


Оффлайн
- Регистрация
- 14.05.16
- Сообщения
- 11.396
- Реакции
- 501
- Репутация
- 0
Доброго времени суток, друзья! Представляю вашему вниманию любительский перевод оригинальной статьи:
Небольшое предупреждение: часть представленной информации может оказаться не полностью верной в силу течения времени и случайных ошибок автора. В любом случае, любой фидбек будет желательным!
Возможно Вам доводилось встречаться с таким инструментом как FastText для векторизации ваших корпусов текстов, но знали ли вы что FastText так же может заниматься и их классификацией? А может и знали, но знали ли как он это делает? Давайте же посмотрим на него изнутри… в смысле, через экран.
Библиотека FastText, в первую очередь, была разработан командой Facebook для классификации текстов, но так же может быть использована для обучения эмбедингов слов. С того момента, когда FastText стал продуктом доступным для всех 2016 он получил широкое применение по причине хорошей скорости тренировки и отличной работоспособности.
Читая официальную документацию (очень скудная на объяснения), я понял что там содержится достаточно большая часть алгоритмов, которые могут оказаться не совсем прозрачными, поэтому было решено самостоятельно разобраться как все это работает и с чем это едят. Начал я с чтения главной статьи от создателей и быстрого просмотра на Стенфордского курса по глубокому обучению в НЛП. В процессе всего этого удовольствия, вопросов у меня только прибавилось. К примеру: что в курсе лекций Стенфорда и в одной из частей статьи говорят об использовании N-грамм, но не говорят никаких особенностей по их использованию. Так-же, параметры, прописываемые в командной строке включают в себя некий bucket единственные комментарии по которому звучат как «число контейнеров(бакетов)». Как вычисляются эти N-граммы? Не понятно… Остается один вариант, смотреть код на
После просмотра всего добра было выяснено следующее
Введение в модель
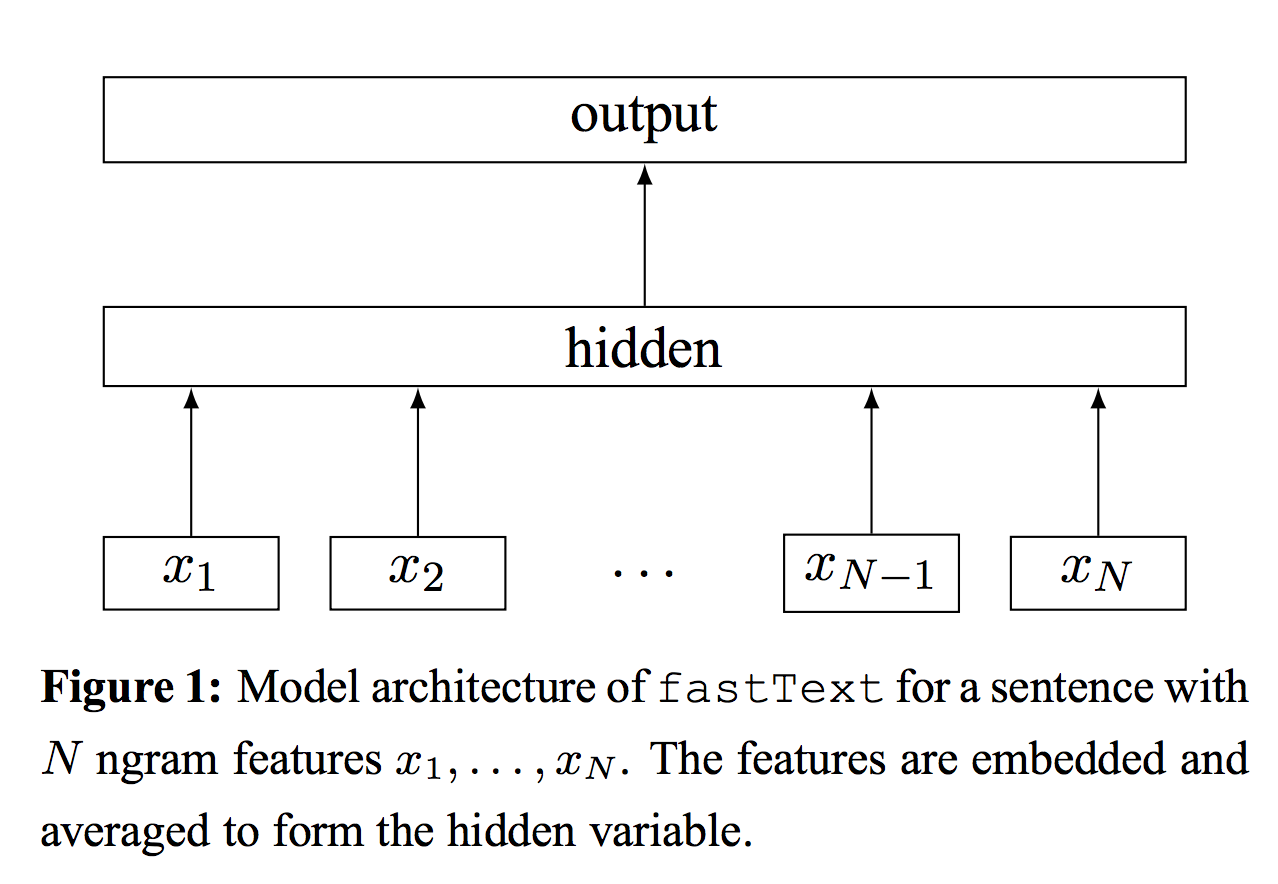
Согласно статье написанной разработчиками, модель представляет из себя простейшую нейронную сеть с одним скрытым слоем. Текст представленный мешком слов (BOW) пропускается через первый слой в котором он трансформируется в эмбединги для каждого слова. В последствии полученные эмбединги осредняются по всему тексту и сводятся к одному единственному который применим по всему тексту. В скрытом слое работаем с n_words * dim числом параметров, где dim это размер эмбеддинга, а n_words размер используемого словаря для текста. После осреднения получаем один единственный вектор который пропускается через довольно популярный классификатор: применяется функция softmax для линого отображения(преобразования) входных данных первого слоя на последний. В качестве линейного преобразования выступает матрица размерностью dim * n_output, где n_output является нашим числом действительных классов. В оригинальной статье конечная вероятность описывается log-likelyhood:

где:
Все в целом не так плохо, но все же давайте взглянем на код:
Код как трансляция идеи
Файл с исходными данными которые мы сможем применить для нашего классификатора должны следовать конкретной форме: __label__0 (текст).
В качестве примеров:
__label__cat This thext is about cats.
__label__dog This text is about dogs.
Исходный файл применяется как аргумент функции train. Функция train стартует с инициализации и послеюущего заполнения переменной dict_.
void FastText::train(const Args args) {
args_ = std::make_shared(args);
dict_ = std::make_shared(args_);
if (args_->input == "-") {
// manage expectations
throw std::invalid_argument("Cannot use stdin for training!");
}
std::ifstream ifs(args_->input);
if (!ifs.is_open()) {
throw std::invalid_argument(
args_->input + " cannot be opened for training!");
}
dict_->readFromFile(ifs);
dict_ является экземпляром класса Dictionary.
Dictionary: ictionary(std::shared_ptr args) : args_(args),
ictionary(std::shared_ptr args) : args_(args),
word2int_(MAX_VOCAB_SIZE, -1), size_(0), nwords_(0), nlabels_(0),
ntokens_(0), pruneidx_size_(-1) {}
После считывания и парсинга предложений исходного файла, мы наполняем два вектора:
Вектор words_ содержит в себе экземпляры entry. Каждый из которых может быть типом word для label и иметь счетчик обращений к ним. Так же тут еще присутствует поле subwords, но его мы рассмотрим чуть дальше.
struct entry {
std::string word;
int64_t count;
entry_type type;
std::vector subwords;
};
Добавляя слова или метки в word2int_ переменную, коллизии обязательно разрешаются таким образом, что мы никогда не обратимся к двум разным словам имеющим одинаковый индекс. Таких попросту не будет.
int32_t Dictionary::find(const std::string& w, uint32_t h) const {
int32_t word2intsize = word2int_.size();
int32_t id = h % word2intsize;
while (word2int_[id] != -1 && words_[word2int_[id]].word != w) {
id = (id + 1) % word2intsize;
}
return id;
}
int32_t Dictionary::find(const std::string& w) const {
return find(w, hash(w));
}
void Dictionary::add(const std::string& w) {
int32_t h = find(w);
ntokens_++;
if (word2int_[h] == -1) {
entry e;
e.word = w;
e.count = 1;
e.type = getType(w);
words_.push_back(e);
word2int_[h] = size_++;
} else {
words_[word2int_[h]].count++;
}
}
Оба вектора фильтруются, дабы убедиться в том что слова и метки, которые упоминаются хотя бы раз, были включены. После переходим к части где используем функцию readFromFile где вызывается initNgrams. Мы почти подобрались к мистике использования N-грамм.
void Dictionary::readFromFile(std::istream& in) {
std::string word;
int64_t minThreshold = 1;
while (readWord(in, word)) {
add(word);
if (ntokens_ % 1000000 == 0 && args_->verbose > 1) {
std::cerr 1000000 0.75 * MAX_VOCAB_SIZE) {
minThreshold++;
threshold(minThreshold, minThreshold);
}
}
threshold(args_->minCount, args_->minCountLabel);
initTableDiscard();
initNgrams();
Функция initNgrams определяет все комбинации N-грамм символов и добавляет их в вектор ngram. В конце концов, обсчитываются все хеши для N-грамм и складываются в векторе ngram, формируя размер bucket. Другими словами, хэши N-грамм символов добавляются после добавления хэшей N-грамм слов. Как следствие их индексы не пересекаются с индексами слов, но могут пересекаться друг с другом.
В целом, для каждого слова в тексте можно предоставить subwords… N-граммы символов.
Матрица эмбеддингов А отображает следующее:
void Dictionary::initNgrams() {
for (size_t i = 0; i < size_; i++) {
std::string word = BOW + words_.word + EOW;
words_.subwords.clear();
words_.subwords.push_back(i);
if (words_.word != EOS) {
computeSubwords(word, words_.subwords);
}
}
}
void Dictionary::computeSubwords(const std::string& word,
std::vector& ngrams) const {
for (size_t i = 0; i < word.size(); i++) {
std::string ngram;
if ((word & 0xC0) == 0x80) continue;
for (size_t j = i, n = 1; j < word.size() && n maxn; n++) {
ngram.push_back(word[j++]);
while (j < word.size() && (word[j] & 0xC0) == 0x80) {
ngram.push_back(word[j++]);
}
if (n >= args_->minn && !(n == 1 && (i == 0 || j == word.size()))) {
int32_t h = hash(ngram) % args_->bucket;
pushHash(ngrams, h);
}
}
}
}
void Dictionary:ushHash(std::vector& hashes, int32_t id) const {
if (pruneidx_size_ == 0 || id < 0) return;
if (pruneidx_size_ > 0) {
if (pruneidx_.count(id)) {
id = pruneidx_.at(id);
} else {
return;
}
}
hashes.push_back(nwords_ + id);
}
Т.о мы разгадали мистичные N-грамм символов. Давайте же разберемся теперь с N-граммами слов.
Возвращаясь к функции train, выполняются следующие инструкции:
if (args_->pretrainedVectors.size() != 0) {
loadVectors(args_->pretrainedVectors);
} else {
input_ = std::make_shared(dict_->nwords()+args_->bucket, args_->dim);
input_->uniform(1.0 / args_->dim);
}
if (args_->model == model_name::sup) {
output_ = std::make_shared(dict_->nlabels(), args_->dim);
} else {
output_ = std::make_shared(dict_->nwords(), args_->dim);
}
output_->zero();
startThreads();
Это то место где инициализируется матрица эмбеддингов А. Нужно указать, что если pretrainedVectors проходят работу с этой функцией, то данная переменная считается наполненой. В случае если такового не случается, то матрица инициализируется случайным числами -1/dim и 1/dim, где dim — размер нашего эмбеддинга. Размерность матрицы А (n_words_ + bucket; dim), т.о. мы собираемся настраивать все эти эмбеддинги для каждого слова. Выходные данные так же инициализируются на этом шаге.
Как итог мы получаем часть где мы начинаем тренировку нашей модели.
void FastText::trainThread(int32_t threadId) {
std::ifstream ifs(args_->input);
utils::seek(ifs, threadId * utils::size(ifs) / args_->thread);
Model model(input_, output_, args_, threadId);
if (args_->model == model_name::sup) {
model.setTargetCounts(dict_->getCounts(entry_type::label));
} else {
model.setTargetCounts(dict_->getCounts(entry_type::word));
}
const int64_t ntokens = dict_->ntokens();
int64_t localTokenCount = 0;
std::vector line, labels;
while (tokenCount_ < args_->epoch * ntokens) {
real progress = real(tokenCount_) / (args_->epoch * ntokens);
real lr = args_->lr * (1.0 - progress);
if (args_->model == model_name::sup) {
localTokenCount += dict_->getLine(ifs, line, labels);
supervised(model, lr, line, labels);
} else if (args_->model == model_name::cbow) {
localTokenCount += dict_->getLine(ifs, line, model.rng);
cbow(model, lr, line);
} else if (args_->model == model_name::sg) {
localTokenCount += dict_->getLine(ifs, line, model.rng);
skipgram(model, lr, line);
}
if (localTokenCount > args_->lrUpdateRate) {
tokenCount_ += localTokenCount;
localTokenCount = 0;
if (threadId == 0 && args_->verbose > 1)
loss_ = model.getLoss();
}
}
if (threadId == 0)
loss_ = model.getLoss();
ifs.close();
}
В данной части когда происходит два главных момента. Первый, функция getLine вызывает переменную dict_. Второй, вызывается функция supervised.
int32_t Dictionary::getLine(std::istream& in,
std::vector& words,
std::vector& labels) const {
std::vector word_hashes;
std::string token;
int32_t ntokens = 0;
reset(in);
words.clear();
labels.clear();
while (readWord(in, token)) {
uint32_t h = hash(token);
int32_t wid = getId(token, h);
entry_type type = wid < 0 ? getType(token) : getType(wid);
ntokens++;
if (type == entry_type::word) {
addSubwords(words, token, wid);
word_hashes.push_back(h);
} else if (type == entry_type::label && wid >= 0) {
labels.push_back(wid - nwords_);
}
if (token == EOS) break;
}
addWordNgrams(words, word_hashes, args_->wordNgrams);
return ntokens;
}
В функции выше, мы читаем тексты из входных данных, определяем индексы для каждого слова друг за другом посредством использования word2int_. Мы добавляем составляющие эти слова N-граммы в переменную words, как указано в коде. И в конце концов мы добавляем метки прямиком в вектор labels.
После полноценного считывания и добавления текста(предложения) прямиком в созданные для них вектора, мы получаем часть кода которая обрабатывает N-граммы. Это функция addWordNgrams.
void Dictionary::addWordNgrams(std::vector& line,
const std::vector& hashes,
int32_t n) const {
for (int32_t i = 0; i < hashes.size(); i++) {
uint64_t h = hashes;
for (int32_t j = i + 1; j < hashes.size() && j < i + n; j++) {
h = h * 116049371 + hashes[j];
pushHash(line, h % args_->bucket);
}
}
}
Смотрим дальше. Переменная hashes представляет собой набор хэшей для каждого слова текста, где line содержит номера слов в предложении и числа используемых N-грамм. Параметр n является параметром wordNgrams и указывает максимальную слину N-граммы слов. Каждая N-грамма слов получает свой собственный хэш высчитанные рекурсивной формулой
$$display$$h = h*116049371+hashes[j]$$display$$
. Данная формула представялет собой
Таким образом, N-граммы слов вычисляются приблизительно так же как и N-граммы символов, но с небольшим отличием, т.к мы не хешируем конкретное слово. Удивительный ход.
После считывания предложения, вызывается функция supervised. В случае если предложение имеет несколько меток, мы случайно выбираем одну из них.
void FastText::supervised(
Model& model,
real lr,
const std::vector& line,
const std::vector& labels) {
if (labels.size() == 0 || line.size() == 0) return;
std::uniform_int_distribution<> uniform(0, labels.size() - 1);
int32_t i = uniform(model.rng);
model.update(line, labels, lr);
}
И на конец, функция обновления модели.
void Model::computeHidden(const std::vector& input, Vector& hidden) const {
assert(hidden.size() == hsz_);
hidden.zero();
for (auto it = input.cbegin(); it != input.cend(); ++it) {
if(quant_) {
hidden.addRow(*qwi_, *it);
} else {
hidden.addRow(*wi_, *it);
}
}
hidden.mul(1.0 / input.size());
}
void Model::update(const std::vector& input, int32_t target, real lr) {
assert(target >= 0);
assert(target < osz_);
if (input.size() == 0) return;
computeHidden(input, hidden_);
if (args_->loss == loss_name::ns) {
loss_ += negativeSampling(target, lr);
} else if (args_->loss == loss_name::hs) {
loss_ += hierarchicalSoftmax(target, lr);
} else {
loss_ += softmax(target, lr);
}
nexamples_ += 1;
if (args_->model == model_name::sup) {
grad_.mul(1.0 / input.size());
}
for (auto it = input.cbegin(); it != input.cend(); ++it) {
wi_->addRow(grad_, *it, 1.0);
}
}
Входные переменные проходящие через функцию supervised имеют список индексов всех своих составляющих (слов, N-грамм слов и символов) предложения. Целью является определение класса на выходе. Функция computeHidden определяет все эмбеддинги для каждого составляющего входных данных посредством поиска их в матрице wi_ и осреднения (суммируется addRow и делится на их размер). После модификации вектора hidden_ отправляем их на активацию в softmax функцию и определяем метку.
Этот участок кода показывает применение функции активации softmax. Так же вычисляется log-loss.
void Model::computeOutputSoftmax(Vector& hidden, Vector& output) const {
if (quant_ && args_->qout) {
output.mul(*qwo_, hidden);
} else {
output.mul(*wo_, hidden);
}
real max = output[0], z = 0.0;
for (int32_t i = 0; i < osz_; i++) {
max = std::max(output, max);
}
for (int32_t i = 0; i < osz_; i++) {
output = exp(output - max);
z += output;
}
for (int32_t i = 0; i < osz_; i++) {
output /= z;
}
}
void Model::computeOutputSoftmax() {
computeOutputSoftmax(hidden_, output_);
}
real Model::softmax(int32_t target, real lr) {
grad_.zero();
computeOutputSoftmax();
for (int32_t i = 0; i < osz_; i++) {
real label = (i == target) ? 1.0 : 0.0;
real alpha = lr * (label - output_);
grad_.addRow(*wo_, i, alpha);
wo_->addRow(hidden_, i, alpha);
}
return -log(output_[target]);
}
Используя данный способ мы не получаем роста размера N-грамм слов и символов. Рост блокируется имеющимся числом buckets.
По умолчанию FastText не использует N-граммы, но нам рекомендуются следующие параметры:
В сумме получаем довольно большое число параметров для обучения
$$display$$(5000000+2000000)*100+(2*100) = 250,000,000$$display$$
. Многовато, не так ли?) Как мы видим даже через такой простой подход мы имеем довольно большое число параметров, что очень даже типично для методов глубокого обучения. Используются очень грубая оценка, как например, число N-грамм взятое за 2_000_000, для того что бы показать порядок. В целом, сложность модели можно понизить путем настройки некоторых гиперпараметров, таких как bucket или же порог взятия выборки.
Некоторые ссылки могут оказаться полезными:
You must be registered for see links
автора Maria Mestre.Небольшое предупреждение: часть представленной информации может оказаться не полностью верной в силу течения времени и случайных ошибок автора. В любом случае, любой фидбек будет желательным!
Возможно Вам доводилось встречаться с таким инструментом как FastText для векторизации ваших корпусов текстов, но знали ли вы что FastText так же может заниматься и их классификацией? А может и знали, но знали ли как он это делает? Давайте же посмотрим на него изнутри… в смысле, через экран.
Библиотека FastText, в первую очередь, была разработан командой Facebook для классификации текстов, но так же может быть использована для обучения эмбедингов слов. С того момента, когда FastText стал продуктом доступным для всех 2016 он получил широкое применение по причине хорошей скорости тренировки и отличной работоспособности.
Читая официальную документацию (очень скудная на объяснения), я понял что там содержится достаточно большая часть алгоритмов, которые могут оказаться не совсем прозрачными, поэтому было решено самостоятельно разобраться как все это работает и с чем это едят. Начал я с чтения главной статьи от создателей и быстрого просмотра на Стенфордского курса по глубокому обучению в НЛП. В процессе всего этого удовольствия, вопросов у меня только прибавилось. К примеру: что в курсе лекций Стенфорда и в одной из частей статьи говорят об использовании N-грамм, но не говорят никаких особенностей по их использованию. Так-же, параметры, прописываемые в командной строке включают в себя некий bucket единственные комментарии по которому звучат как «число контейнеров(бакетов)». Как вычисляются эти N-граммы? Не понятно… Остается один вариант, смотреть код на
You must be registered for see links
.После просмотра всего добра было выяснено следующее
- FastText с уверенностью использует N-граммы символов с тем же успехом как и N-граммы слов.
- FastText поддерживает многоклассовую классификацию, что может оказаться не так уж и очевидно с первого раза
- Число параметров модели
Введение в модель
Согласно статье написанной разработчиками, модель представляет из себя простейшую нейронную сеть с одним скрытым слоем. Текст представленный мешком слов (BOW) пропускается через первый слой в котором он трансформируется в эмбединги для каждого слова. В последствии полученные эмбединги осредняются по всему тексту и сводятся к одному единственному который применим по всему тексту. В скрытом слое работаем с n_words * dim числом параметров, где dim это размер эмбеддинга, а n_words размер используемого словаря для текста. После осреднения получаем один единственный вектор который пропускается через довольно популярный классификатор: применяется функция softmax для линого отображения(преобразования) входных данных первого слоя на последний. В качестве линейного преобразования выступает матрица размерностью dim * n_output, где n_output является нашим числом действительных классов. В оригинальной статье конечная вероятность описывается log-likelyhood:
где:
- x_n это представление слова в n-грамме.
- А это look_up матрица извлекающая эмбеддинг слова.
- В это линейное преобразование выходных данных.
- f непосредственно сама фунция softmax.
Все в целом не так плохо, но все же давайте взглянем на код:
Код как трансляция идеи
Файл с исходными данными которые мы сможем применить для нашего классификатора должны следовать конкретной форме: __label__0 (текст).
В качестве примеров:
__label__cat This thext is about cats.
__label__dog This text is about dogs.
Исходный файл применяется как аргумент функции train. Функция train стартует с инициализации и послеюущего заполнения переменной dict_.
void FastText::train(const Args args) {
args_ = std::make_shared(args);
dict_ = std::make_shared(args_);
if (args_->input == "-") {
// manage expectations
throw std::invalid_argument("Cannot use stdin for training!");
}
std::ifstream ifs(args_->input);
if (!ifs.is_open()) {
throw std::invalid_argument(
args_->input + " cannot be opened for training!");
}
dict_->readFromFile(ifs);
dict_ является экземпляром класса Dictionary.
Dictionary:
ictionary(std::shared_ptr args) : args_(args),word2int_(MAX_VOCAB_SIZE, -1), size_(0), nwords_(0), nlabels_(0),
ntokens_(0), pruneidx_size_(-1) {}
После считывания и парсинга предложений исходного файла, мы наполняем два вектора:
- words_ содержащий уникальные слова извлеченные из текста
- word2int_ содержащий хэши для каждого слова в соответствии с его позицией в векторе words_. Это на самом деле очень важно, так как это определяет, которые будут использованы для поиска эмбеддингов матрицы А
Вектор words_ содержит в себе экземпляры entry. Каждый из которых может быть типом word для label и иметь счетчик обращений к ним. Так же тут еще присутствует поле subwords, но его мы рассмотрим чуть дальше.
struct entry {
std::string word;
int64_t count;
entry_type type;
std::vector subwords;
};
Добавляя слова или метки в word2int_ переменную, коллизии обязательно разрешаются таким образом, что мы никогда не обратимся к двум разным словам имеющим одинаковый индекс. Таких попросту не будет.
int32_t Dictionary::find(const std::string& w, uint32_t h) const {
int32_t word2intsize = word2int_.size();
int32_t id = h % word2intsize;
while (word2int_[id] != -1 && words_[word2int_[id]].word != w) {
id = (id + 1) % word2intsize;
}
return id;
}
int32_t Dictionary::find(const std::string& w) const {
return find(w, hash(w));
}
void Dictionary::add(const std::string& w) {
int32_t h = find(w);
ntokens_++;
if (word2int_[h] == -1) {
entry e;
e.word = w;
e.count = 1;
e.type = getType(w);
words_.push_back(e);
word2int_[h] = size_++;
} else {
words_[word2int_[h]].count++;
}
}
Оба вектора фильтруются, дабы убедиться в том что слова и метки, которые упоминаются хотя бы раз, были включены. После переходим к части где используем функцию readFromFile где вызывается initNgrams. Мы почти подобрались к мистике использования N-грамм.
void Dictionary::readFromFile(std::istream& in) {
std::string word;
int64_t minThreshold = 1;
while (readWord(in, word)) {
add(word);
if (ntokens_ % 1000000 == 0 && args_->verbose > 1) {
std::cerr 1000000 0.75 * MAX_VOCAB_SIZE) {
minThreshold++;
threshold(minThreshold, minThreshold);
}
}
threshold(args_->minCount, args_->minCountLabel);
initTableDiscard();
initNgrams();
Функция initNgrams определяет все комбинации N-грамм символов и добавляет их в вектор ngram. В конце концов, обсчитываются все хеши для N-грамм и складываются в векторе ngram, формируя размер bucket. Другими словами, хэши N-грамм символов добавляются после добавления хэшей N-грамм слов. Как следствие их индексы не пересекаются с индексами слов, но могут пересекаться друг с другом.
В целом, для каждого слова в тексте можно предоставить subwords… N-граммы символов.
Матрица эмбеддингов А отображает следующее:
- Изначальные nwords_ строк содержащие эмбеддинги для каждого слова из имеющегося для текста словаря.
- Последующте bucket строк содержащие в себе эмбеддинги для каждой N-граммы символов
void Dictionary::initNgrams() {
for (size_t i = 0; i < size_; i++) {
std::string word = BOW + words_.word + EOW;
words_.subwords.clear();
words_.subwords.push_back(i);
if (words_.word != EOS) {
computeSubwords(word, words_.subwords);
}
}
}
void Dictionary::computeSubwords(const std::string& word,
std::vector& ngrams) const {
for (size_t i = 0; i < word.size(); i++) {
std::string ngram;
if ((word & 0xC0) == 0x80) continue;
for (size_t j = i, n = 1; j < word.size() && n maxn; n++) {
ngram.push_back(word[j++]);
while (j < word.size() && (word[j] & 0xC0) == 0x80) {
ngram.push_back(word[j++]);
}
if (n >= args_->minn && !(n == 1 && (i == 0 || j == word.size()))) {
int32_t h = hash(ngram) % args_->bucket;
pushHash(ngrams, h);
}
}
}
}
void Dictionary:
ushHash(std::vector& hashes, int32_t id) const {if (pruneidx_size_ == 0 || id < 0) return;
if (pruneidx_size_ > 0) {
if (pruneidx_.count(id)) {
id = pruneidx_.at(id);
} else {
return;
}
}
hashes.push_back(nwords_ + id);
}
Т.о мы разгадали мистичные N-грамм символов. Давайте же разберемся теперь с N-граммами слов.
Возвращаясь к функции train, выполняются следующие инструкции:
if (args_->pretrainedVectors.size() != 0) {
loadVectors(args_->pretrainedVectors);
} else {
input_ = std::make_shared(dict_->nwords()+args_->bucket, args_->dim);
input_->uniform(1.0 / args_->dim);
}
if (args_->model == model_name::sup) {
output_ = std::make_shared(dict_->nlabels(), args_->dim);
} else {
output_ = std::make_shared(dict_->nwords(), args_->dim);
}
output_->zero();
startThreads();
Это то место где инициализируется матрица эмбеддингов А. Нужно указать, что если pretrainedVectors проходят работу с этой функцией, то данная переменная считается наполненой. В случае если такового не случается, то матрица инициализируется случайным числами -1/dim и 1/dim, где dim — размер нашего эмбеддинга. Размерность матрицы А (n_words_ + bucket; dim), т.о. мы собираемся настраивать все эти эмбеддинги для каждого слова. Выходные данные так же инициализируются на этом шаге.
Как итог мы получаем часть где мы начинаем тренировку нашей модели.
void FastText::trainThread(int32_t threadId) {
std::ifstream ifs(args_->input);
utils::seek(ifs, threadId * utils::size(ifs) / args_->thread);
Model model(input_, output_, args_, threadId);
if (args_->model == model_name::sup) {
model.setTargetCounts(dict_->getCounts(entry_type::label));
} else {
model.setTargetCounts(dict_->getCounts(entry_type::word));
}
const int64_t ntokens = dict_->ntokens();
int64_t localTokenCount = 0;
std::vector line, labels;
while (tokenCount_ < args_->epoch * ntokens) {
real progress = real(tokenCount_) / (args_->epoch * ntokens);
real lr = args_->lr * (1.0 - progress);
if (args_->model == model_name::sup) {
localTokenCount += dict_->getLine(ifs, line, labels);
supervised(model, lr, line, labels);
} else if (args_->model == model_name::cbow) {
localTokenCount += dict_->getLine(ifs, line, model.rng);
cbow(model, lr, line);
} else if (args_->model == model_name::sg) {
localTokenCount += dict_->getLine(ifs, line, model.rng);
skipgram(model, lr, line);
}
if (localTokenCount > args_->lrUpdateRate) {
tokenCount_ += localTokenCount;
localTokenCount = 0;
if (threadId == 0 && args_->verbose > 1)
loss_ = model.getLoss();
}
}
if (threadId == 0)
loss_ = model.getLoss();
ifs.close();
}
В данной части когда происходит два главных момента. Первый, функция getLine вызывает переменную dict_. Второй, вызывается функция supervised.
int32_t Dictionary::getLine(std::istream& in,
std::vector& words,
std::vector& labels) const {
std::vector word_hashes;
std::string token;
int32_t ntokens = 0;
reset(in);
words.clear();
labels.clear();
while (readWord(in, token)) {
uint32_t h = hash(token);
int32_t wid = getId(token, h);
entry_type type = wid < 0 ? getType(token) : getType(wid);
ntokens++;
if (type == entry_type::word) {
addSubwords(words, token, wid);
word_hashes.push_back(h);
} else if (type == entry_type::label && wid >= 0) {
labels.push_back(wid - nwords_);
}
if (token == EOS) break;
}
addWordNgrams(words, word_hashes, args_->wordNgrams);
return ntokens;
}
В функции выше, мы читаем тексты из входных данных, определяем индексы для каждого слова друг за другом посредством использования word2int_. Мы добавляем составляющие эти слова N-граммы в переменную words, как указано в коде. И в конце концов мы добавляем метки прямиком в вектор labels.
После полноценного считывания и добавления текста(предложения) прямиком в созданные для них вектора, мы получаем часть кода которая обрабатывает N-граммы. Это функция addWordNgrams.
void Dictionary::addWordNgrams(std::vector& line,
const std::vector& hashes,
int32_t n) const {
for (int32_t i = 0; i < hashes.size(); i++) {
uint64_t h = hashes;
for (int32_t j = i + 1; j < hashes.size() && j < i + n; j++) {
h = h * 116049371 + hashes[j];
pushHash(line, h % args_->bucket);
}
}
}
Смотрим дальше. Переменная hashes представляет собой набор хэшей для каждого слова текста, где line содержит номера слов в предложении и числа используемых N-грамм. Параметр n является параметром wordNgrams и указывает максимальную слину N-граммы слов. Каждая N-грамма слов получает свой собственный хэш высчитанные рекурсивной формулой
$$display$$h = h*116049371+hashes[j]$$display$$
. Данная формула представялет собой
You must be registered for see links
хеширования применяемого к строке: он берет хэш каждого слова в N-грамме слов и складывает их. Таким образом получается набор уникальных хэшей. В итоге, это значение (может оказаться довольно большим) передается по модулю.Таким образом, N-граммы слов вычисляются приблизительно так же как и N-граммы символов, но с небольшим отличием, т.к мы не хешируем конкретное слово. Удивительный ход.
После считывания предложения, вызывается функция supervised. В случае если предложение имеет несколько меток, мы случайно выбираем одну из них.
void FastText::supervised(
Model& model,
real lr,
const std::vector& line,
const std::vector& labels) {
if (labels.size() == 0 || line.size() == 0) return;
std::uniform_int_distribution<> uniform(0, labels.size() - 1);
int32_t i = uniform(model.rng);
model.update(line, labels, lr);
}
И на конец, функция обновления модели.
void Model::computeHidden(const std::vector& input, Vector& hidden) const {
assert(hidden.size() == hsz_);
hidden.zero();
for (auto it = input.cbegin(); it != input.cend(); ++it) {
if(quant_) {
hidden.addRow(*qwi_, *it);
} else {
hidden.addRow(*wi_, *it);
}
}
hidden.mul(1.0 / input.size());
}
void Model::update(const std::vector& input, int32_t target, real lr) {
assert(target >= 0);
assert(target < osz_);
if (input.size() == 0) return;
computeHidden(input, hidden_);
if (args_->loss == loss_name::ns) {
loss_ += negativeSampling(target, lr);
} else if (args_->loss == loss_name::hs) {
loss_ += hierarchicalSoftmax(target, lr);
} else {
loss_ += softmax(target, lr);
}
nexamples_ += 1;
if (args_->model == model_name::sup) {
grad_.mul(1.0 / input.size());
}
for (auto it = input.cbegin(); it != input.cend(); ++it) {
wi_->addRow(grad_, *it, 1.0);
}
}
Входные переменные проходящие через функцию supervised имеют список индексов всех своих составляющих (слов, N-грамм слов и символов) предложения. Целью является определение класса на выходе. Функция computeHidden определяет все эмбеддинги для каждого составляющего входных данных посредством поиска их в матрице wi_ и осреднения (суммируется addRow и делится на их размер). После модификации вектора hidden_ отправляем их на активацию в softmax функцию и определяем метку.
Этот участок кода показывает применение функции активации softmax. Так же вычисляется log-loss.
void Model::computeOutputSoftmax(Vector& hidden, Vector& output) const {
if (quant_ && args_->qout) {
output.mul(*qwo_, hidden);
} else {
output.mul(*wo_, hidden);
}
real max = output[0], z = 0.0;
for (int32_t i = 0; i < osz_; i++) {
max = std::max(output, max);
}
for (int32_t i = 0; i < osz_; i++) {
output = exp(output - max);
z += output;
}
for (int32_t i = 0; i < osz_; i++) {
output /= z;
}
}
void Model::computeOutputSoftmax() {
computeOutputSoftmax(hidden_, output_);
}
real Model::softmax(int32_t target, real lr) {
grad_.zero();
computeOutputSoftmax();
for (int32_t i = 0; i < osz_; i++) {
real label = (i == target) ? 1.0 : 0.0;
real alpha = lr * (label - output_);
grad_.addRow(*wo_, i, alpha);
wo_->addRow(hidden_, i, alpha);
}
return -log(output_[target]);
}
Используя данный способ мы не получаем роста размера N-грамм слов и символов. Рост блокируется имеющимся числом buckets.
По умолчанию FastText не использует N-граммы, но нам рекомендуются следующие параметры:
- bucker = 2000000; wordNgrams > 1 или maxn > 0
- dim=100
- n_output=2
- n_words=500000
В сумме получаем довольно большое число параметров для обучения
$$display$$(5000000+2000000)*100+(2*100) = 250,000,000$$display$$
. Многовато, не так ли?) Как мы видим даже через такой простой подход мы имеем довольно большое число параметров, что очень даже типично для методов глубокого обучения. Используются очень грубая оценка, как например, число N-грамм взятое за 2_000_000, для того что бы показать порядок. В целом, сложность модели можно понизить путем настройки некоторых гиперпараметров, таких как bucket или же порог взятия выборки.
Некоторые ссылки могут оказаться полезными:
You must be registered for see links
You must be registered for see links
and
You must be registered for see links
You must be registered for see links
(from 47:39)