


Оффлайн
- Регистрация
- 14.05.16
- Сообщения
- 11.396
- Реакции
- 501
- Репутация
- 0
Привет, Хабр! Представляю вашему вниманию перевод статьи
Веб-страницы являются ценным источником информации для многих задач обработки естественного языка и поиска информации. Эффективное извлечение основного содержимого из этих документов имеет важное значение для производительности производных приложений. Чтобы решить эту проблему, мы представляем новую модель, которая выполняет классификацию и маркировку текстовых блоков на странице HTML как шаблонных блоков, или блоков содержащих основной контент. Наш метод использует Скрытую Марковскую модель поверх потенциалов, полученных из признаков объектной модели HTML-документа (Document Object Model, DOM) с использованием сверточных нейронных сетей (Convolutional Neural Network, CNN). Предложенный метод качественно повышает производительность для извлечения текстовых данных из веб-страниц.
1. Введение
Современные методы обработки естественного языка и поиска информации сильно зависят от больших коллекций текста. Всемирная паутина — неиссякаемый источник контента для таких приложений. Тем не менее, общая проблема заключается в том, что веб-страницы включают в себя не только основной контент (текст), но также рекламу, списки гиперссылок, навигацию, превью других статей, баннеры и т.д. Этот шаблонный контент часто оказывает негативное влияние на производительность производного приложения [15,24]. Задача отделения основного текста на веб-странице от остального (шаблонного) содержимого в литературе известна как «удаление стандартного шаблона», «сегментация веб-страницы» или «извлечение содержимого». Известные популярные методы для этой проблемы используют алгоритмы на основе правил или машинного обучения. Наиболее успешные подходы сначала выполняют разбиение входной веб-страницы на текстовые блоки, а затем двоичную {1, 0} маркировку каждого блока в качестве основного содержимого или шаблона. В этой статье мы предлагаем Скрытую Марковскую модель поверх нейронных потенциалов для задачи удаления шаблонов. Мы используем способность сверточных нейронных сетей для изучения унарных и парных потенциалов по блокам на основе сложных нелинейных комбинаций признаков на основе DOM. Во время прогнозирования мы находим наиболее вероятную метку блока {1, 0}, максимизируя совместную вероятность последовательности меток с использованием алгоритма Витерби [23]. Эффективность нашего метода продемонстрирована на стандартных наборах сравнительных данных.
Остальная часть этого документа структурирована следующим образом. Раздел 2 дает обзор связанных с тематикой работ различных авторов. Раздел 3 формально определяет проблему извлечения основного контента, описывает процедуру сегментации блоков данных и детализирует нашу модель. Раздел 4 демонстрирует достоинства нашего метода на нескольких эталонных наборах данных для извлечения контента из веб-страниц.
2. Обзор связанных работ
Ранние подходы к удалению шаблонного HTML-кода используют ряд эвристических и основанных на правилах методов [7] под названием Body Text Extractor (BTE). BTE основан на наблюдении, что основной контент содержит более длинные абзацы непрерывного текста, где HTML-теги встречаются реже по сравнению с остальной частью веб-страницы. Рассматривая совокупное распределение тегов в зависимости от позиции в документе, BTE идентифицирует плоскую область в середине этого графика распределения, чтобы предсказать основное содержимое страницы. Несмотря на простоту, этот алгоритм имеет два недостатка: (1) он использует только местоположение тегов HTML, а не их структуру, тем самым теряя потенциально ценную информацию, и (2) он может идентифицировать только один непрерывный участок основного контента, что нереально для значительного процента современных веб-страниц.
Для решения этих проблем было разработано несколько других алгоритмов для работы с деревьями DOM, что позволяет использовать семантику структуры HTML [11,19,6]. Проблема этих ранних методов заключается в том, что они интенсивно используют тот факт, что страницы раньше были разделены на разделы с помощью тегов
, что больше не является допустимым предположением.
На следующем этапе работы структура DOM используется для совместной обработки нескольких страниц из одного домена с учетом их структурного сходства. Этот подход был впервые предложен Юи и соавт. [24] и был улучшен различными другими авторами [22]. Эти методы очень подходят для обнаружения содержимого шаблона, присутствующего на всех страницах веб-сайта, но имеют низкую производительность на веб-сайтах, которые состоят только из одной веб-страницы. В этой статье мы сосредоточимся на извлечении одностраничного контента без использования контекста других страниц того же сайта.
Готтрон и соавт. [10] предлагают методы сглаживания кода контента, которые могут идентифицировать несколько областей контента. Эти методы анализируют исходный код HTML как вектор единиц, представляющих фрагменты текста, и нулей, представляющих теги. Затем этот вектор итеративно сглаживается, так что в конечном итоге он находит активные области, где доминирует текст (контент), и неактивные области, где доминируют теги (шаблон). Эта идея сглаживания была распространена также на структуру DOM [4,21]. Чакрабарти и соавт. [3] назначают вероятность содержания для каждого листа дерева DOM, используя изотоническое сглаживание, чтобы объединить вероятности меток соседей с теми же родителями. В аналогичном направлении Сан и соавт. [21] использует как соотношение тегов / текста, так и информацию о дереве DOM для распространения сумм плотности вероятности по дереву.
Методы машинного обучения предлагают удобный способ комбинирования различных показателей «наполненности», автоматически взвешивая созданные вручную признаки в соответствии с их относительной важностью. Система FIASCO от Бауэр и соавт. [2] использует машины опорных векторов (SVM) для классификации HTML-страницы как последовательности блоков, которые генерируются посредством сегментации страницы на основе DOM и представлены лингвистическими, структурными и визуальными признаками. Работы Колшаттер и соавт. [17] также используют SVM для независимой классификации блоков. Споста и соавт. [20] расширяют этот подход, переформулируя проблему классификации как случай маркировки последовательности, где все блоки помечены совместно. Они используют условные случайные поля, чтобы воспользоваться корреляциями между метками соседних блоков контента. Этот метод был самым успешным в конкурсе CleanEval [1].
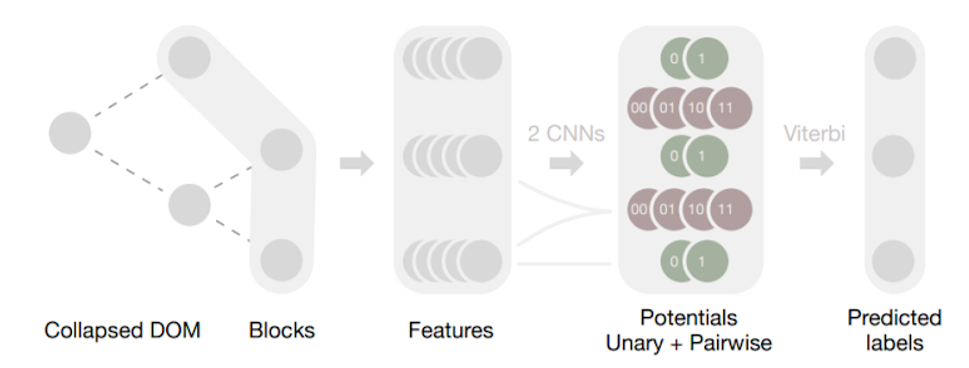 Рис. 1.
Конвейер Web2Text. Листья свернутого дерева DOM (Collapsed DOM) веб-страницы образуют упорядоченную последовательность блоков, которые нужно пометить. Для каждого блока мы извлекаем ряд признаков на основе дерева DOM. Две отдельные сверточные сети, работающие на этой последовательности признаков, дают два соответствующих набора потенциалов: унарные потенциалы для каждого блока и парные потенциалы для каждой пары соседних блоков. Они определяют Скрытую Марковскую модель. Используя алгоритм Витерби, мы находим оптимальную маркировку, которая максимизирует общую вероятность последовательности, предсказанную нейронными сетями.
Рис. 1.
Конвейер Web2Text. Листья свернутого дерева DOM (Collapsed DOM) веб-страницы образуют упорядоченную последовательность блоков, которые нужно пометить. Для каждого блока мы извлекаем ряд признаков на основе дерева DOM. Две отдельные сверточные сети, работающие на этой последовательности признаков, дают два соответствующих набора потенциалов: унарные потенциалы для каждого блока и парные потенциалы для каждой пары соседних блоков. Они определяют Скрытую Марковскую модель. Используя алгоритм Витерби, мы находим оптимальную маркировку, которая максимизирует общую вероятность последовательности, предсказанную нейронными сетями.
В этой статье мы предлагаем эффективный метод получения признаков, которые собираются от ближайших соседей в дереве DOM. Кроме того, мы используем систему глубокого обучения для автоматического изучения комбинаций нелинейных функций, что дает модели преимущество перед традиционными линейными подходами. Наконец, мы совместно оптимизируем метки для всей веб-страницы в соответствии с локальными потенциалами, предсказанными нейронными сетями.
3. Веб в текст
Удаление шаблонов — это проблема маркировки разделов текста веб-страницы как основного содержимого или шаблонного элемента (чего-либо еще) [1]. Далее мы обсудим различные этапы нашего метода. Полный конвейер также показан на рисунке 1.
3.1. Предварительная обработка
Мы ожидаем, что ввод исходной веб-страницы будет записан в (X) HTML-разметке. Каждый документ анализируется как дерево объектной модели документа (дерево DOM) с помощью Jsoup [12].
 Рис. 2.
Пример свернутой модели DOM. Слева: исходный код HTML, посередине — соответствующее дерево DOM, справа — соответствующий свернутый DOM.
Рис. 2.
Пример свернутой модели DOM. Слева: исходный код HTML, посередине — соответствующее дерево DOM, справа — соответствующий свернутый DOM.
Мы предварительно обрабатываем это дерево DOM, i) удаляя пустые узлы или узлы, содержащие только пробелы, ii) удаляя узлы, которые не имеют никакого содержимого, которое мы можем извлечь: например,
, , , ,
You must be registered for see links
коллектива авторов Thijs Vogels, Octavian-Eugen Ganea и Carsten Eickhof.Веб-страницы являются ценным источником информации для многих задач обработки естественного языка и поиска информации. Эффективное извлечение основного содержимого из этих документов имеет важное значение для производительности производных приложений. Чтобы решить эту проблему, мы представляем новую модель, которая выполняет классификацию и маркировку текстовых блоков на странице HTML как шаблонных блоков, или блоков содержащих основной контент. Наш метод использует Скрытую Марковскую модель поверх потенциалов, полученных из признаков объектной модели HTML-документа (Document Object Model, DOM) с использованием сверточных нейронных сетей (Convolutional Neural Network, CNN). Предложенный метод качественно повышает производительность для извлечения текстовых данных из веб-страниц.
1. Введение
Современные методы обработки естественного языка и поиска информации сильно зависят от больших коллекций текста. Всемирная паутина — неиссякаемый источник контента для таких приложений. Тем не менее, общая проблема заключается в том, что веб-страницы включают в себя не только основной контент (текст), но также рекламу, списки гиперссылок, навигацию, превью других статей, баннеры и т.д. Этот шаблонный контент часто оказывает негативное влияние на производительность производного приложения [15,24]. Задача отделения основного текста на веб-странице от остального (шаблонного) содержимого в литературе известна как «удаление стандартного шаблона», «сегментация веб-страницы» или «извлечение содержимого». Известные популярные методы для этой проблемы используют алгоритмы на основе правил или машинного обучения. Наиболее успешные подходы сначала выполняют разбиение входной веб-страницы на текстовые блоки, а затем двоичную {1, 0} маркировку каждого блока в качестве основного содержимого или шаблона. В этой статье мы предлагаем Скрытую Марковскую модель поверх нейронных потенциалов для задачи удаления шаблонов. Мы используем способность сверточных нейронных сетей для изучения унарных и парных потенциалов по блокам на основе сложных нелинейных комбинаций признаков на основе DOM. Во время прогнозирования мы находим наиболее вероятную метку блока {1, 0}, максимизируя совместную вероятность последовательности меток с использованием алгоритма Витерби [23]. Эффективность нашего метода продемонстрирована на стандартных наборах сравнительных данных.
Остальная часть этого документа структурирована следующим образом. Раздел 2 дает обзор связанных с тематикой работ различных авторов. Раздел 3 формально определяет проблему извлечения основного контента, описывает процедуру сегментации блоков данных и детализирует нашу модель. Раздел 4 демонстрирует достоинства нашего метода на нескольких эталонных наборах данных для извлечения контента из веб-страниц.
2. Обзор связанных работ
Ранние подходы к удалению шаблонного HTML-кода используют ряд эвристических и основанных на правилах методов [7] под названием Body Text Extractor (BTE). BTE основан на наблюдении, что основной контент содержит более длинные абзацы непрерывного текста, где HTML-теги встречаются реже по сравнению с остальной частью веб-страницы. Рассматривая совокупное распределение тегов в зависимости от позиции в документе, BTE идентифицирует плоскую область в середине этого графика распределения, чтобы предсказать основное содержимое страницы. Несмотря на простоту, этот алгоритм имеет два недостатка: (1) он использует только местоположение тегов HTML, а не их структуру, тем самым теряя потенциально ценную информацию, и (2) он может идентифицировать только один непрерывный участок основного контента, что нереально для значительного процента современных веб-страниц.
Для решения этих проблем было разработано несколько других алгоритмов для работы с деревьями DOM, что позволяет использовать семантику структуры HTML [11,19,6]. Проблема этих ранних методов заключается в том, что они интенсивно используют тот факт, что страницы раньше были разделены на разделы с помощью тегов
На следующем этапе работы структура DOM используется для совместной обработки нескольких страниц из одного домена с учетом их структурного сходства. Этот подход был впервые предложен Юи и соавт. [24] и был улучшен различными другими авторами [22]. Эти методы очень подходят для обнаружения содержимого шаблона, присутствующего на всех страницах веб-сайта, но имеют низкую производительность на веб-сайтах, которые состоят только из одной веб-страницы. В этой статье мы сосредоточимся на извлечении одностраничного контента без использования контекста других страниц того же сайта.
Готтрон и соавт. [10] предлагают методы сглаживания кода контента, которые могут идентифицировать несколько областей контента. Эти методы анализируют исходный код HTML как вектор единиц, представляющих фрагменты текста, и нулей, представляющих теги. Затем этот вектор итеративно сглаживается, так что в конечном итоге он находит активные области, где доминирует текст (контент), и неактивные области, где доминируют теги (шаблон). Эта идея сглаживания была распространена также на структуру DOM [4,21]. Чакрабарти и соавт. [3] назначают вероятность содержания для каждого листа дерева DOM, используя изотоническое сглаживание, чтобы объединить вероятности меток соседей с теми же родителями. В аналогичном направлении Сан и соавт. [21] использует как соотношение тегов / текста, так и информацию о дереве DOM для распространения сумм плотности вероятности по дереву.
Методы машинного обучения предлагают удобный способ комбинирования различных показателей «наполненности», автоматически взвешивая созданные вручную признаки в соответствии с их относительной важностью. Система FIASCO от Бауэр и соавт. [2] использует машины опорных векторов (SVM) для классификации HTML-страницы как последовательности блоков, которые генерируются посредством сегментации страницы на основе DOM и представлены лингвистическими, структурными и визуальными признаками. Работы Колшаттер и соавт. [17] также используют SVM для независимой классификации блоков. Споста и соавт. [20] расширяют этот подход, переформулируя проблему классификации как случай маркировки последовательности, где все блоки помечены совместно. Они используют условные случайные поля, чтобы воспользоваться корреляциями между метками соседних блоков контента. Этот метод был самым успешным в конкурсе CleanEval [1].
В этой статье мы предлагаем эффективный метод получения признаков, которые собираются от ближайших соседей в дереве DOM. Кроме того, мы используем систему глубокого обучения для автоматического изучения комбинаций нелинейных функций, что дает модели преимущество перед традиционными линейными подходами. Наконец, мы совместно оптимизируем метки для всей веб-страницы в соответствии с локальными потенциалами, предсказанными нейронными сетями.
3. Веб в текст
Удаление шаблонов — это проблема маркировки разделов текста веб-страницы как основного содержимого или шаблонного элемента (чего-либо еще) [1]. Далее мы обсудим различные этапы нашего метода. Полный конвейер также показан на рисунке 1.
3.1. Предварительная обработка
Мы ожидаем, что ввод исходной веб-страницы будет записан в (X) HTML-разметке. Каждый документ анализируется как дерево объектной модели документа (дерево DOM) с помощью Jsoup [12].
Мы предварительно обрабатываем это дерево DOM, i) удаляя пустые узлы или узлы, содержащие только пробелы, ii) удаляя узлы, которые не имеют никакого содержимого, которое мы можем извлечь: например,
, , , ,