408e+05 | 15 |
| 15 | транспорт | 1.023491e+06 | 2002.0 | 9.972932e+05 | 16 |
| 16 | экономика, тарифы, патенты, лицензии | 1.150043e+06 | 2002.0 | 1.097439e+06 | 17 |
| 17 | экология, вода, недра, метеорология | 1.437838e+06 | 2002.0 | 1.414479e+06 | 18 |
| 18 | выборы | 2.349538e+06 | 2002.0 | 1.518662e+06 | 19 |
| 19 | федеральное собрание | 2.471418e+06 | 2002.0 | 2.453820e+06 | 20 |
| ... | ... | ... | ... | ... | ... |
| 6100 | наука и образование | 2.440637e+06 | 2019.9 | 2.440637e+06 | 6101 |
| 6101 | прочие министерства | 2.572781e+06 | 2019.9 | 2.572781e+06 | 6102 |
| 6102 | сельское хозяйство | 2.624879e+06 | 2019.9 | 2.624879e+06 | 6103 |
| 6103 | выборы | 2.636338e+06 | 2019.9 | 2.636338e+06 | 6104 |
| 6104 | счетная палата | 2.791526e+06 | 2019.9 | 2.791526e+06 | 6105 |
| 6105 | ГО ЧС | 3.500916e+06 | 2019.9 | 3.500916e+06 | 6106 |
| 6106 | экономика, тарифы, патенты, лицензии | 4.289423e+06 | 2019.9 | 4.289423e+06 | 6107 |
| 6107 | кадастр и картография | 5.087854e+06 | 2019.9 | 5.087854e+06 | 6108 |
| 6108 | надзор и контроль | 5.261310e+06 | 2019.9 | 5.261310e+06 | 6109 |
| 6109 | федеральное собрание | 1.075951e+07 | 2019.9 | 1.075951e+07 | 6110 |
| 6110 | армия | 1.212784e+07 | 2019.9 | 1.212784e+07 | 6111 |
| 6111 | президент | 1.958996e+07 | 2019.9 | 1.958996e+07 | 6112 |
| 6112 | промышленность и энергетика | 2.525769e+07 | 2019.9 | 2.525769e+07 | 6113 |
| 6113 | пенсионный фонд и фонд соцстрахования | 2.967170e+07 | 2019.9 | 2.967170e+07 | 6114 |
| 6114 | финансы | 3.516734e+07 | 2019.9 | 3.516734e+07 | 6115 |
| 6115 | таможня | 4.080228e+07 | 2019.9 | 4.080228e+07 | 6116 |
| 6116 | судебные приставы | 4.166289e+07 | 2019.9 | 4.166289e+07 | 6117 |
| 6117 | прокуратура, полиция и спецслужбы | 5.685519e+07 | 2019.9 | 5.685519e+07 | 6118 |
| 6118 | налоги | 1.168560e+08 | 2019.9 | 1.168560e+08 | 6119 |
| 6119 | суды | 1.262668e+08 | 2019.9 | 1.262668e+08 | 6120 |
6120 rows × 5 columns
# сохраняем все в csv для загрузки в d3.js
data.to_csv('data_groups.csv', index=False)
Смотрим полученные гонки. Результаты гонки говорят сами за себя.
Тут в html:
You must be registered for see links
Тут видео на youtube:
Спасибо за внимание, добро пожаловать в комментарии.
ССЫЛКИ
Библиотеку prepack можно посмотреть тут:
You must be registered for see links
Собранные бандлы с гонками можно скачать по ссылкам выше, но можно тут:
You must be registered for see links